

0. 概要
해시스크래퍼の顧客事例の1つとして、AIモデルを使用して工場での不良率を低下させるためにAIモデルを使用しました。機械学習モデルの予測をより深く理解しやすく説明するために、この記事を作成しました。
1. 問題の定義
1.1. 目標設定
まず、顧客事例を簡単に説明すると、128の変数に基づいて、各機械ごとに不良率に差があり、機械学習モデルを使用して不良品を予測し、機械学習モデルを使用してどの変数が不良を引き起こしたかを分析し、それらの変数を調整して不良率を低下させることが目標でした。
1.2. 仮説設定
工程プロセスで機械学習モデルを使用して主要な変数を抽出して調整すると、工程率が低下するという仮説を立てました。
2. データ収集
2.1. データソースの決定
データソースは、お客様が工場から直接各機械のデータを提供してくれました。
このデータは会社内データなので直接公開することは難しく、フォルダーのキャプチャーのみ表示しています。
2.2. データ収集
必要なデータは最低1万件をリクエストし、できるだけ多くのデータを提供してもらいたいとお願いしました。その結果、受け取った生データは、1号機が3931件、2号機が16473件、3号機が2072件、4号機が16129件、5号機が57970件、6号機が78781件です。合計約17万5千件のデータを使用してモデルを学習しました。
3. データ前処理
3.3. データのクリーニング
モデルを学習する際にデータのクリーニングは非常に重要です。機械学習を通じたデータ学習の8割以上がクリーニングだと思います。クリーニングされていないデータを学習させると、結局機械学習もうまく学習されないモデルが出ます(簡単に言うと、ゴミを入れればゴミが出ると考えていただければと思います)。
3.4. 作業手順
3.4.1.
まずファイルを読み込む際、csvを読み込む際にエンコーディング形式が異なるため、一部は 'cp949' 、一部は 'utf-8' でエンコードして読み込みました。
for file_path in file_paths:
try:
df = pd.read_csv(file_path, encoding='cp949', header=None)
except UnicodeDecodeError:
df = pd.read_csv(file_path, encoding='utf-8', header=None)
3.4.2.
ラベリングを行うために、日付と時間の列を結合し、その時間に関連するy軸データを結合します。
for i in range(len(result_df_new) - 1):
start_time, end_time = result_df_new['Datetime'].iloc[i], result_df_new['Datetime'].iloc[i + 1]
selected_rows = df_yaxis[(df_yaxis['Datetime'] >= start_time) & (df_yaxis['Datetime'] < end_time)]
results.append(1 if all(selected_rows['결과'].str.contains('OK')) else 0)
results.append(0)
3.4.3.
各機械ごとに前処理されたデータを結合します。
data = pd.concat([df1,df2,df3,df4,df6])
data.reset_index(drop=True,inplace=True)
3.4.4
重複するデータはデータセットに偏りをもたらす可能性があり、モデルがデータの多様性を学習する際に問題が発生する可能性があります。また、過学習の問題も発生する可能性があるため、重複データはすべて削除します。
data = data.drop_duplicates().reset_index(drop=True)
このような前処理を行った後、ある程度のEDAを行いました。
3.4.5.
missingnoライブラリを使用して欠損値を視覚化しました。そして、欠損値が多い列は完全に削除しました。欠損値が多い列を削除する理由は、前述と似た理由です。データの多様性を学習する際に問題があり、過学習の問題が発生する可能性があります。もちろん、データに対して欠損値も重要な値になることがあります。これは分析するデータによって異なる可能性があります。
3.5. フィーチャーエンジニアリング
モデルのパフォーマンスを向上させるために、新しいフィーチャーを作成したり、既存のフィーチャーを変更することがフィーチャーエンジニアリングと呼ばれますが、私たちは各フィーチャーの値を正確に把握しておらず、すべてのフィーチャー値が重要だと考えたため、フィーチャーエンジニアリングは行いませんでした。
3.6. EDA(以下のキャプチャー画像はセキュリティ上の理由で一部のみ表示されています)
データ分布の確認
ヒストグラム、ボックスプロットなどのグラフを使用してデータの分布を確認します。
.png?table=block&id=74533625-35d7-4939-96b3-60c4b3763ea6&cache=v2)

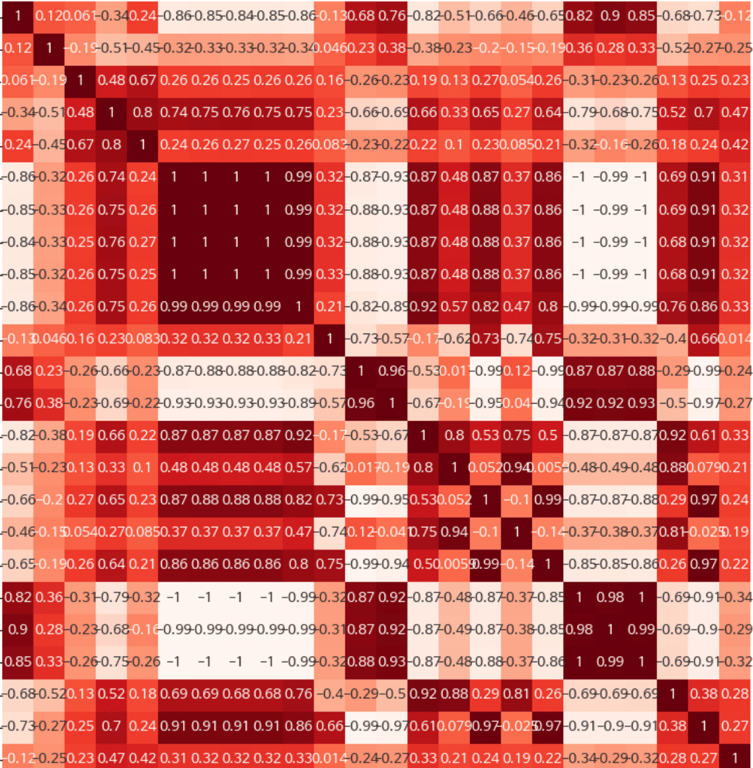
相関関係の分析
フィーチャー間の相関関係を分析して重要なフィーチャーを把握したり、多重共線性の問題を解決します。
4. サンプリングタイプ
4.1. データの不均衡度
データが非常に不均衡であったため、複数のモデルと組み合わせるためにアンダーサンプリングを試みました。不均衡度が高い場合、アンダーサンプリングを行う理由は、過学習の問題が最も大きいためです。モデルが学習する際に、どのデータにも偏らず学習することを最大の目標としました。Random Under-sampling (RUS): 多数クラスからランダムにデータを削除してクラスの不均衡を解消します。単純で迅速に実装できますが、重要な情報が失われるリスクがあります。
4.2. NearMiss
少数クラスのデータと最も近いk個の多数クラスのデータのみを保持する方法です。NearMissには複数のバージョンがあり、各バージョンごとに少数クラスのデータとの距離を計算する方法がわずかに異なります。
4.3. Tomek Links
少数クラスと多数クラスのデータのペアの中で、お互いに最も近いデータペアを見つけ、多数クラスのデータを削除します。これにより、クラス間の境界が明確になります。
4.4. Edited Nearest Neighbors (ENN)
すべての多数クラスデータに対してk-NNアルゴリズムを使用し、多数の最近傍が少数クラスに属する場合はそのデータを削除します。
4.5. Neighbourhood Cleaning Rule (NCL)
ENNの拡張バージョンであり、より効果的に多数クラスのデータを削除して少数クラスの周囲の領域をきれいにします。
このようなアンダーサンプリングも試みましたが、アンダーサンプリングとオーバーサンプリングを組み合わせても試してみました。しかし、モデルに最も適したものはENNアンダーサンプリングだと判断され、ENNを適用しました。
##### NearMiss 인스턴스 생성
nm = NearMiss()
##### 언더샘플링 수행
X_resampled, y_resampled = nm.fit_resample(data.drop('결과', axis=1), data['결과'])
##### 언더샘플링 결과를 DataFrame으로 변환
data_sample = pd.concat([X_resampled, y_resampled], axis=1)
5. モデリング
5.1. モデル選択
問題のタイプ(分類、回帰、クラスタリングなど)に応じて適切な機械学習モデルを選択します。
モデル選択では、直接複数のモデルを実行することもありましたが、pycratライブラリを使用して
bestで選ばれるモデルを参考にしてモデルを選択しました。PyCaretはPythonのオープンソースデータ分析および機械学習自動化ライブラリです。PyCaretはユーザーに少ないコード量で全体のデータ分析および機械学習パイプラインを迅速に構築し、実験する能力を提供します。
5.2. モデルトレーニング
学習データを使用してモデルをトレーニングします。
最終的には、catboostモデルを使用してAUC値とf1スコア値が最も高くなりました。
- AUC(曲線下面積):
AUCはROC(受信者動作特性)曲線の下の面積を意味します。
ROC曲線は感度(真陽性率)をy軸に、1-特異度(偽陽性率)をx軸に配置して描かれます。
AUC値は0から1の間にあり、値が1に近いほど分類器のパフォーマンスが良いと判断されます。一方、0.5はランダム分類のパフォーマンスと同じです。
AUCは不均衡なクラス分布で特に有用です。
- F1スコア:
F1スコアは適合率(Precision)と再現率(Recall)の調和平均です。
適合率は陽性と予測されたもののうち、実際の陽性の割合であり、再現率は実際の陽性のうち、正しく陽性と予測された割合です。
F1スコアは2つの指標のバランスを示すため、どちらか一方だけを最適化するモデルの限界を克服するために使用されます。
F1スコアの値は0から1の間にあり、値が高いほどモデルのパフォーマンスが良いと判断されます。
6. 結論: 変数の抽出と直感性を高めた機能の追加
最終的には、工場にある機械が生成する生データをリアルタイムで取得し、このモデルを使用して予測し、SHAPライブラリを使用して不良品に関連する変数を抽出しました。
また、工場で作業する一般の方々のために、この一連のプロセスでExcelファイルが最終的に出力され、簡単に表示できるようにし、exeファイルを生成してクリックするだけでその生データに関する変数と不良品かどうかを判断できるようにExcelで表示しました。
** SHAPとは?
SHAPはSHapley Additive exPlanationsの略で、機械学習モデルの各フィーチャーが予測にどれだけ影響を与えたかを説明するために使用されるツールです。これにより、モデルの '透明性' を高め、それによって予測がどのように行われたかに対する信頼性を向上させることができます。
ハッシュスクレイパーは上記のようなケースで、前述の方法に基づいたAIモデルを使用してプロジェクトを進行しています。



