

1. Google 検索コンソールで問題点を確認
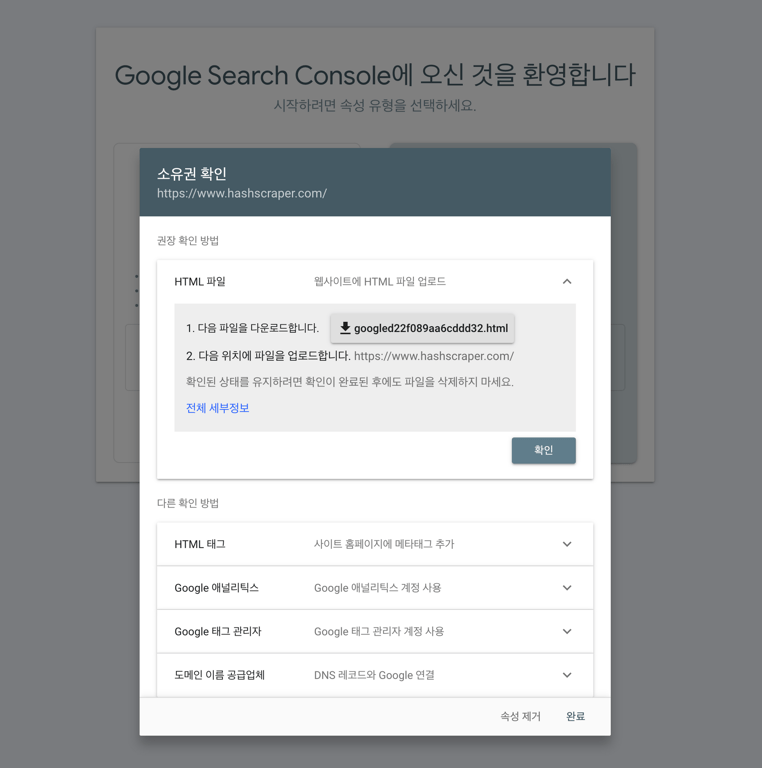
ドメイン確認後、クローリングボットがクローリングを開始した後、データが表示されるため、数日後に再度アクセスしていただくとデータが表示されるはずです。
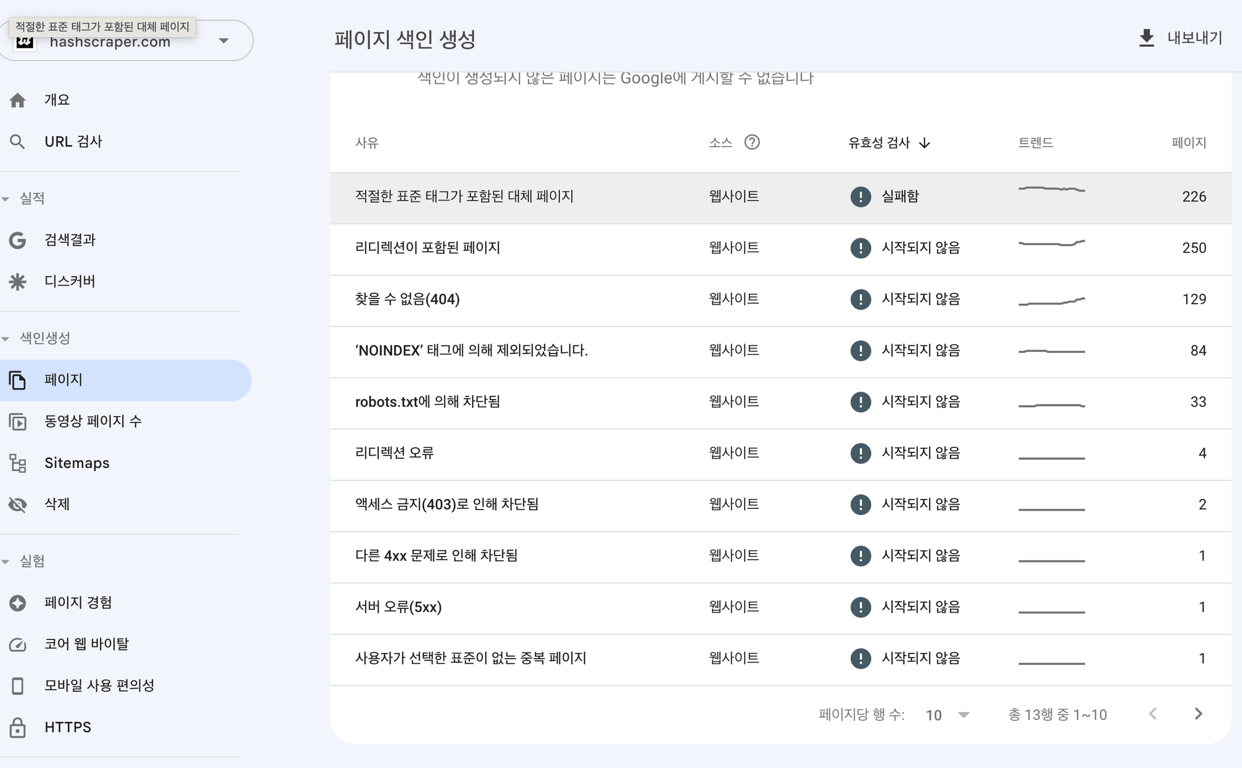
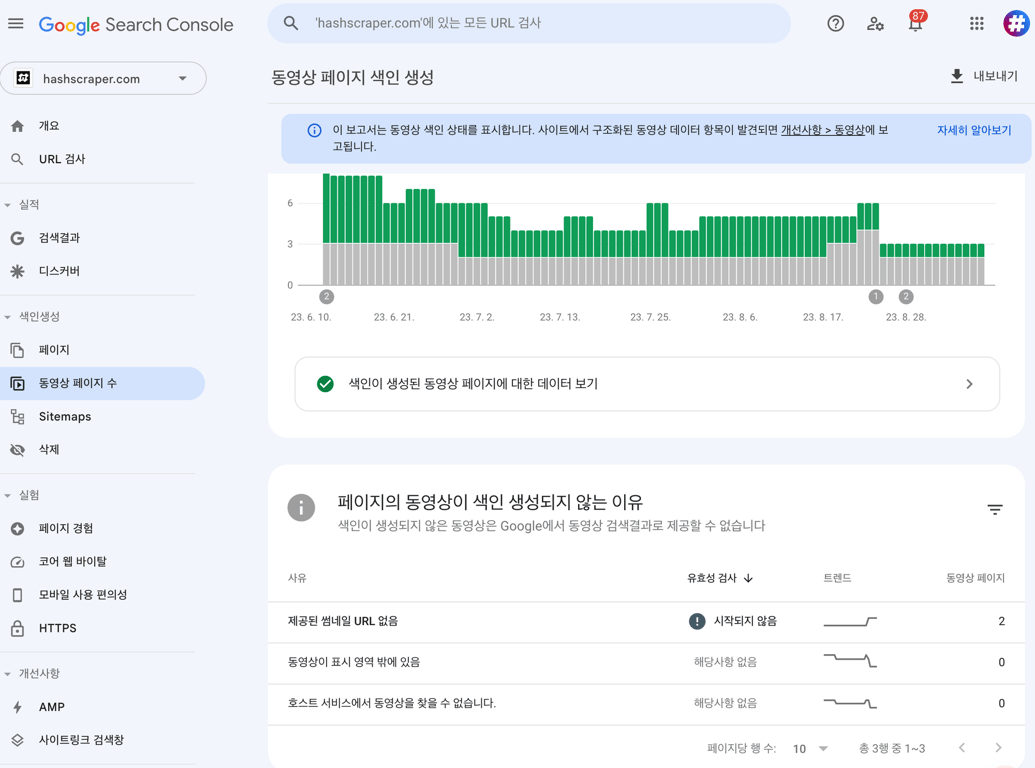
クローリング時に問題となる一般的なエラーは次のとおりです。
- タイムアウト
- 接続が拒否されました
- 接続に失敗しました
- 接続タイムアウト
- 応答がありません
ほとんどの場合、サーバーエラーは一時的なものがほとんどですが、エラーが継続する場合はサーバーに問題があるかどうかを確認し、
時折、ホスティングプロバイダーのエラーが発生する可能性があるので、ホスティングプロバイダーにお問い合わせください
robots.txtファイルが200または404エラーを返す場合、検索エンジンはこのファイルを検索するのに問題があることを示しています。
robots.txtサイトマップをエラーなく作成して提出するか、サーバーサイドでボットに対するブロックが行われているか確認する必要があります。
2. Sitemap作成
クローラーが最初に確認するのはホームページにあるサイトマップを参照してクローリングを開始します。
エラーのないサイトマップをうまく作成することで、ボットがクローリングしやすくなります。
3. 定期的に新しいコンテンツを更新
定期的に新しいコンテンツを制作すると、検索エンジンがサイトをより頻繁にクローリングするようになります。
4. モバイルフレンドリーサイトを作成
モバイルファーストインデックスが導入されたため、モバイルに最適化されたページを作成する必要があります。
モバイルに最適化されていない場合、ランキングが低下する可能性があります。
以下はモバイルフレンドリーサイトを作成する代表的な方法です。
a. レスポンシブWebデザインの実装
b. コンテンツにビューポイントメタタグの挿入
c. ページ内リソース(CSSおよびJS)の最小化
d. AMPキャッシュでページをタグ指定
e. ロード時間を短縮するための画像最適化
f. ページ内UI要素のサイズを縮小する
モバイルプラットフォームでウェブサイトをテストし、Google PageSpeedを使用して最適化してください
ページ速度は重要なランキング要素であり、検索エンジンがサイトをクローリングする速度に影響を与える可能性があります。
5. 重複コンテンツの削除
重複コンテンツページにはペナルティが科されます。
canonicalタグまたはメタタグを最適化することでこれを回避できます。
6. 特定ページの露出制限
検索エンジンが特定のページをクローリングしないようにする場合、次の方法を使用できます。
- 'noindex'タグを配置する。
- URLをrobots.txtファイルに配置する。
7. 外部サイトにホームページをバックリンクさせる
バックリンクとは、他のウェブサイトからあなたのウェブサイトへのリンクを提供することを意味します。
このリンクはあなたのウェブサイトを信頼できる情報源にリンクする役割を果たします
検索エンジンはこれによってあなたのウェブサイトの信頼性と権威を評価します。
これは信頼できる出所からリンクが提供される場合、より大きな影響を与えます。
この記事も読んでみてください:
データ収集、今度は自動化してください
コーディングなしで5分で開始・5,000以上のウェブサイトをクロールした経験



