

0. XPathとは?
XPathは「XML Path Language」の略で、XMLドキュメントの特定の要素や属性にアクセスするためのパスを指定する言語です。
XPathは主にWebクローリング作業で使用されますが、まずはXPathの基本構文について見ていきましょう。
1. Xpathの基本構文
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>hashscraper</title>
</head>
<body>
<div id="container">
<div class="title">
<p class="content1">let's start crawling!</p>
<p class="content2">crawling is fun!</p>
</div>
</div>
</body>
</html>
2. HTMLコード
以下は簡単なHTMLコードです。
HTMLコードは要素(element)と属性(attribute)で構成されており、各要素や属性は階層関係を持っています。
XPathはXMLドキュメントをツリー構造で表現し、最上位ノードから最下位ノードまでのすべてのノードや属性、データを抽出するためのパスを示します。
(*ここでのノードとは、要素、属性、テキスト内容などのXMLドキュメントの各部分を指します。)
上記のコードでtitle要素にアクセスするためのパスを取得してみましょう。
title要素はツリー構造上の順序でhtml要素 → head要素 → title要素の順に構成されています。
したがって、title要素のXPathは次のようになります。
/html/head/title
また、XPathではclassなどの要素を結びつける属性を「@」で表します。@を使用して上記のコードで最初のp要素のXPathを示すと次のようになります。
/html/body/div/div/p[@class='content1']
3. Xpathの2つの表現方法
XPathには2つの方法があり、絶対パスと相対パスで表すことができます。
3.1. Xpath:絶対パス
絶対パスは先ほど使用した方法と同じであり、最上位のルートノードから要素を選択する方法です。
html/body/div/div/p[@class='content1']
3.2. Xpath:相対パス
相対パスは「//」を使用して中間ノードのパスを省略し、指定されたノードから順番に探索を進めます。上記の絶対パスを相対パスで表すと次のようになります。
//p[@class='content1']
4. その他の表現構文
XPathではパスを表すためにさまざまな構文を使用しています。
4.1. contains
: その値を含む場合を取得します。
#'aa'를 포함하는 class명을 가진 div 요소를 선택
//div[contains(@class, "aa")]
4.2. last
: パスに該当するノードの中で最後のノードを取得します。
//div[@class="aa")/span[last()]
4.3. and
: 両条件を満たすノードを取得します。
#class명에 'aa'와 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") and contains(@class, "bb")]
4.4. or
: 2つの条件のうち少なくとも1つを満たすノードを取得します。
#class명에 'aa' 또는 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") or contains(@class, "bb")]
4.5. not
: その条件を満たさないノードを取得します。
#class명에 'aa'를 포함하고 'bb'를 포함하지 않는 img 요소를 선택
//img[contains(@class, "aa") and not(contains(@class, "bb")
5. 実践例
これまでXPathの基本構文を見てきました。では、ウェブサイトから欲しい部分のXPathを取得してみましょう。
5.1. 開発者ツールを開く
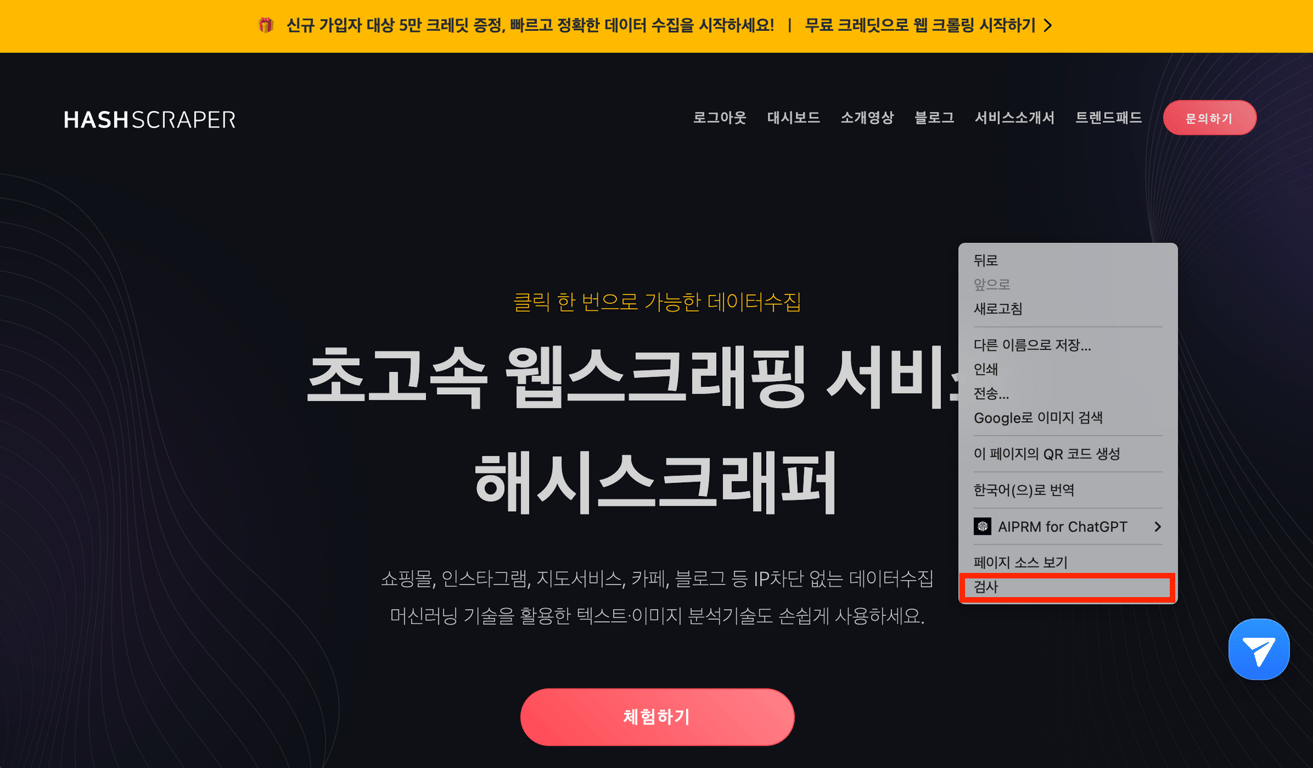
まず、目的のウェブサイトを開いて、マウスの左ボタンをクリックし、「検査」をクリックすると、Chromeの開発者ツールが開くことができます。
5.2. 欲しいタグを確認する
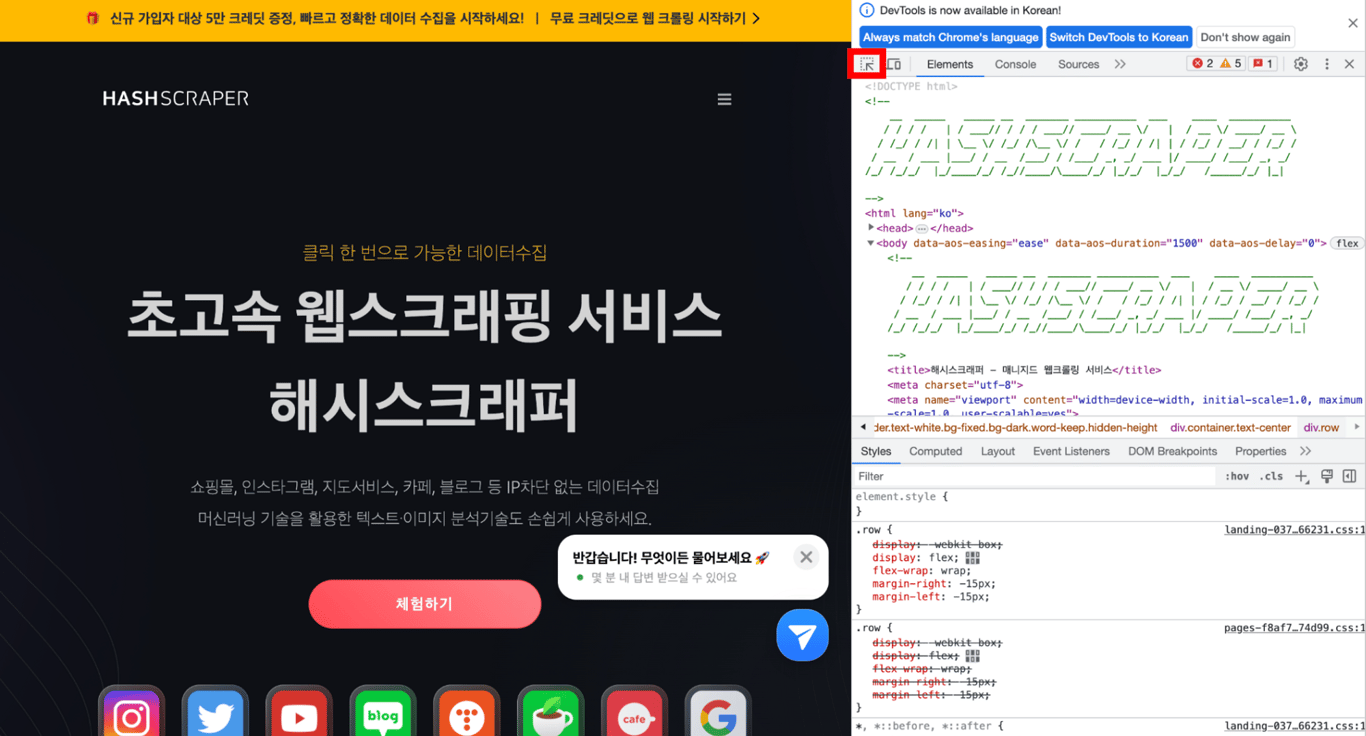
開発者ツールで左上のマウスアイコンをクリックし、その後、ウェブサイトの取得したい部分にマウスを重ねると、以下のように表示されます。
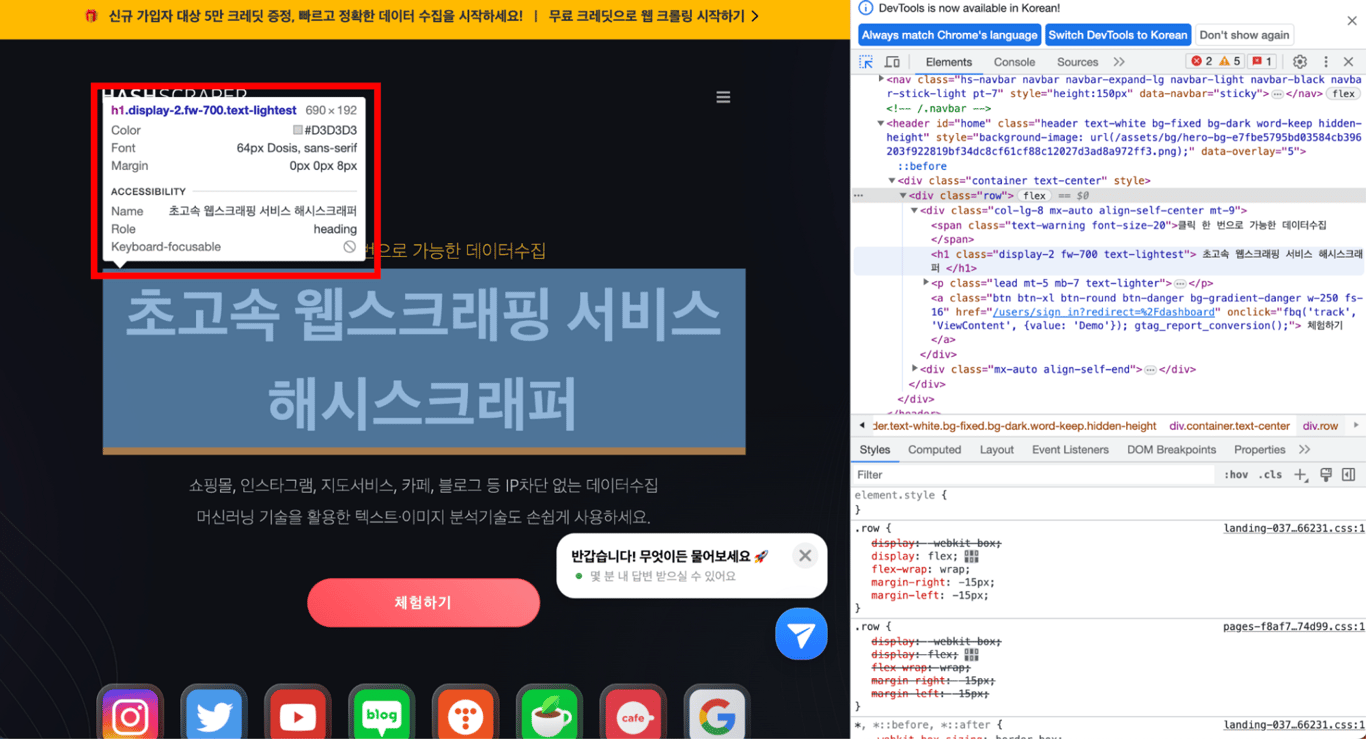
クリックすると、開発者ツールが実際のHTMLコードから欲しい部分のタグを表示します。
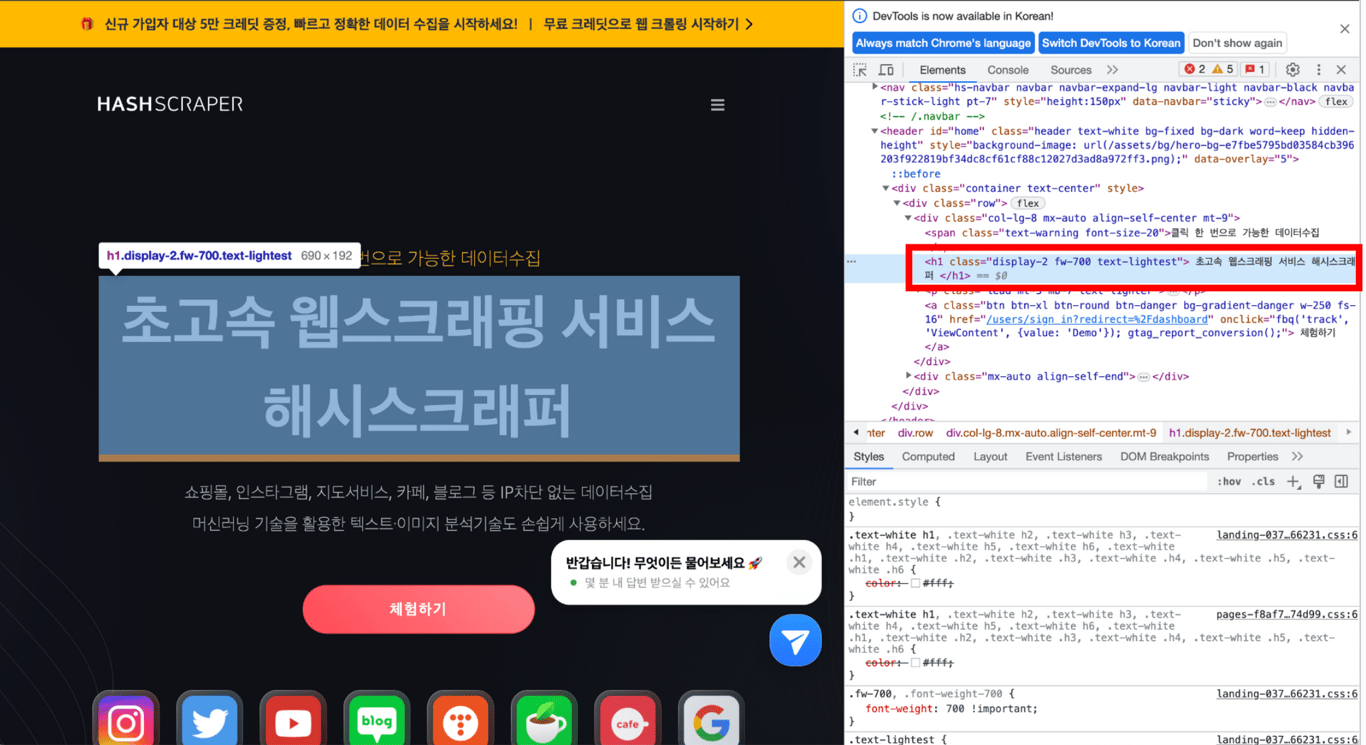
5.3. XPathをコピーする
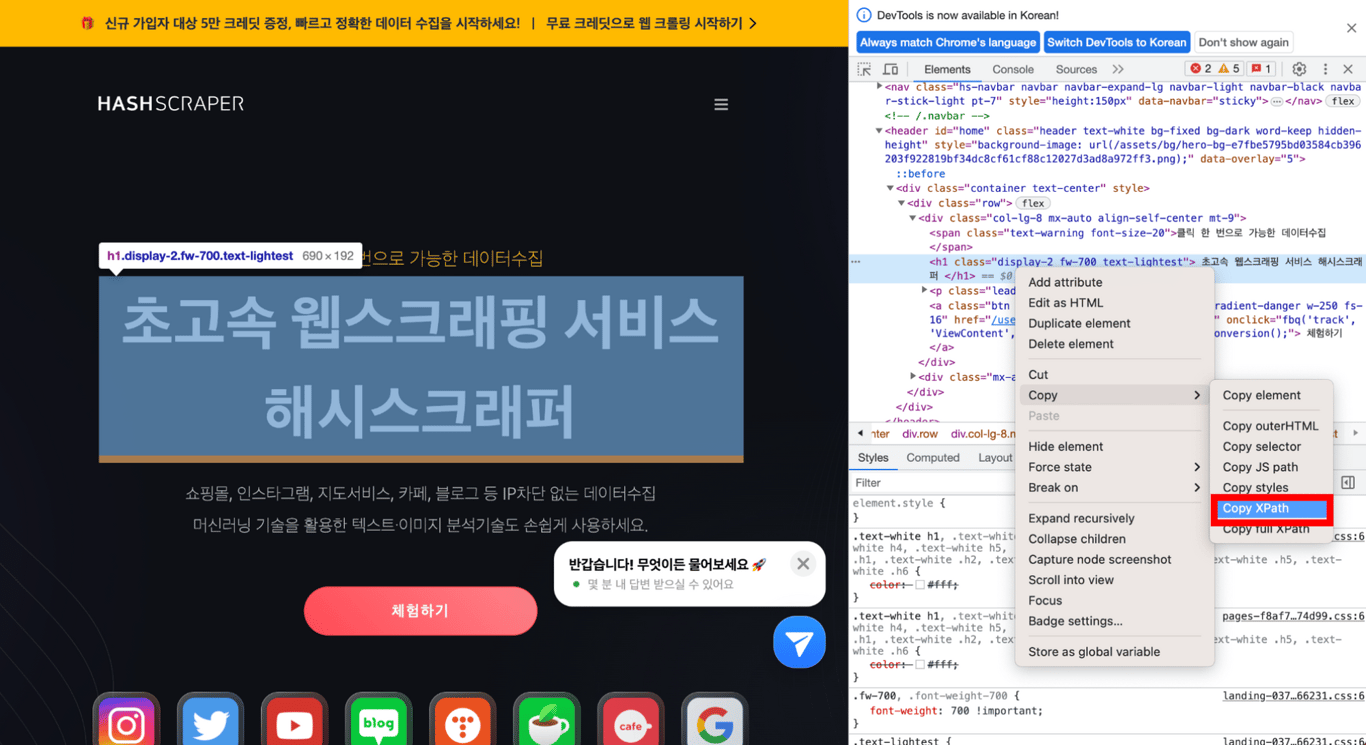
該当部分をCopy > Copy XPathしてコピーした内容を貼り付けると、欲しい部分のXPathを取得できます!
以下のように、欲しい部分のXPathが正常に移動したことを確認できます。
//*[@id="home"]/div/div/div[1]/h1
では、このように取得したXPathはクローリングにどのように使用されるのでしょうか?クローリングコードの一部を取得してみました。
get_browser.goto "<https://www.hashscraper.com>"
x = get_browser.element(xpath: "//*[@id='home']/div/div/div[1]/h1").text
5.4. 動作確認
次のようにXPathを使用して欲しい要素を取得し、xに保存し、xをプリントすると、欲しかったテキストが表示されることが確認できます。
6. 結論:正しいクローリングを行うためには、まずXPathを学ぼう
これまでクローリングの基礎であるXPathについて見てきました。欲しいデータを収集するためには、そのデータがどのようなパスで表現されるかを知る必要があり、これはXPathを使って簡単に表現できます。XPathの学習を始め、クローリングを始めることをお勧めします!
この記事も読んでみてください:
データ収集、今度は自動化しましょう
コーディング不要、5分で開始・5,000以上のウェブサイトクローリング経験



