

0. 概要
XPath 1에서는 웹 크롤링에 필수적인 XPath의 개념과 기본 구문을 다뤘지만, 2에서는 XPath의 심화 내용을 소개하겠습니다.
1. 와일드카드에 대한 이해
심화 내용에 들어가기 전에, XPath에서 '*(와일드카드)'의 의미를 이해하는 것이 중요합니다.
- (와일드카드)는 XPath에서 모든 요소와 일치하며, 모든 요소를 선택하는 데 사용됩니다. 예를 들어 설명하겠습니다.
//div[contains(@class, "aa")]
위의 XPath는 'aa'를 포함하는 class 이름을 가진 div 요소를 나타냅니다. 여기서 div 대신 와일드카드를 사용하면 어떻게 될까요?
//*[contains(@class, "aa")]
위의 XPath에서 ‘*’는 모든 요소와 일치하므로 'aa'를 포함하는 class 이름을 가진 모든 요소를 나타냅니다.
2. XPath 계층 구조의 이해
이제 XPath의 심화 내용을 살펴보겠습니다.
다음은 간단한 HTML 코드입니다.
<AAA>
<BBB>
<CCC/>
<DDD/>
</BBB>
<EEE>
<FFF>
<GGG/>
<GGG/>
<III>
<JJJ/>
</III>
</FFF>
</EEE>
<KKK>
<LLL/>
</KKK>
</AAA>
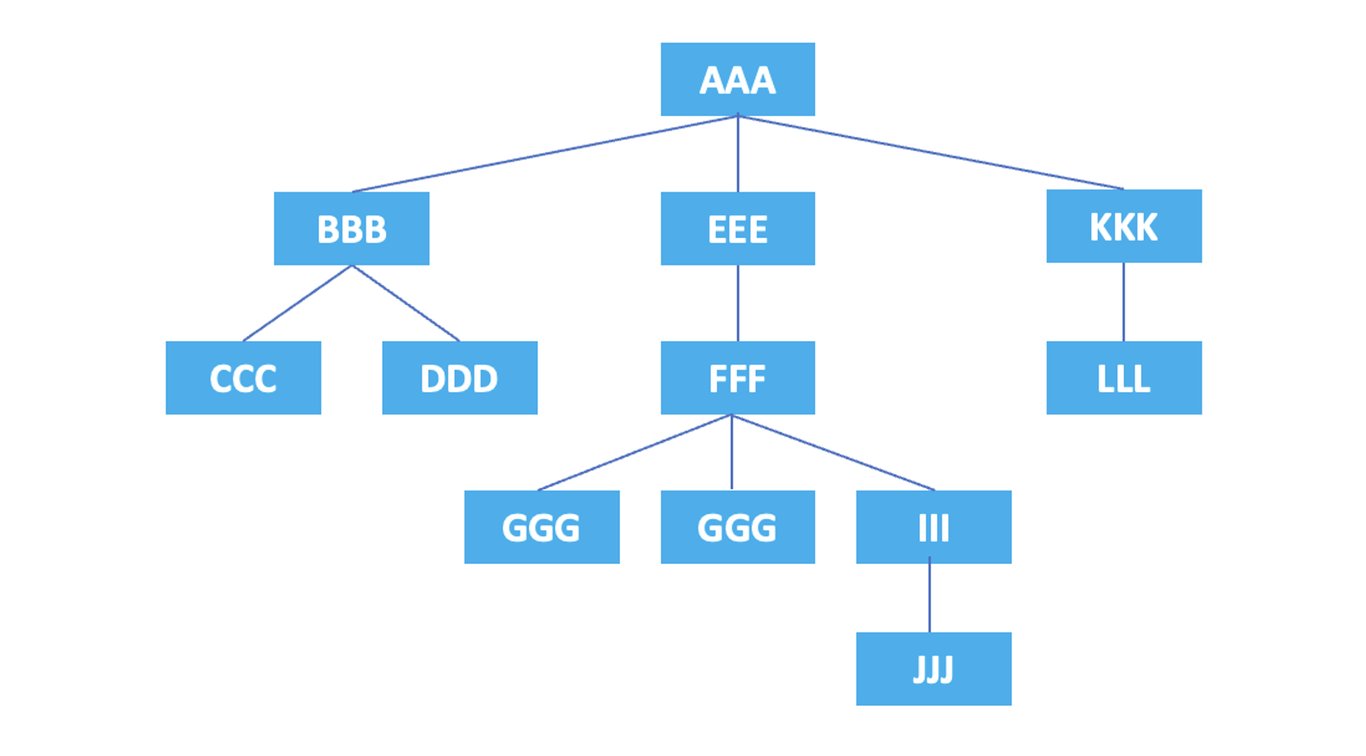
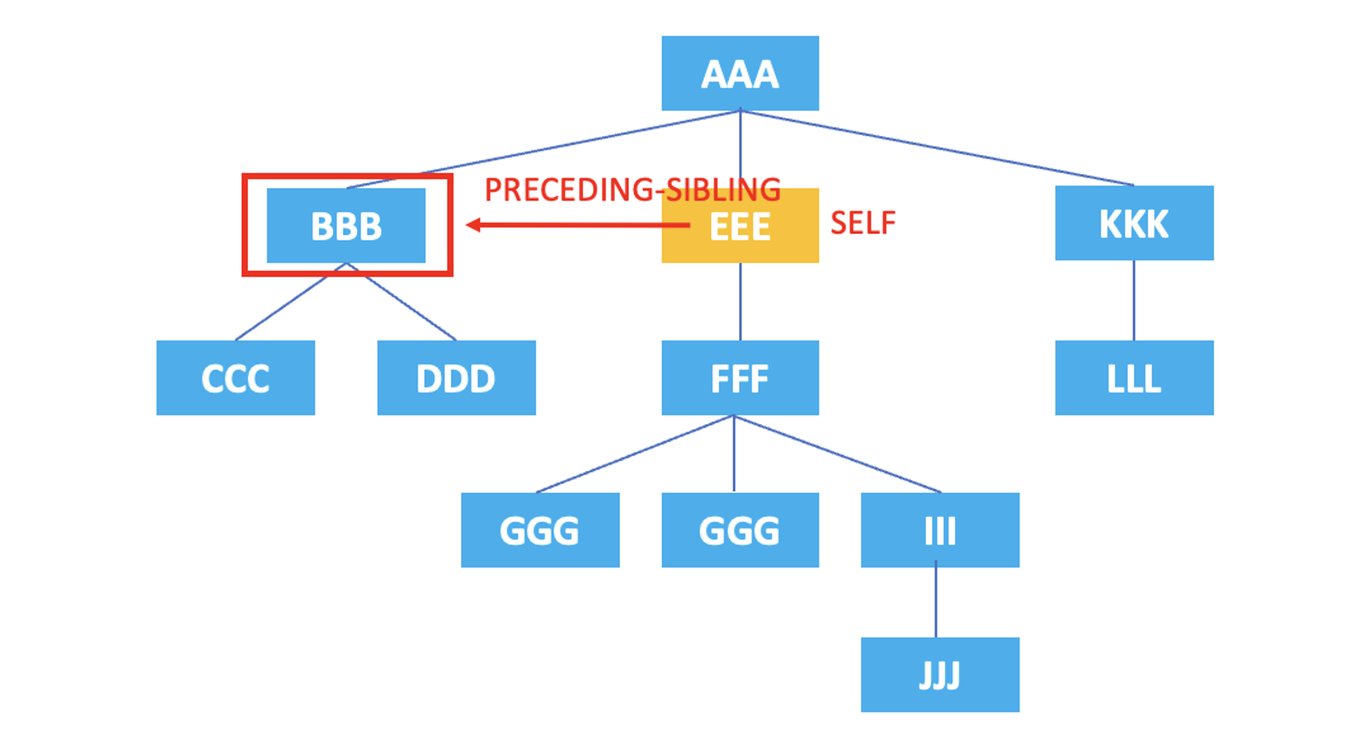
HTML 코드의 각 요소와 속성은 계층 구조를 이루며, XPath에서는 이러한 계층 구조를 트리(Tree)로 표현합니다. 축은 트리 구조에서 노드를 참조하고 선택하는 데 사용되는 방향이나 관계를 나타냅니다. self 축, parent 축, child 축 등의 축이 있으며, 아래에서 예시를 통해 하나씩 설명하겠습니다.
위 요소들의 계층 구조를 그림으로 나타내면 다음과 같습니다.
이제 축을 사용하여 노드를 어떻게 나타낼 수 있는지 살펴보겠습니다.
3. ノード(node)の表現方法
3.1. self
: 現在のノードを自身を表します。
/AAA/self::*
上記のXPathの結果は、現在のノードである <AAA> 要素が選択されます。
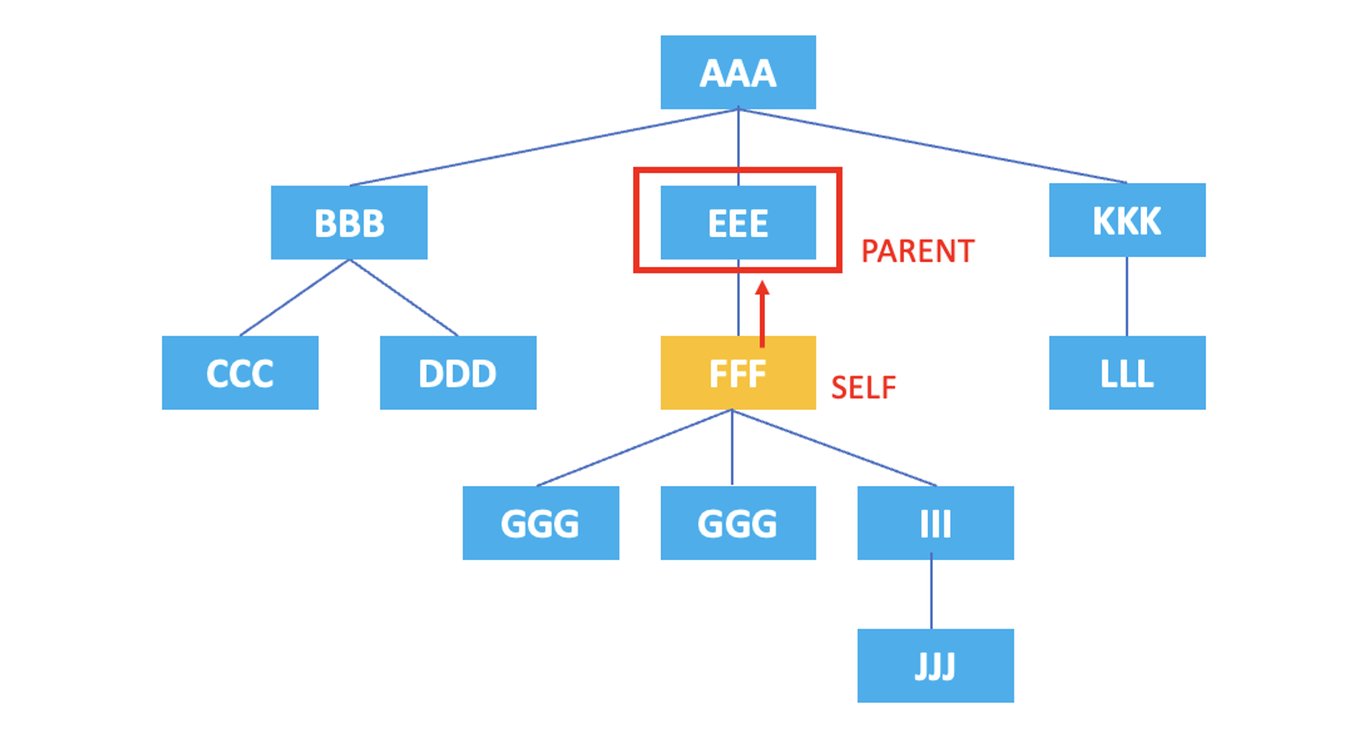
3.2. parent
: 現在のノードの親ノードを表します。
/AAA/EEE/FFF/parent::*
上記のXPathの結果は、現在のノードである <FFF> 要素の親ノードである <EEE> 要素が選択されます。
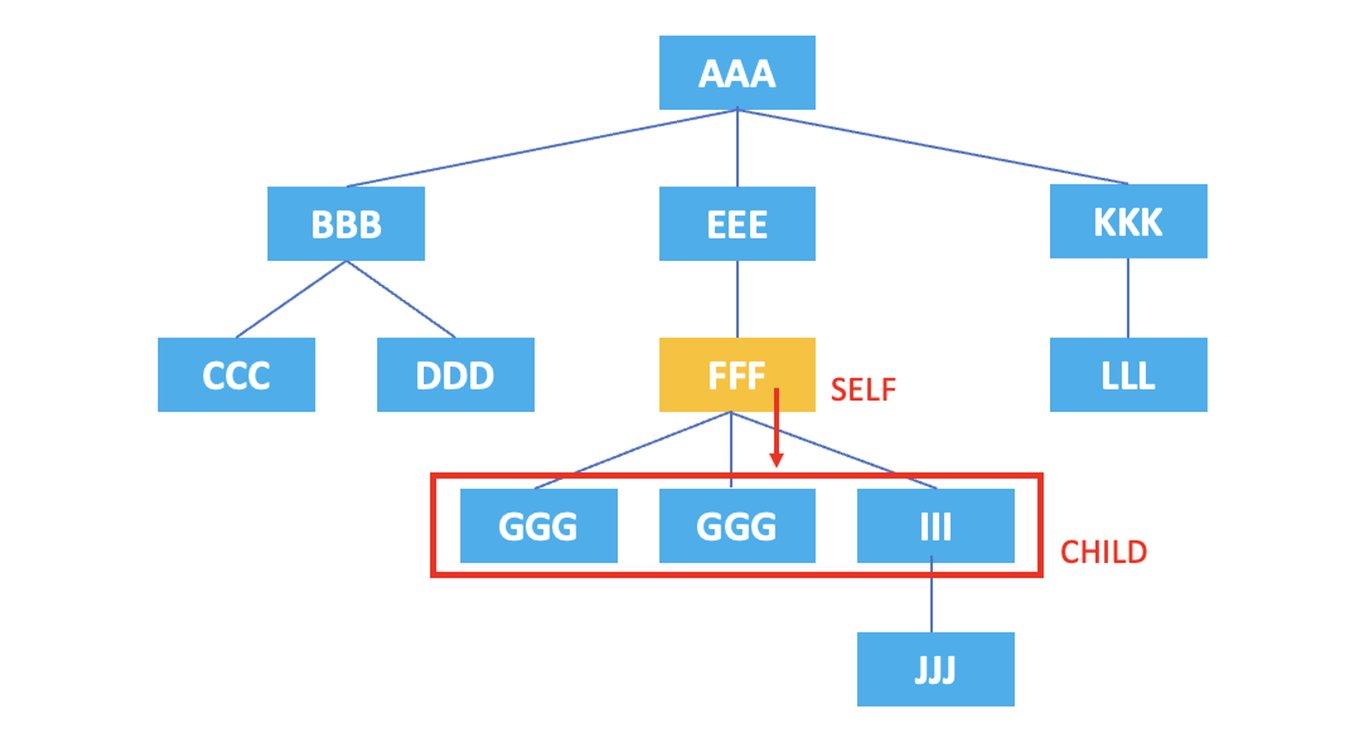
3.3. child : 現在のノードの子ノードを表します。
/AAA/EEE/FFF/child::*
上記のXPathの結果は、現在のノードである <FFF> 要素の子ノードである <GGG>, <HHH>, <III> がすべて選択されます。
ここで <III> 要素だけを選択したい場合は、次のようにXPathを修正できます。
/AAA/EEE/FFF/child::III
また、2つの <GGG> 要素のうち最初の <GGG> 要素を選択したい場合は、次のように修正できます。
/AAA/EEE/FFF/child::GGG[1]
このとき、他の多くのプログラミング言語とは異なり、XPathではインデックスが1から始まることに注意する必要があります!
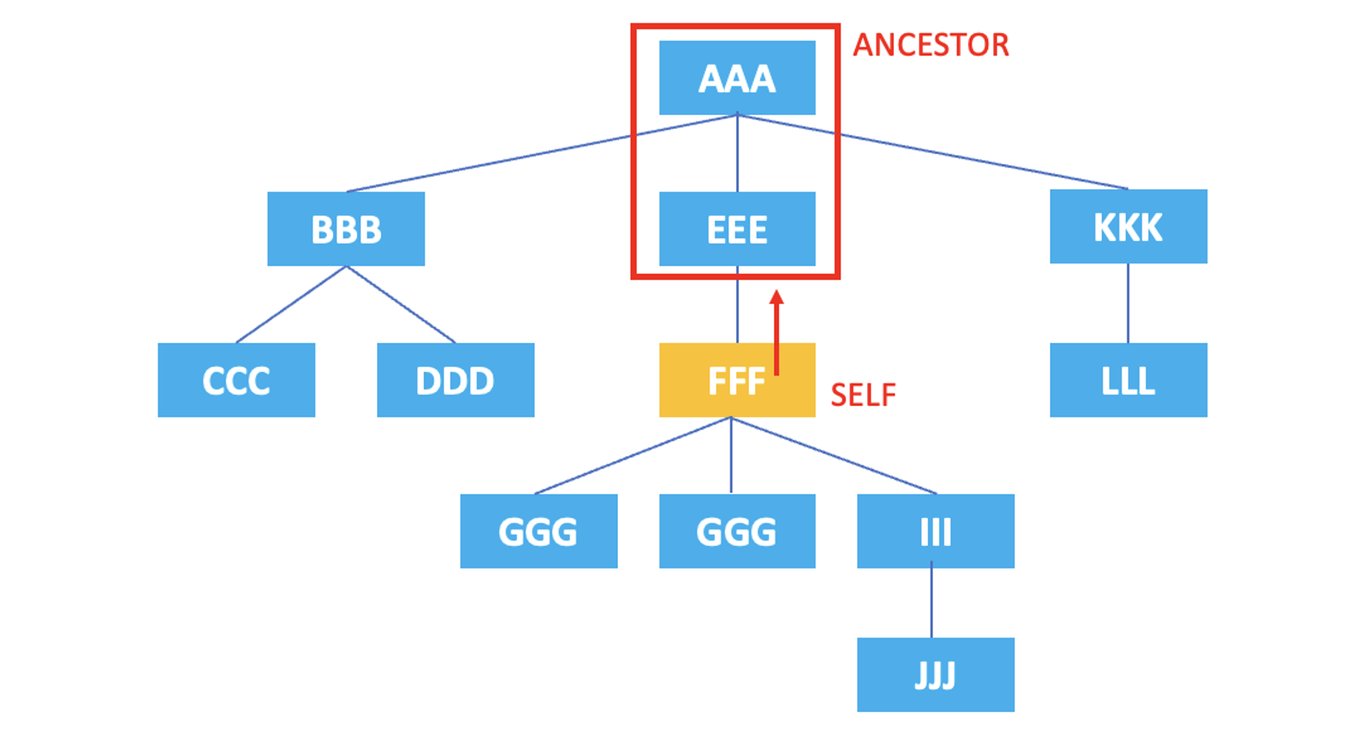
3.3. ancestor
: 現在のノードのすべての祖先ノードを表します。
/AAA/EEE/FFF/ancestor::*
上記のXPathの結果は、現在のノードである <FFF> 要素の祖先ノードである <EEE>, <AAA> がすべて選択されます。
3.4. descendant
: 現在のノードのすべての子孫ノードを表します。
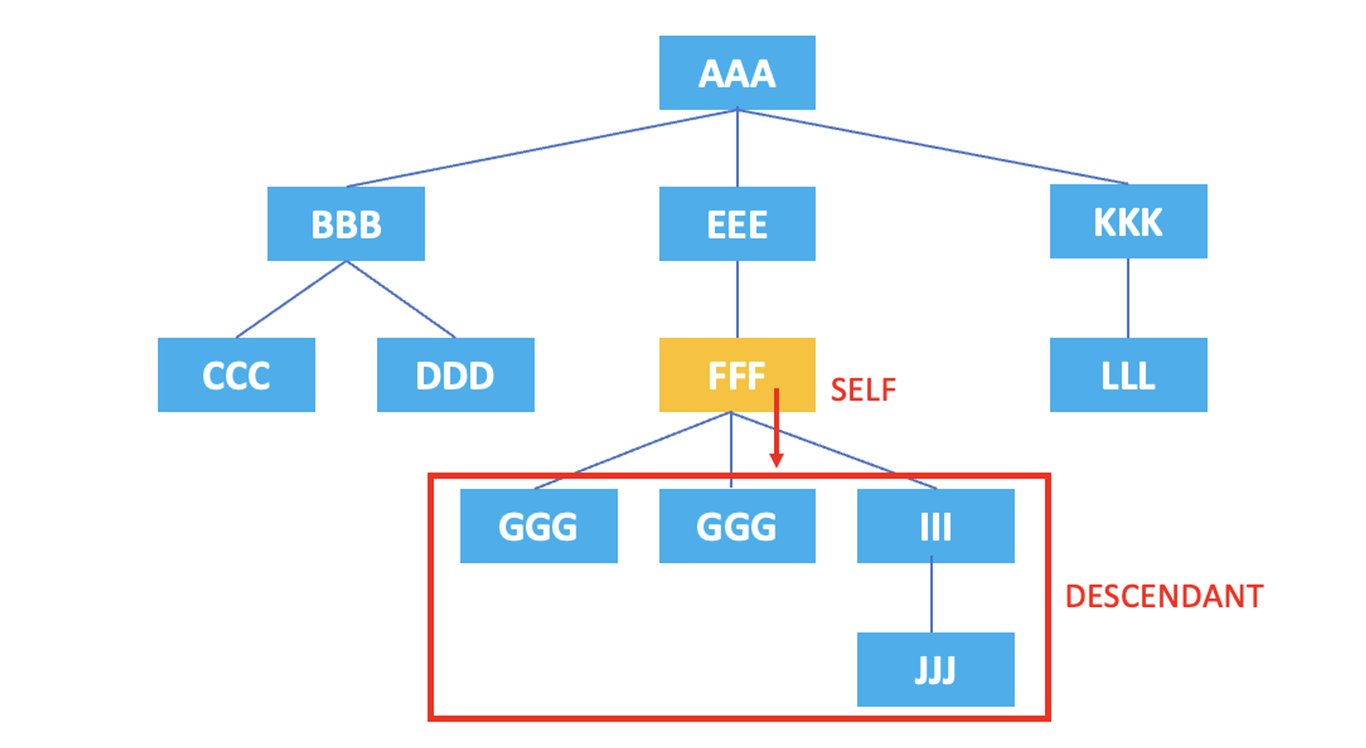
/AAA/EEE/FFF/descendant::*
上記のXPathの結果は、現在のノードである <FFF> 要素の子孫ノードである <GGG>, <HHH>, <III>, <JJJ> がすべて選択されます。
3.5. ancestor-or-self
: 現在のノードと現在のノードのすべての祖先ノードを表します。
/AAA/EEE/FFF/ancestor-or-self::*
上記のXPathの結果は、現在のノードである <FFF> 要素自身と祖先ノードがすべて選択され、<FFF>, <EEE>, <AAA> がすべて選択されます。
3.6. descendant-or-self
: 現在のノードと現在のノードのすべての子孫ノードを表します。
/AAA/EEE/FFF/descendant-or-self::*
上記のXPathの結果は、現在のノードである <FFF> 要素自身と子孫ノードがすべて選択され、<FFF>, <GGG>, <HHH>, <III>, <JJJ> がすべて選択されます。
3.7. following
: 現在のノードのタグが終了した後に出現するすべてのノードを表します。
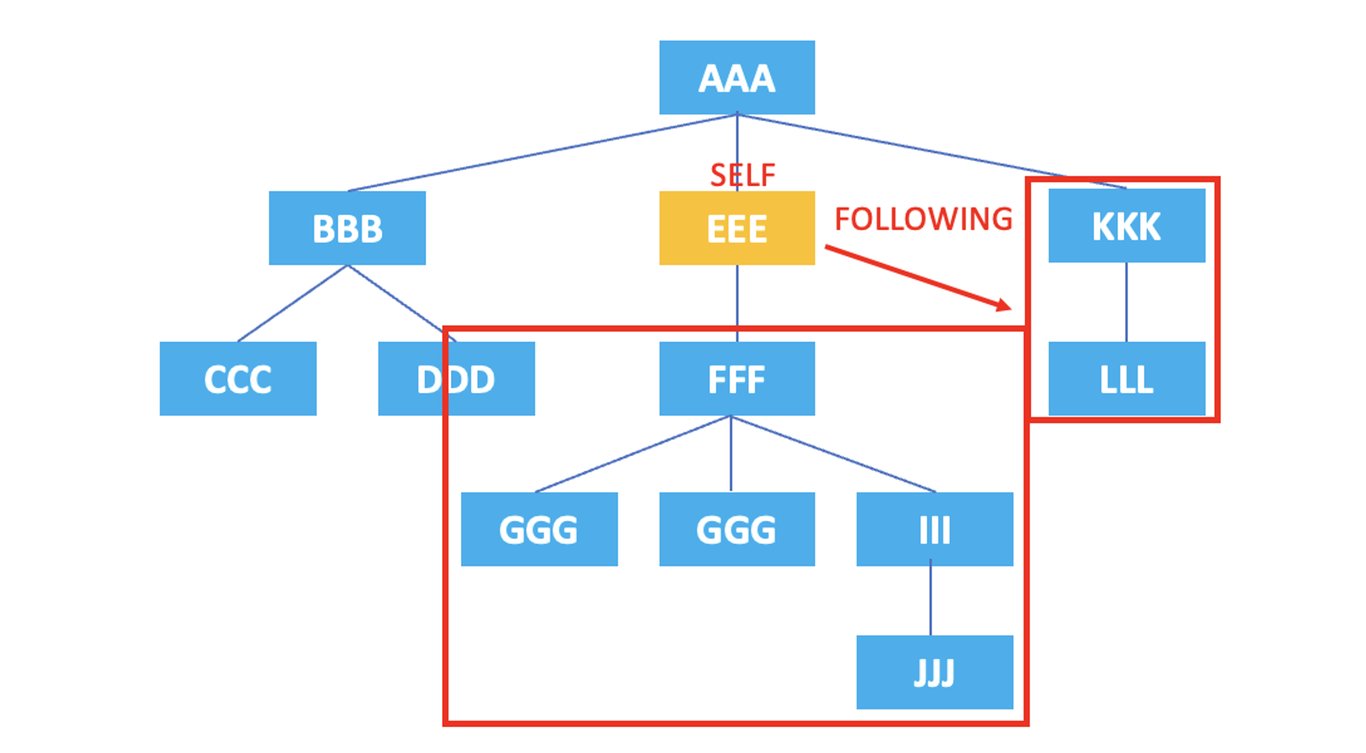
/AAA/EEE/following::*
上記のXPathの結果は、現在のノードである <EEE> の後に出現するノードである <FFF>, <GGG>, <HHH>, <III>, <JJJ>, <KKK>, <LLL> がすべて選択されます。
3.8. preceding
: 現在のノードのタグが開始される前に出現するすべてのノードを表します。
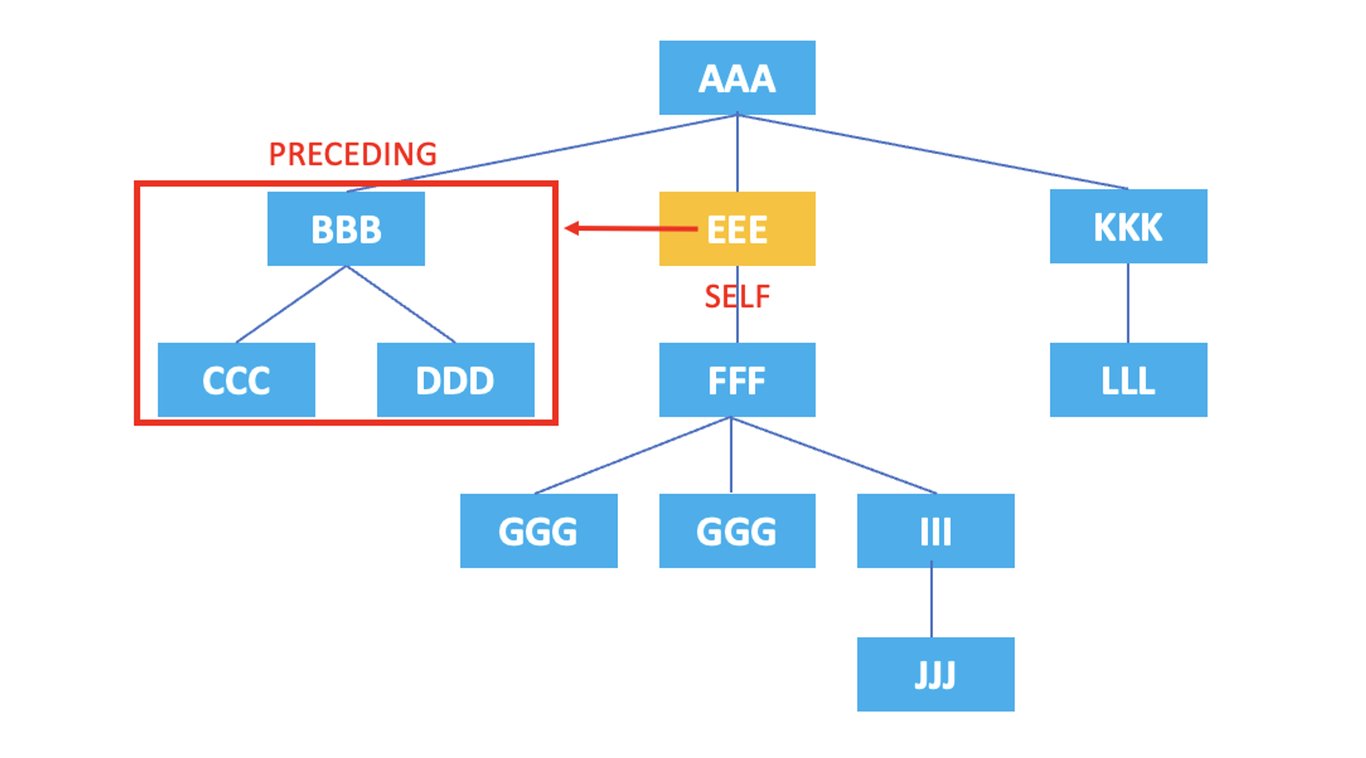
/AAA/EEE/preceding::*
上記のXPathの結果は、現在のノードである <EEE> の前に出現するノードである <BBB>, <CCC>, <DDD> がすべて選択されます。
3.9. following-sibling
: 現在のノードの直後に出現するすべての兄弟ノードを表します。
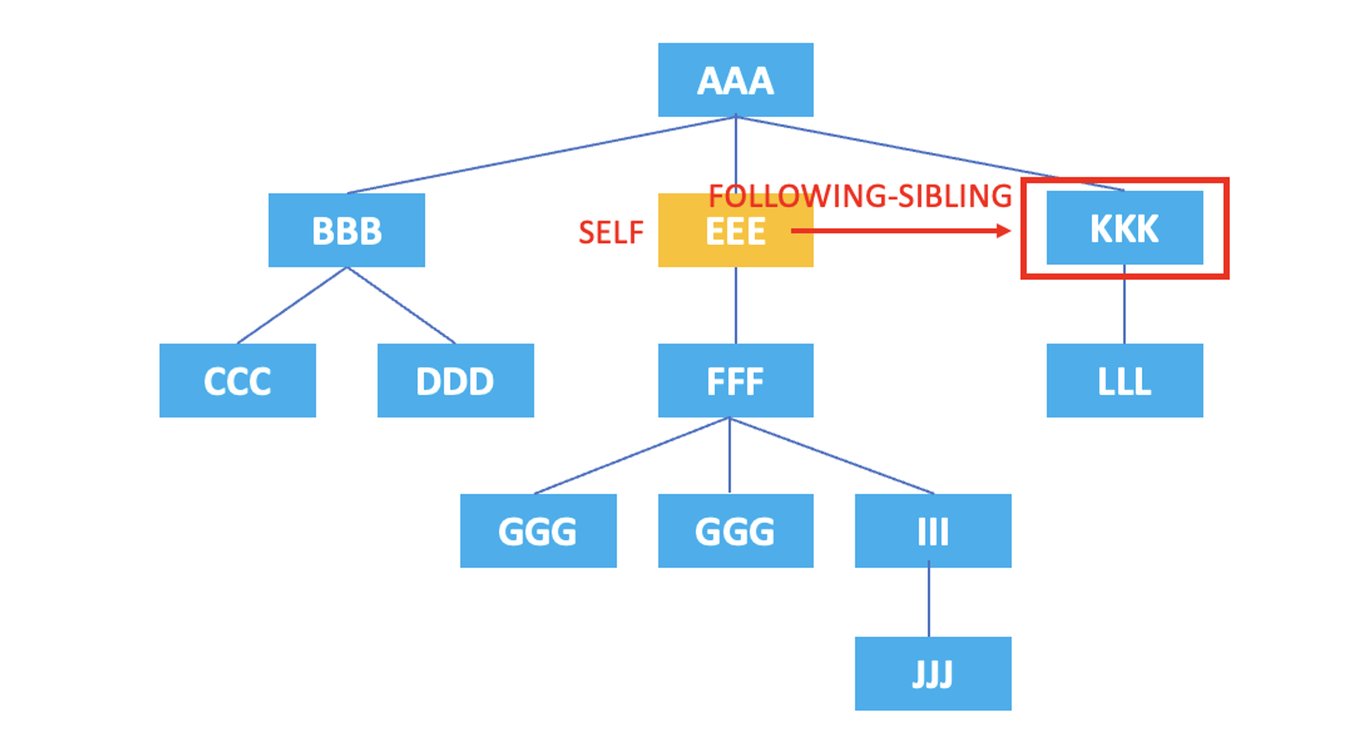
/AAA/EEE/following-sibling::*
上記のXPathの結果は、現在のノードである <EEE> の直後に出現する兄弟ノードである <KKK> が選択されます。
3.10. preceding-sibling
: 現在のノードの直前に出現するすべての兄弟ノードを表します。
/AAA/EEE/preceding-sibling::*
上記のXPathの結果は、現在のノードである <EEE> の前に出現する兄弟ノードである <BBB> が選択されます。
これまで、ノードを表すために使用される軸について説明しました。
さらに、XPathで使用できる他の2つの関数について説明します。
4. XPathに使用する関数
4.1. count
: 特定の条件に一致するノードの数を返します。
#class 속성 값이 ‘example인 div 요소의 개수를 반환
count(//div[@class="example"])
#p 요소의 총 개수를 반환
count(//p)
4.2. position
: 現在のノードの位置を返します。 (位置は1から始まり、順次増加します。)
<root>
<item>Item 1</item>
<item>Item 2</item>
<item>Item 3</item>
</root>
たとえば、次のようなxmlコードがある場合、XPathを次のように記述できます。
//item[position() = 2]
position関数を使用して3つのitem要素のうち2番目のitem要素を選択できます。
5. 結論
これまでXPathの高度な内容を見てきました。基本から高度までマスターしたら、XPathを使用してXMLドキュメントから必要な要素を正確に見つけてデータを抽出するために必要な基本知識がかなり学習されたと見なしてもよいでしょう。
XPathはXMLドキュメントを探索および操作する強力なツールであり、実務ではデータスクレイピング、Webスクレイピング、XMLベースのWebサービスからデータを抽出するなど、さまざまな分野で活用されています。XPathを使用してデータを効率的に抽出し、活用できるように成功を祈ります!
この記事も読んでみてください:
データ収集、今度は自動化
コーディングなしで5分で開始・5,000以上のウェブサイトをスクレイピングした経験



