

0. Was ist XPath?
XPath ist die Abkürzung für 'XML Path Language' und ist eine Sprache, die Pfade zur Navigation zu bestimmten Elementen oder Attributen in XML-Dokumenten angibt.
XPath wird hauptsächlich bei Web-Scraping-Aufgaben verwendet. Lassen Sie uns zunächst die grundlegende Syntax von XPath betrachten.
1. Grundlegende Syntax von XPath
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>hashscraper</title>
</head>
<body>
<div id="container">
<div class="title">
<p class="content1">let's start crawling!</p>
<p class="content2">crawling is fun!</p>
</div>
</div>
</body>
</html>
2. HTML Code
Hier ist ein einfacher HTML-Code.
HTML-Code besteht aus Elementen und Attributen, die hierarchisch angeordnet sind.
XPath stellt XML-Dokumente als Baumstruktur dar und zeigt Pfade an, um alle Knoten, Attribute und Daten von der obersten Ebene bis zur untersten Ebene abzurufen.
(*Ein Knoten bezieht sich hier auf jeden Teil eines XML-Dokuments wie Elemente, Attribute, Textinhalt usw.)
Lassen Sie uns den Pfad zum title-Element aus dem obigen Code erhalten.
In der Baumstruktur besteht das title-Element aus den Elementen html -> head -> title.
Daher sieht der XPath für das title-Element wie folgt aus:
/html/head/title
Darüber hinaus wird in XPath ein Attribut, das Elemente wie class verknüpft, mit "@" dargestellt. Wenn wir das XPath für das erste p-Element im obigen Code angeben möchten, sieht es wie folgt aus:
/html/body/div/div/p[@class='content1']
3. Zwei Arten der XPath-Darstellung
XPath kann auf zwei Arten dargestellt werden: absoluter Pfad und relativer Pfad.
3.1. XPath: Absoluter Pfad
Der absolute Pfad ist der gleiche wie der zuvor verwendete Ansatz und wählt Elemente von der obersten Wurzel aus.
html/body/div/div/p[@class='content1']
3.2. XPath: Relativer Pfad
Der relative Pfad verwendet '//' und durchsucht die Knoten nacheinander ab dem angegebenen Knoten, wobei der Pfad zu den Zwischenknoten ausgelassen wird. Wenn wir den absoluten Pfad in einen relativen Pfad umwandeln, sieht er wie folgt aus:
//p[@class='content1']
4. Weitere Syntax in XPath
Zusätzlich zu den oben genannten Syntaxen verwendet XPath verschiedene andere Syntaxelemente, um Pfade darzustellen.
4.1. contains
: Ruft die Fälle ab, die den angegebenen Wert enthalten.
#'aa'를 포함하는 class명을 가진 div 요소를 선택
//div[contains(@class, "aa")]
4.2. last
: Ruft den letzten Knoten ab, der dem Pfad entspricht.
//div[@class="aa")/span[last()]
4.3. and
: Ruft die Knoten ab, die beide Bedingungen erfüllen.
#class명에 'aa'와 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") and contains(@class, "bb")]
4.4. or
: Ruft die Knoten ab, die mindestens eine der Bedingungen erfüllen.
#class명에 'aa' 또는 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") or contains(@class, "bb")]
4.5. not
: Ruft die Knoten ab, die die Bedingung nicht erfüllen.
#class명에 'aa'를 포함하고 'bb'를 포함하지 않는 img 요소를 선택
//img[contains(@class, "aa") and not(contains(@class, "bb")
5. Praktische Übungen
Wir haben uns bisher die grundlegende Syntax von XPath angesehen. Wollen wir nun den XPath für den gewünschten Teil einer Website erhalten?
5.1. Öffnen der Entwicklertools
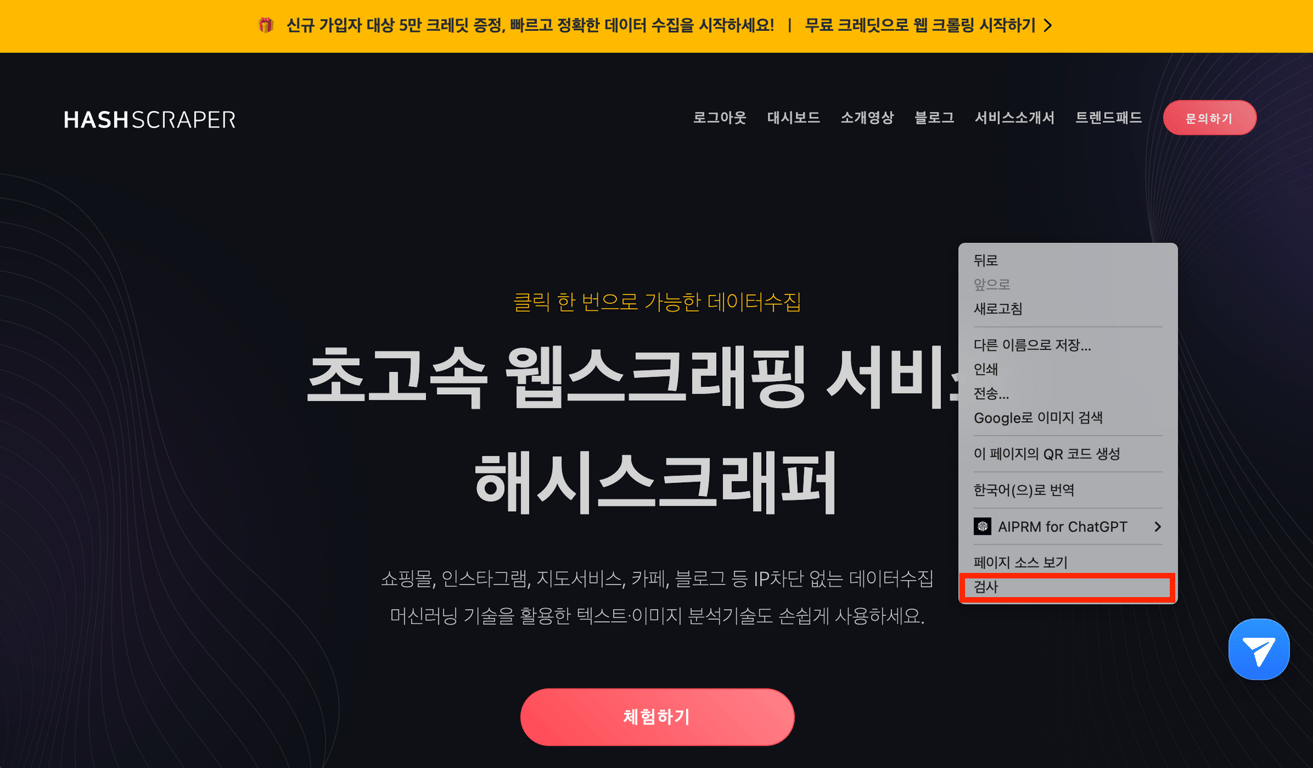
Öffnen Sie zunächst die gewünschte Website und klicken Sie mit der linken Maustaste, dann auf 'Inspektion', um die Chrome-Entwicklertools zu öffnen.
5.2. Überprüfen des gewünschten Tags
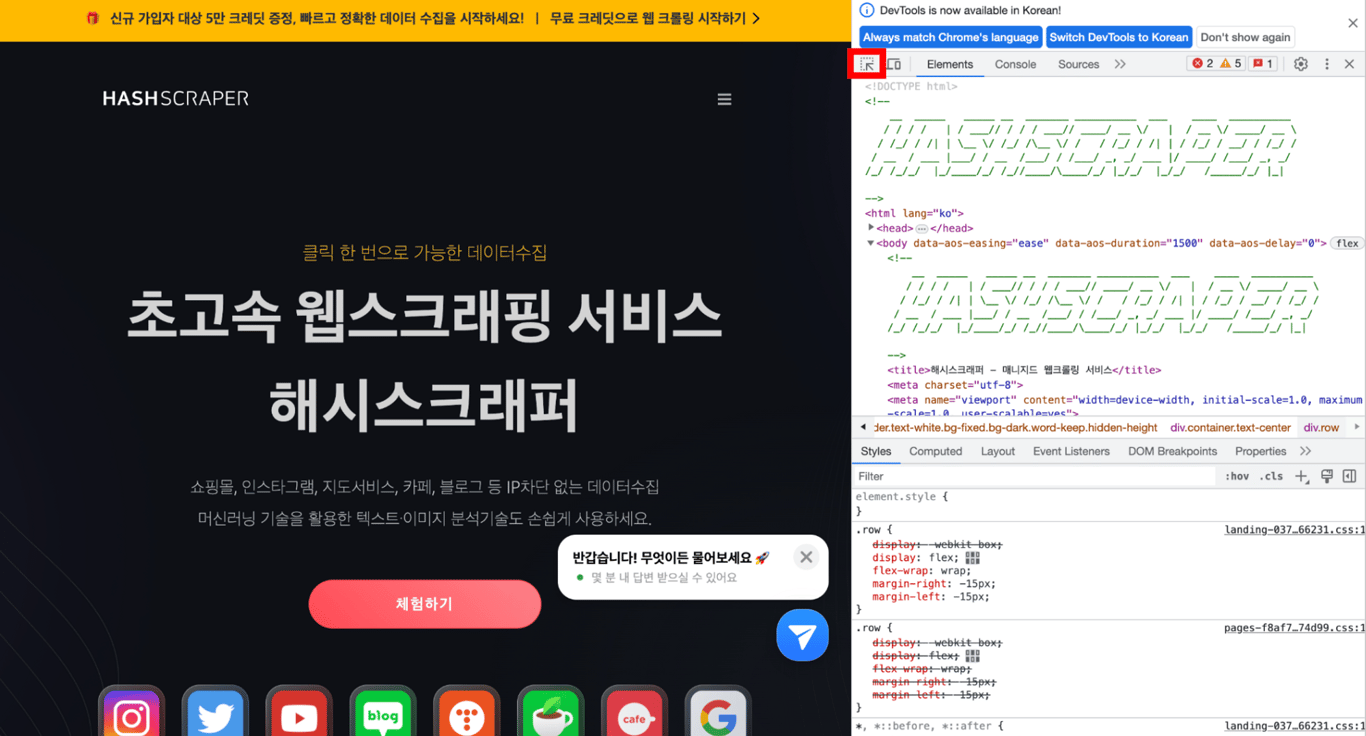
Klicken Sie in den Entwicklertools oben links auf das Maussymbol. Wenn Sie die Maus über den gewünschten Teil der Website bewegen, wird dieser wie unten angezeigt hervorgehoben.
Klicken Sie auf die ausgewählte Stelle, um die Tags des gewünschten Teils im HTML-Code anzuzeigen.
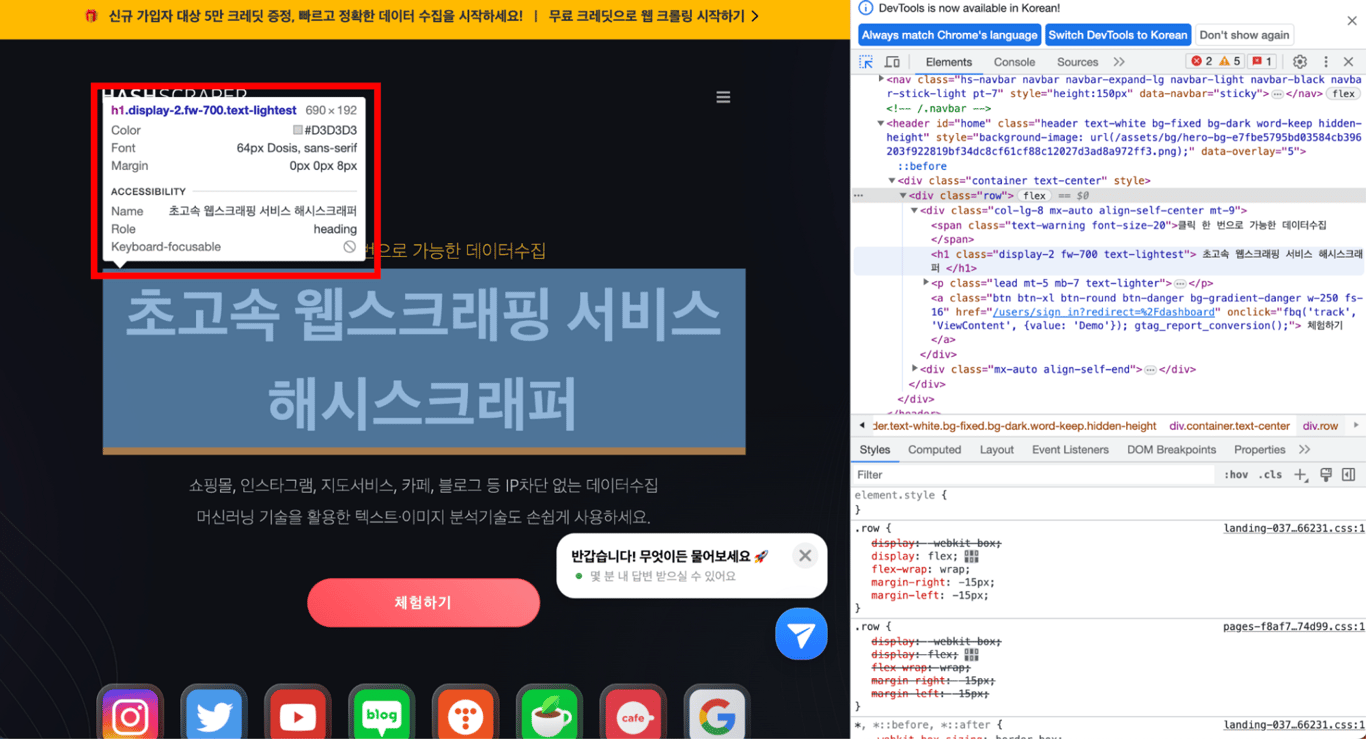
5.3. Kopieren des XPath
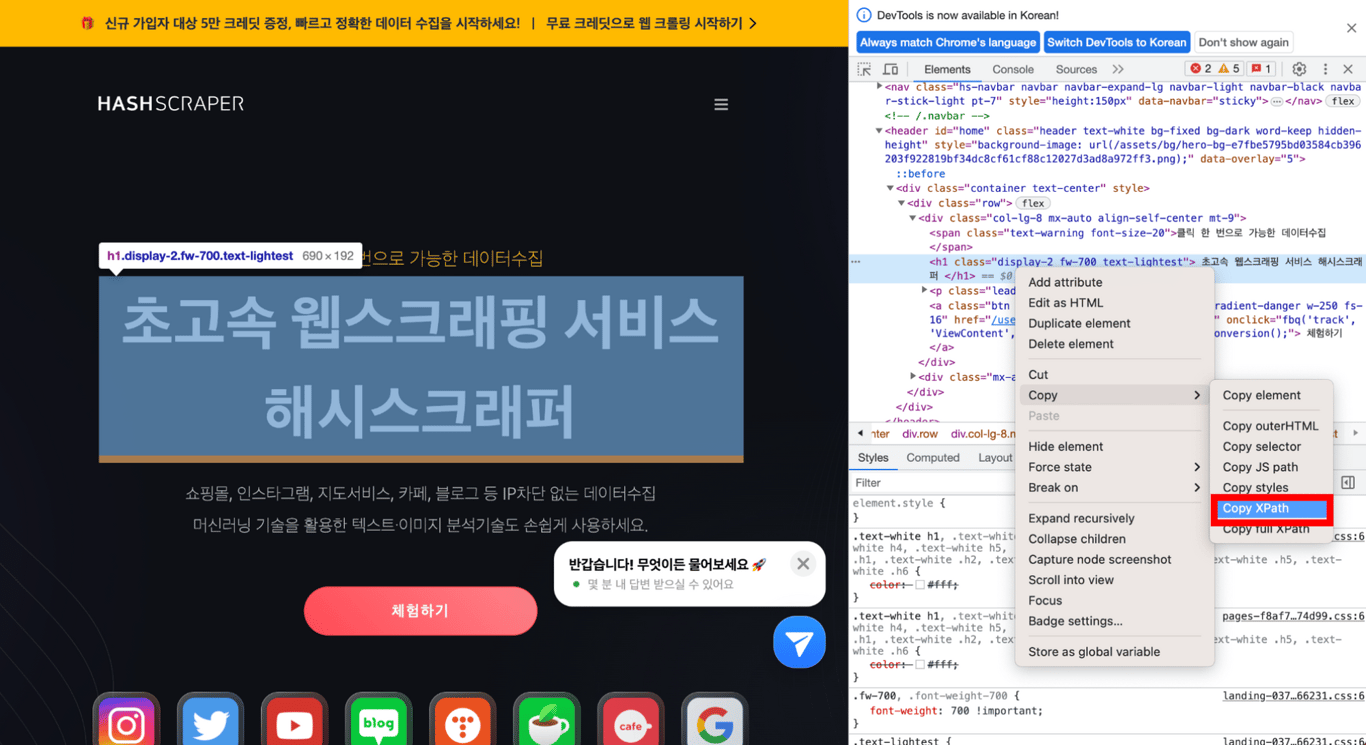
Kopieren Sie den XPath, indem Sie 'Kopieren' > 'XPath kopieren' auswählen, und fügen Sie ihn ein. Auf diese Weise erhalten Sie den XPath für den gewünschten Teil!
Sie können überprüfen, ob der XPath für den gewünschten Teil erfolgreich übernommen wurde, wie unten gezeigt.
//*[@id="home"]/div/div/div[1]/h1
Wie kann dieser XPath nun beim Web-Scraping verwendet werden? Hier ist ein Ausschnitt des Scraping-Codes.
get_browser.goto "<https://www.hashscraper.com>"
x = get_browser.element(xpath: "//*[@id='home']/div/div/div[1]/h1").text
5.4. Überprüfung der Funktionsweise
Indem wir den XPath verwenden, um das gewünschte Element abzurufen und in x zu speichern, können wir überprüfen, ob der Text, den wir wollten, korrekt ausgegeben wird.
6. Fazit: Beginnen Sie mit dem Lernen von XPath, um erfolgreich zu crawlen
Wir haben die Grundlagen des Crawling und XPath betrachtet. Um die gewünschten Daten durch Crawling zu sammeln, ist es wichtig zu wissen, wie diese Daten über Pfade dargestellt werden können, was einfach mit XPath möglich ist. Wir empfehlen Ihnen, mit dem Studium von XPath zu beginnen, um mit dem Crawling zu starten!
Lesen Sie auch:
Daten sammeln, jetzt automatisieren
Beginnen Sie in 5 Minuten ohne Programmierung · Erfahrung mit dem Crawlen von über 5.000 Websites



