

0. 概述
在XPath第1部分中,我们讨论了在网络爬虫中必不可少的XPath概念和基本语法,而在第2部分中,我们将介绍XPath的深入内容。
1. 通配符理解
在深入内容之前,有必要理解XPath中“*(通配符)”的含义。
- (通配符)在XPath中匹配任何元素,并用于选择所有元素。让我们通过示例来说明。
//div[contains(@class, "aa")]
上面的XPath表示选择具有包含'aa'的class名称的div元素。那么如果使用通配符代替div会怎样呢?
//*[contains(@class, "aa")]
在上面的XPath中,‘*’匹配所有元素,因此该XPath表示选择所有具有包含'aa'的class名称的元素。
2. XPath层次结构理解
现在让我们深入了解XPath的内容。
以下是一个简单的HTML代码示例。
<AAA>
<BBB>
<CCC/>
<DDD/>
</BBB>
<EEE>
<FFF>
<GGG/>
<GGG/>
<III>
<JJJ/>
</III>
</FFF>
</EEE>
<KKK>
<LLL/>
</KKK>
</AAA>
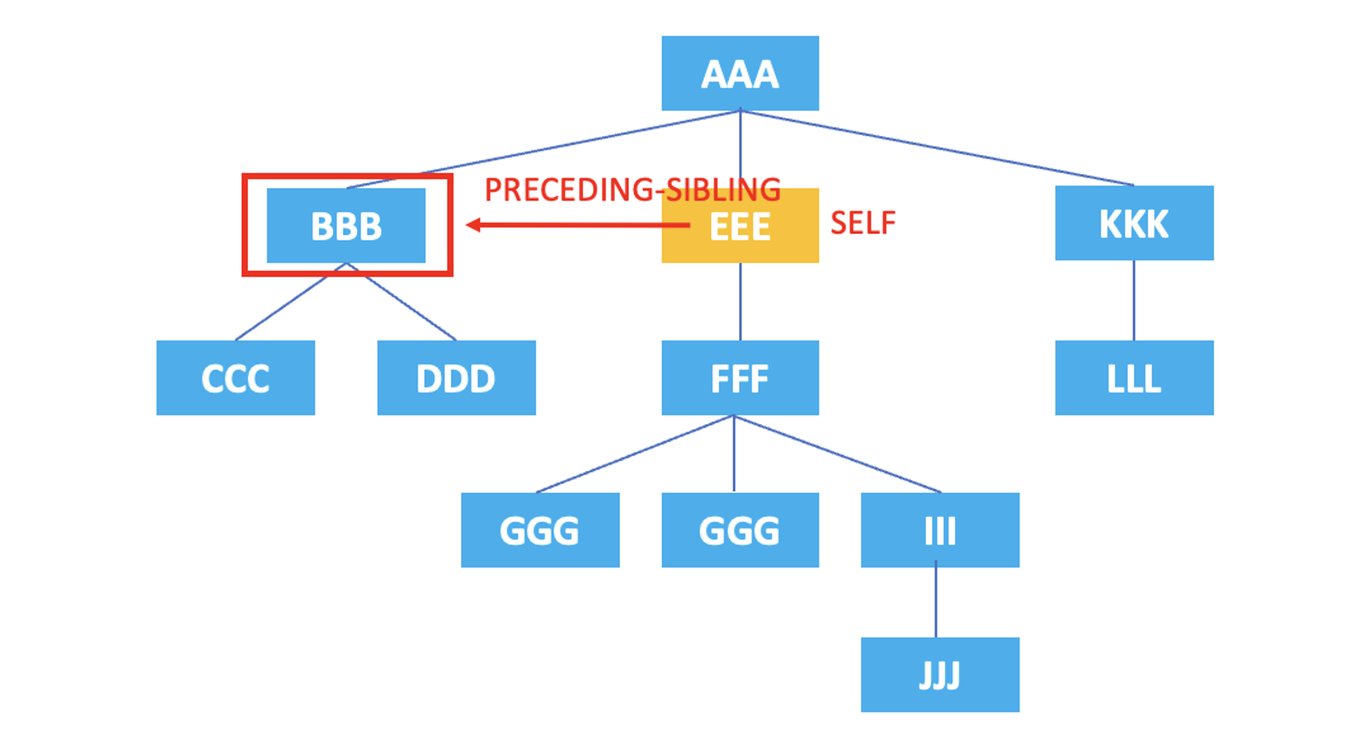
HTML代码中的每个元素和属性都形成层次关系,在XPath中,这种层次关系以树形结构表示。轴用于表示在树结构中引用和选择节点(数据点,单位)的方向或关系。轴包括self轴,parent轴,child轴等,我们将逐个使用示例进行说明。
将上述元素的层次结构绘制成图如下。
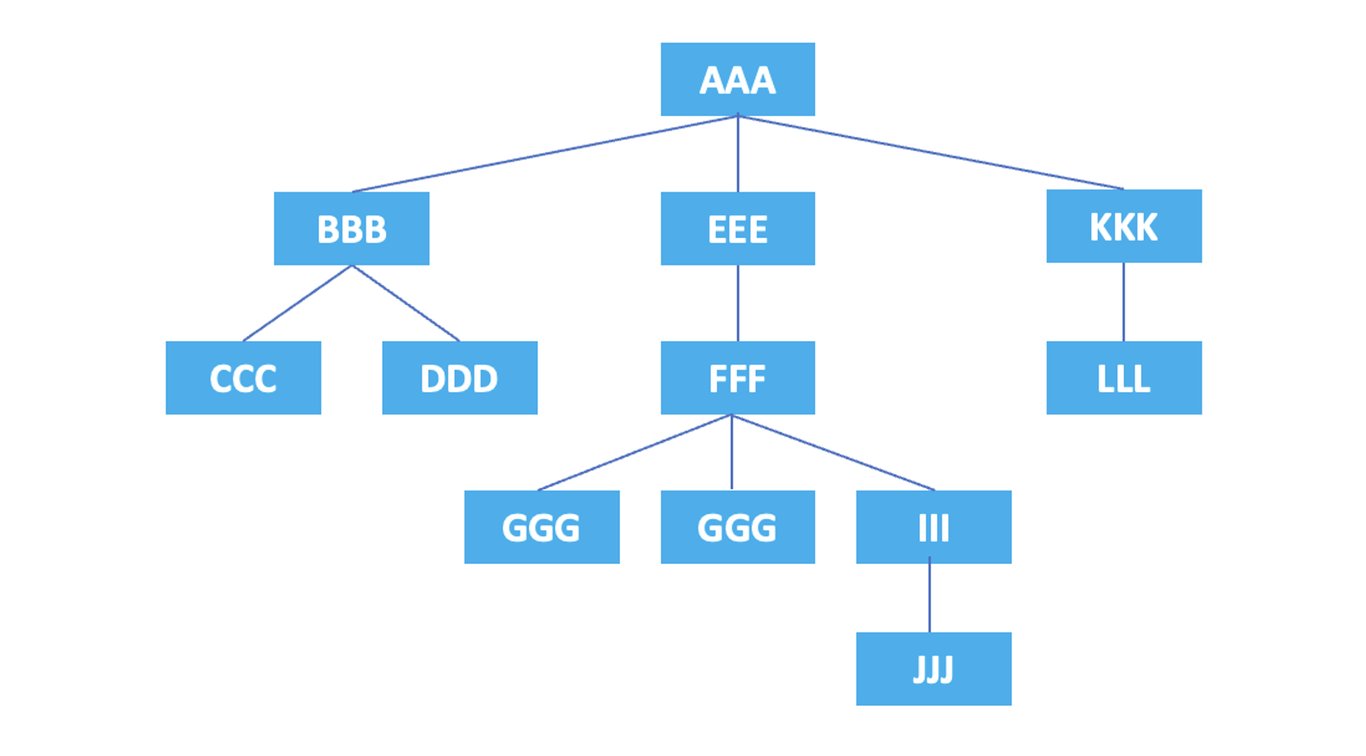
现在让我们通过使用轴来了解如何表示节点。
3. 节点的表示方法
3.1. self
: 表示当前节点本身。
/AAA/self::*
上面的XPath将选择当前节点<AAA>元素。
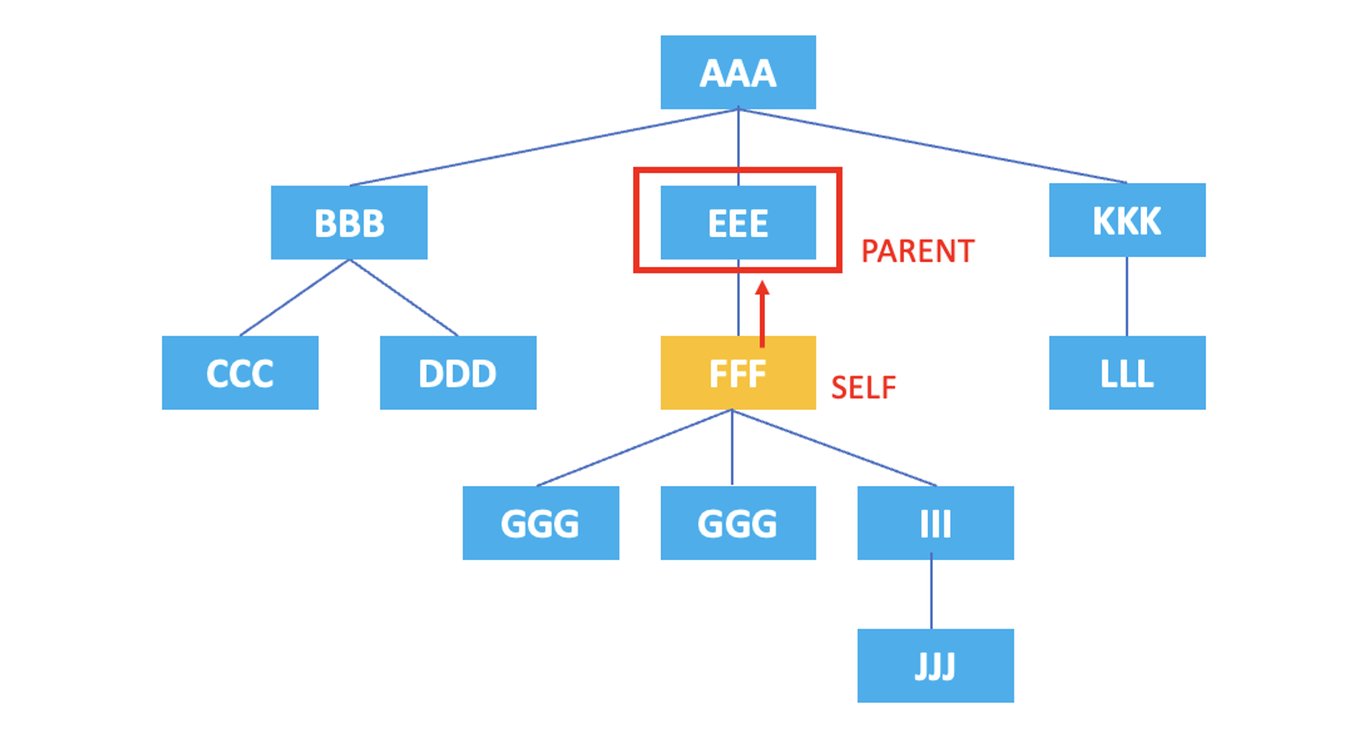
3.2. parent
: 表示当前节点的父节点。
/AAA/EEE/FFF/parent::*
上面的XPath将选择当前节点<FFF>元素的父节点<EEE>元素。
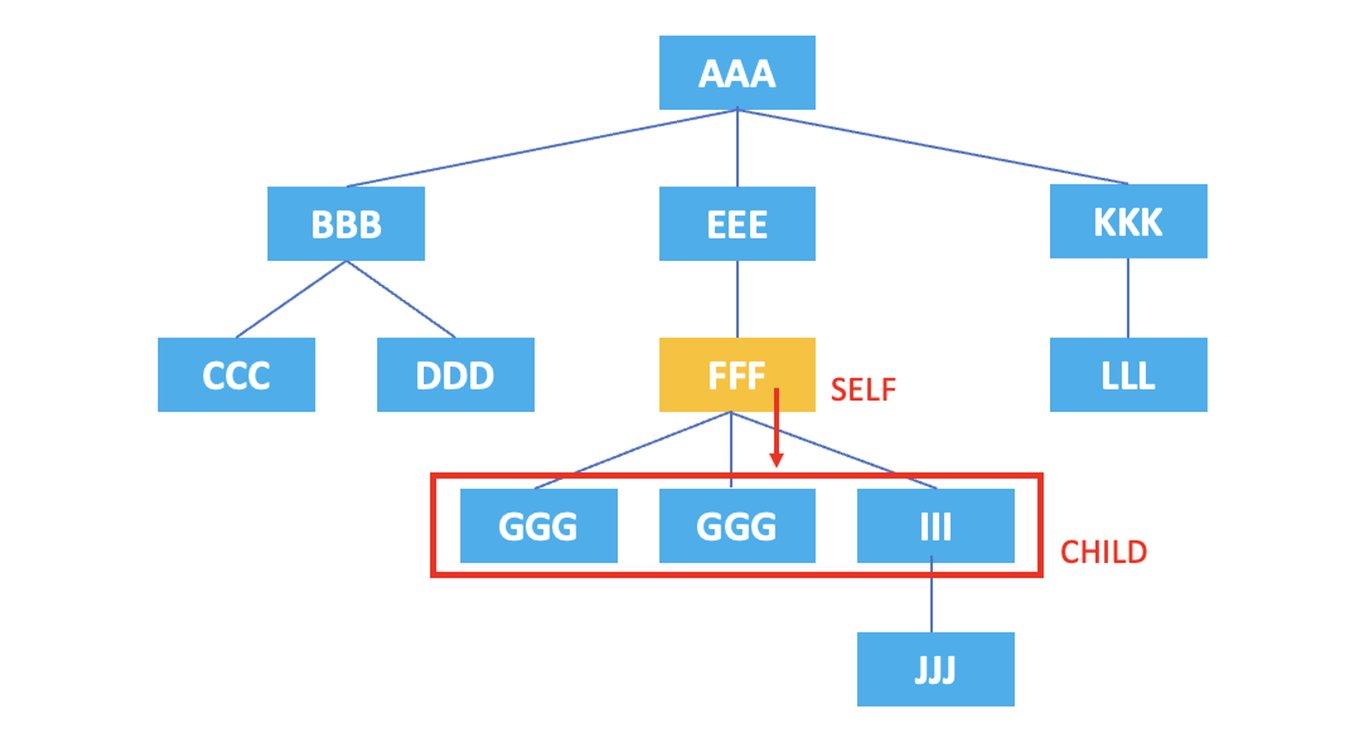
3.3. child : 表示当前节点的子节点。
/AAA/EEE/FFF/child::*
上面的XPath将选择当前节点<FFF>元素的子节点<GGG>, <GGG>, <III>。
如果想要仅选择<III>元素,可以修改XPath如下。
/AAA/EEE/FFF/child::III
此外,如果想要选择两个<GGG>元素中的第一个<GGG>元素,可以修改XPath如下。
/AAA/EEE/FFF/child::GGG[1]
需要注意的是,与大多数其他编程语言不同,XPath中的索引从1开始!
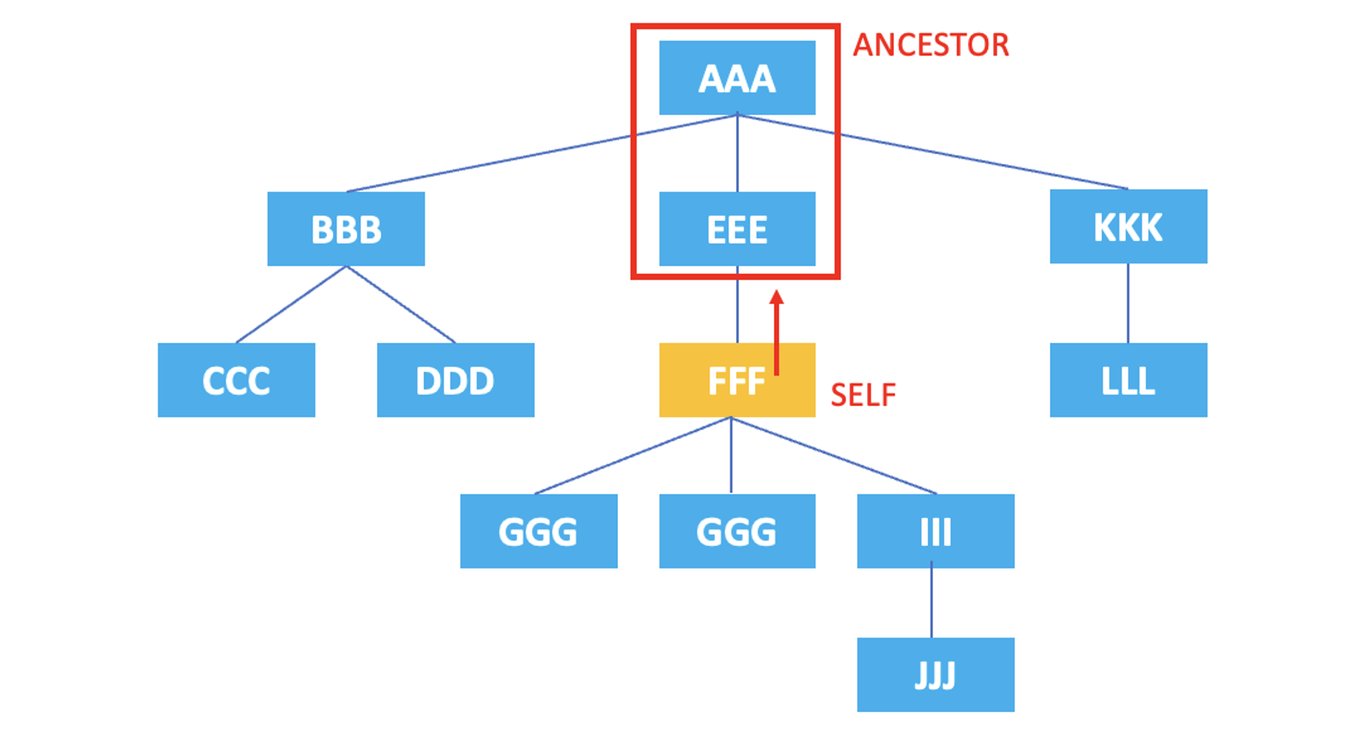
3.3. ancestor
: 表示当前节点的所有祖先节点。
/AAA/EEE/FFF/ancestor::*
上面的XPath将选择当前节点<FFF>元素的祖先节点<EEE>, <AAA>。
3.4. descendant
: 表示当前节点的所有后代节点。
/AAA/EEE/FFF/descendant::*
上面的XPath将选择当前节点<FFF>元素的后代节点<GGG>, <GGG>, <III>, <JJJ>。
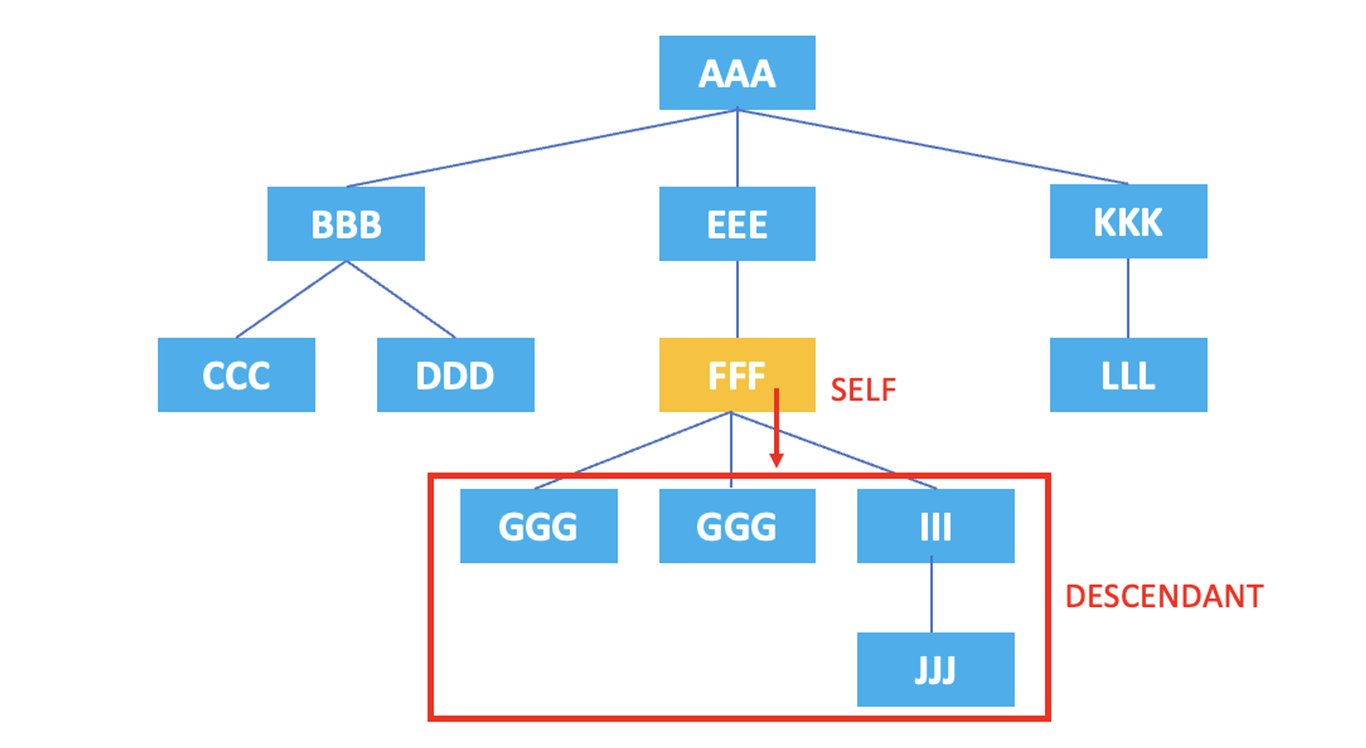
3.5. ancestor-or-self
: 表示当前节点及其所有祖先节点。
/AAA/EEE/FFF/ancestor-or-self::*
上面的XPath将选择当前节点<FFF>元素本身及其祖先节点<FFF>, <EEE>, <AAA>。
3.6. descendant-or-self
: 表示当前节点及其所有后代节点。
/AAA/EEE/FFF/descendant-or-self::*
上面的XPath将选择当前节点<FFF>元素本身及其后代节点<FFF>, <GGG>, <GGG>, <III>, <JJJ>。
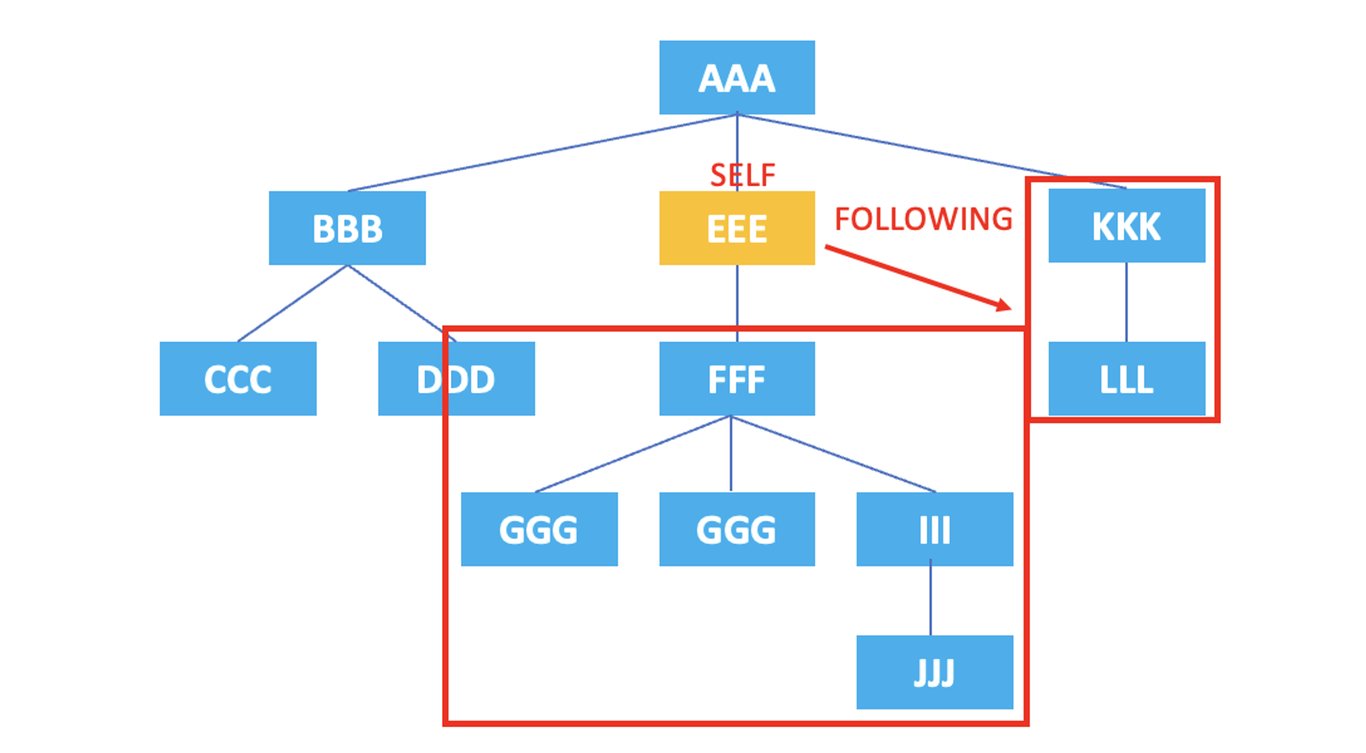
3.7. following
: 表示当前节点结束标记后的所有节点。
/AAA/EEE/following::*
上面的XPath将选择当前节点<EEE>结束后出现的节点<FFF>, <GGG>, <GGG>, <III>, <JJJ>, <KKK>, <LLL>。
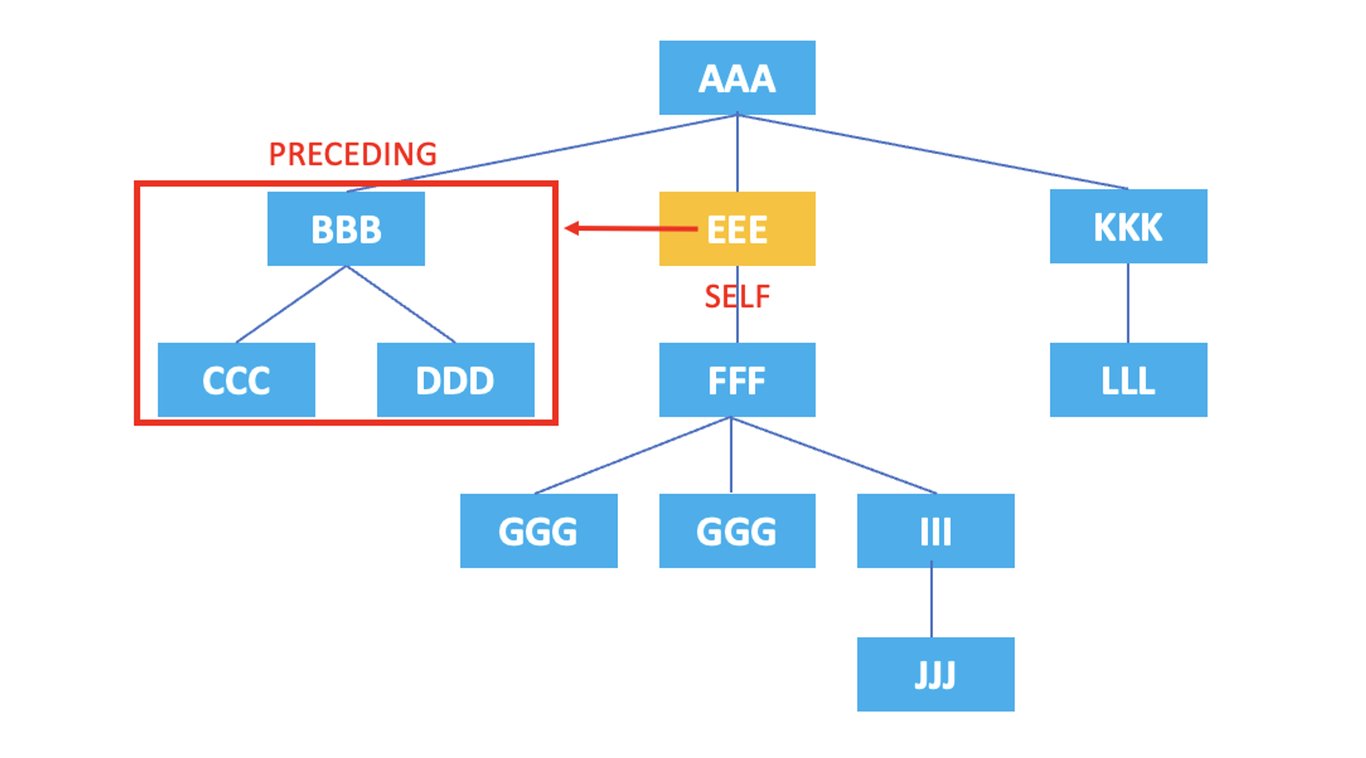
3.8. preceding
: 表示当前节点开始标记前出现的所有节点。
/AAA/EEE/preceding::*
上面的XPath将选择当前节点<EEE>之前出现的节点<BBB>, <CCC>, <DDD>。
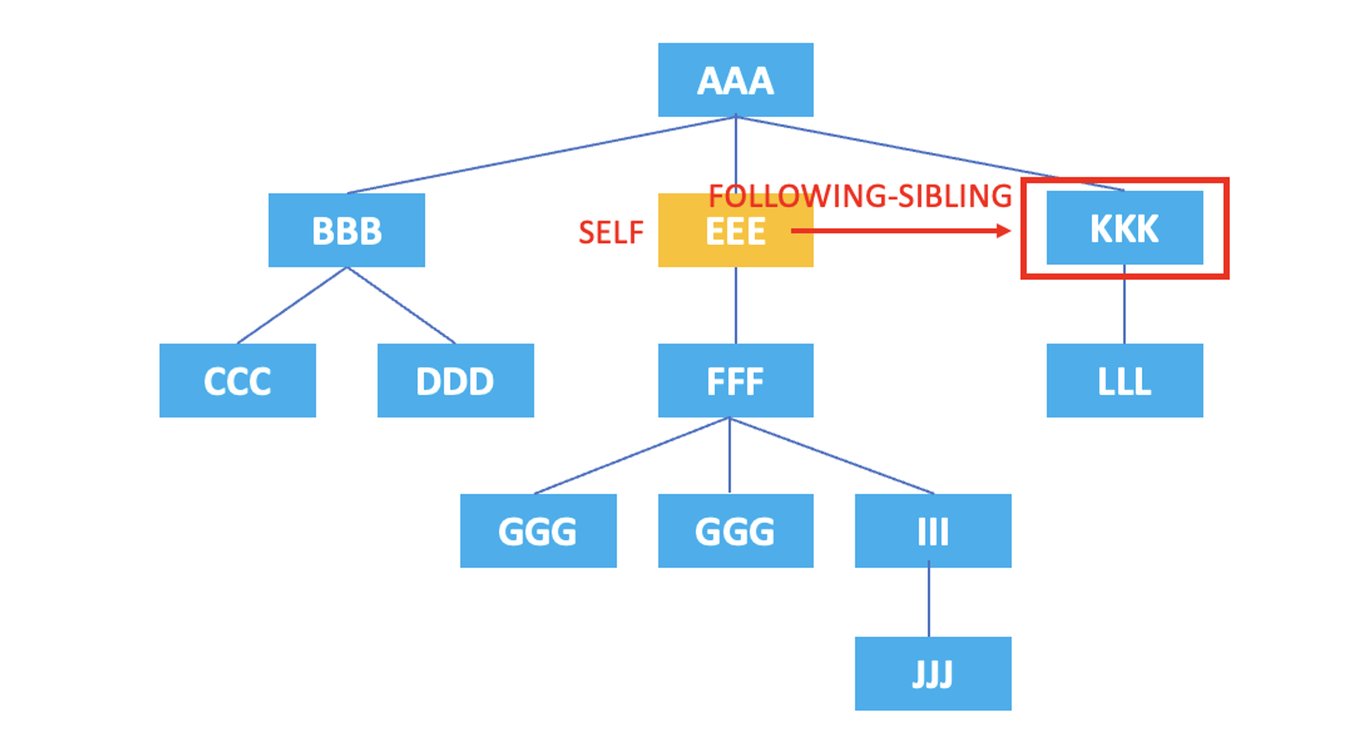
3.9. following-sibling
: 表示当前节点后续的所有同级节点。
/AAA/EEE/following-sibling::*
上面的XPath将选择当前节点<EEE>后续的同级节点<KKK>。
3.10. preceding-sibling
: 表示当前节点之前的所有同级节点。
/AAA/EEE/preceding-sibling::*
上面的XPath将选择当前节点<EEE>之前的同级节点<BBB>。
到目前为止,我们已经了解了XPath中用于表示节点的轴。
接下来,让我们了解另外两个可用于XPath的函数。
4. 用于XPath的函数
4.1. count
: 返回符合特定条件的节点数。
#class 속성 값이 ‘example인 div 요소의 개수를 반환
count(//div[@class="example"])
#p 요소의 총 개수를 반환
count(//p)
4.2. position
: 返回当前节点的位置。(位置从1开始逐渐增加)
<root>
<item>Item 1</item>
<item>Item 2</item>
<item>Item 3</item>
</root>
例如,当存在以下xml代码时,可以编写如下XPath。
//item[position() = 2]
使用position函数可以选择三个item元素中的第二个item元素。
5. 结论
到目前为止,我们已经了解了XPath的深入内容。如果您从基础到深入都掌握了,那么您现在应该已经掌握了在XML文档中精确查找并提取数据所需的基本知识。
XPath是浏览和操作XML文档的强大工具,在实际工作中被广泛应用于数据抓取、网络抓取、基于XML的Web服务中的数据提取等各种领域。希望您能成功地使用XPath有效地提取和利用数据!
请阅读以下文章:
数据收集,现在自动化
无需编码,5分钟即可开始 · 5000多个网站爬取经验



