

0. XPath是什么?
XPath是“XML路径语言”的缩写,用于指定访问XML文档特定元素或属性的路径的语言。
XPath通常用于网络爬虫任务,首先让我们了解XPath的基本语法。
1. Xpath的基本语法
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>hashscraper</title>
</head>
<body>
<div id="container">
<div class="title">
<p class="content1">let's start crawling!</p>
<p class="content2">crawling is fun!</p>
</div>
</div>
</body>
</html>
2. HTML代码
以下是简单的HTML代码。
HTML代码由元素(element)和属性(attribute)组成,每个元素和属性都形成层次关系。
XPath将XML文档表示为树结构,从顶级节点到最底层节点,显示可以提取所有节点、属性和数据的路径。
(*在这里,“节点”指的是XML文档的各个部分,如元素、属性、文本内容等。)
让我们尝试获取访问标题元素的路径。
在树结构中,标题元素的顺序为html元素 → head元素 → 标题元素。
因此,标题元素的XPath如下所示。
/html/head/title
此外,XPath使用“@”表示与元素相关联的属性,使用@来表示在上述代码中第一个p元素的XPath如下所示。
/html/body/div/div/p[@class='content1']
3. Xpath的两种表示方法
XPath可以以两种方式表示,绝对路径和相对路径。
3.1. Xpath:绝对路径
绝对路径与上述使用的方式相同,从最顶层的根节点开始选择元素的方式。
html/body/div/div/p[@class='content1']
3.2. Xpath:相对路径
相对路径使用“//”跳过中间节点路径,并从指定节点开始按顺序搜索。将上述绝对路径表示为相对路径如下。
//p[@class='content1']
4. 其他表达语法
除了这些,XPath还使用各种语法来表示路径。
4.1. 包含
:获取包含该值的情况。
#'aa'를 포함하는 class명을 가진 div 요소를 선택
//div[contains(@class, "aa")]
4.2. 最后
:获取与路径匹配的节点中的最后一个节点。
//div[@class="aa")/span[last()]
4.3. 并且
:获取同时满足两个条件的节点。
#class명에 'aa'와 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") and contains(@class, "bb")]
4.4. 或
:获取满足两个条件中的一个或多个条件的节点。
#class명에 'aa' 또는 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") or contains(@class, "bb")]
4.5. 非
:获取不满足该条件的节点。
#class명에 'aa'를 포함하고 'bb'를 포함하지 않는 img 요소를 선택
//img[contains(@class, "aa") and not(contains(@class, "bb")
5. 示例实践
到目前为止,我们已经了解了XPath的基本语法。现在让我们尝试从网站中获取我想要的XPath。
5.1. 打开开发者工具
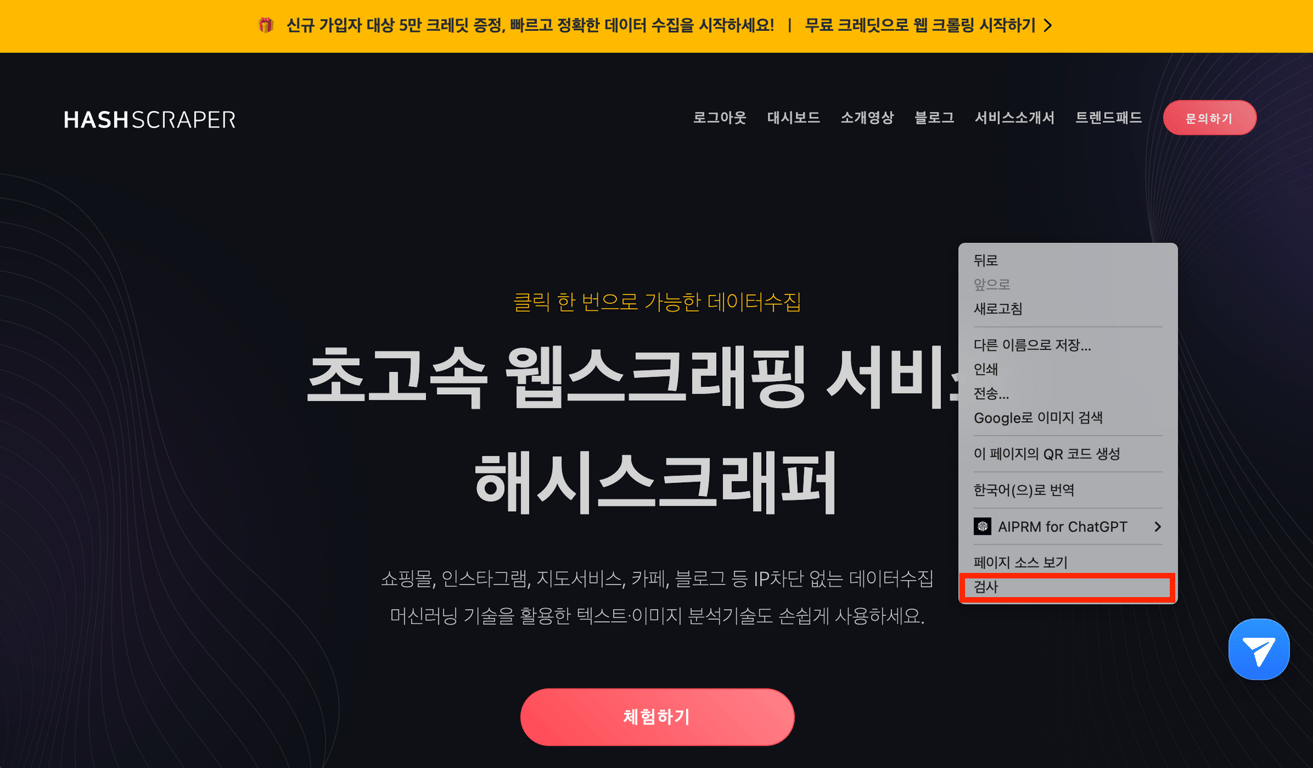
首先打开所需的网站,然后单击鼠标左键并按“检查”按钮,您将看到Chrome开发者工具已打开。
5.2. 确认所需标签
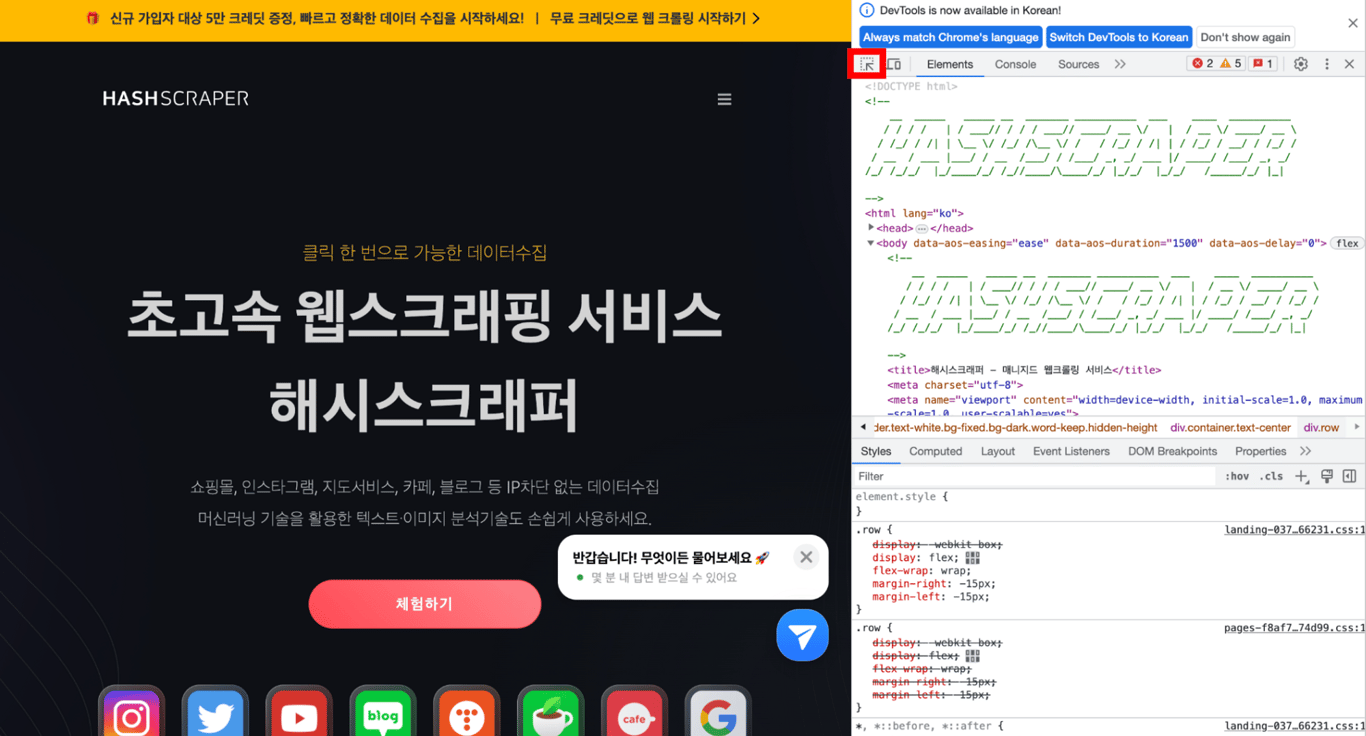
在开发者工具中,单击左上角的鼠标图标。然后将鼠标悬停在要提取的网站部分上方,将显示如下内容。
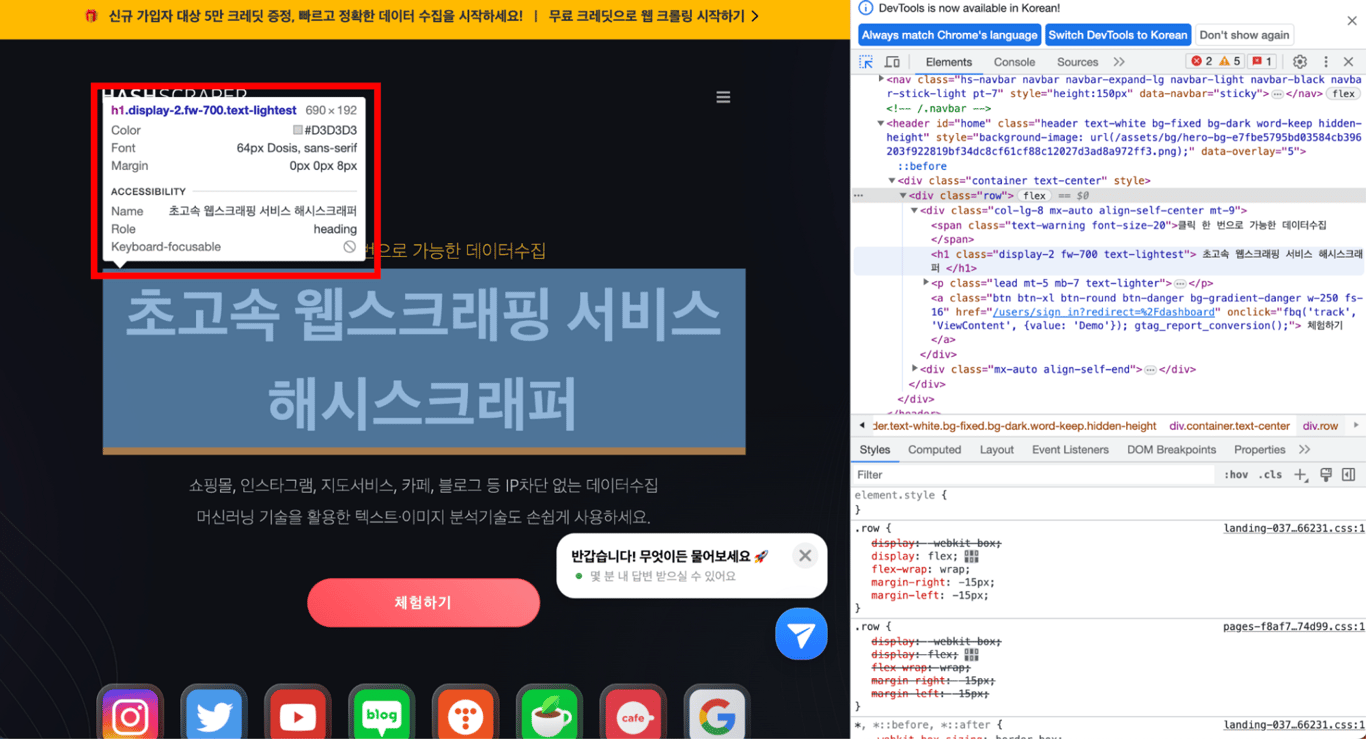
单击鼠标指向的位置,开发者工具将显示实际的html代码中我想要的部分标签。
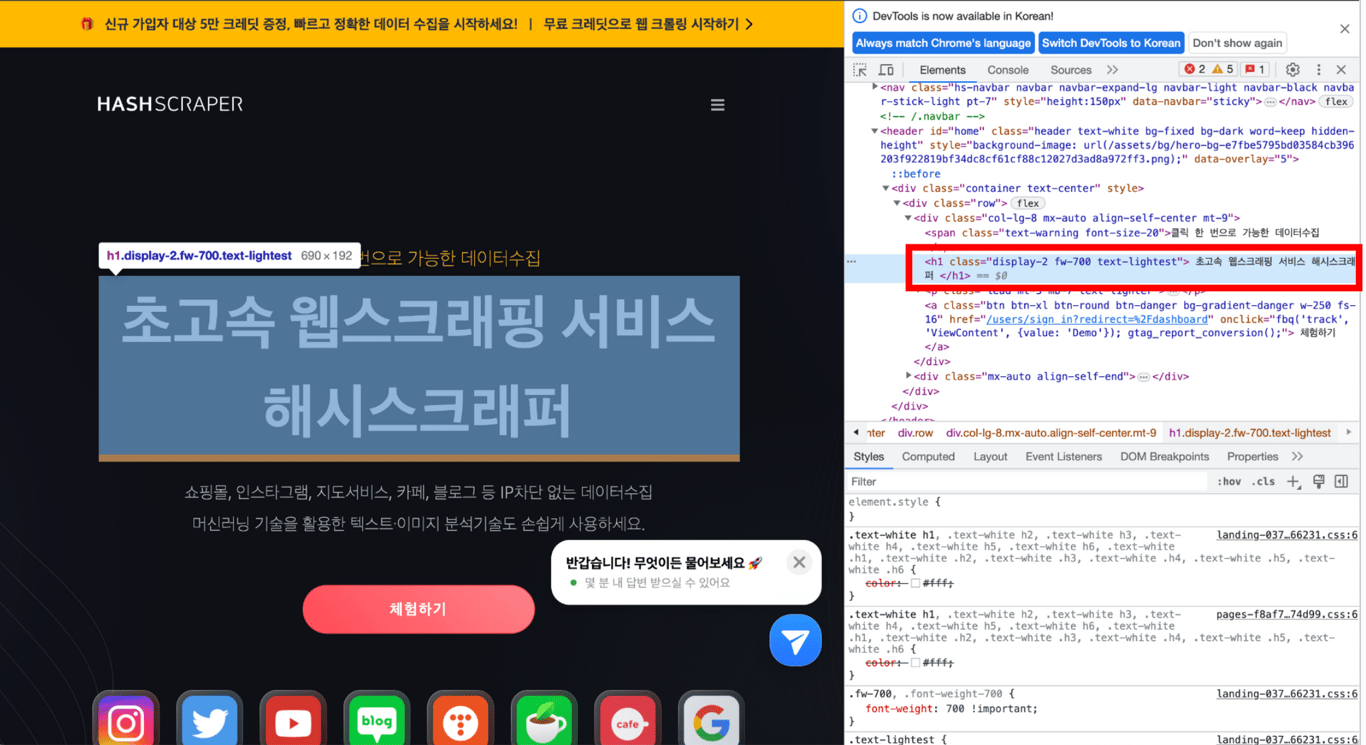
5.3. 复制XPath
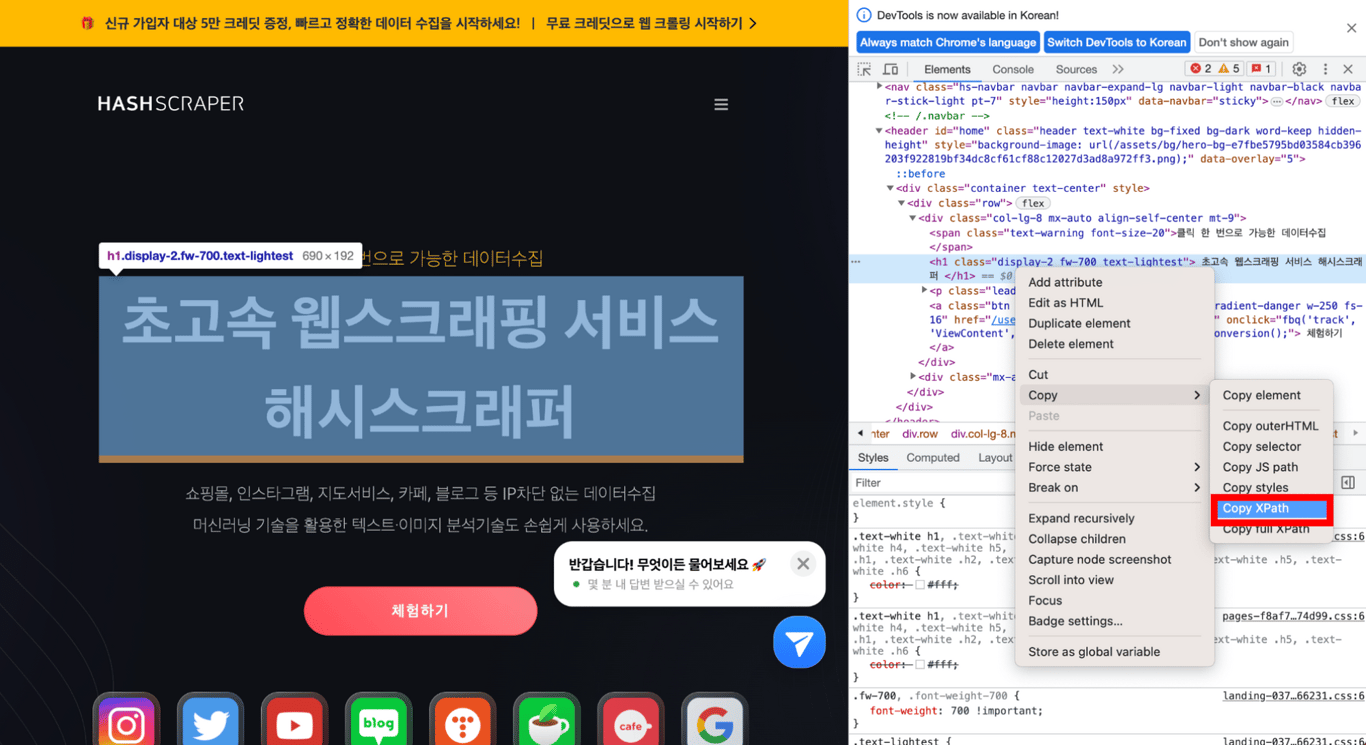
复制所需部分,然后粘贴复制的内容,您将获得所需部分的XPath!
您可以确认已成功移动到所需部分的XPath。
//*[@id="home"]/div/div/div[1]/h1
那么,获取的XPath如何用于网络爬虫?以下是爬虫代码的一部分。
get_browser.goto "<https://www.hashscraper.com>"
x = get_browser.element(xpath: "//*[@id='home']/div/div/div[1]/h1").text
5.4. 确认操作
通过使用XPath获取所需元素并将其存储在x中,然后打印x,您将看到所需文本的输出。
6. 结论:要进行正确的网络爬虫,首先学习XPath
到目前为止,我们已经了解了网络爬虫的基础知识,XPath。为了收集所需数据,您需要了解数据可能通过哪些路径表示,而XPath可以简单地表示这一点。我们建议您从学习XPath开始,然后开始网络爬虫!
也一起阅读:
数据收集,现在自动化
开始无需编码,5分钟即可开始 · 5000多个网站爬取经验



