

0. Überblick
Hashscraper hat ein Kundenbeispiel, bei dem ein KI-Modell verwendet wurde, um die Fehlerquote in der Produktion zu reduzieren. Ich habe diesen Text verfasst, um die Vorhersagen des Machine-Learning-Modells verständlicher zu erklären.
1. Problemdefinition
1.1. Zielsetzung
Kurz gesagt, basierend auf 128 Variablen in den Daten, gab es Unterschiede in den Fehlerquoten für jedes Gerät, das zur Herstellung von Produkten verwendet wurde. Das Ziel bestand darin, nach der Vorhersage von fehlerhaften Produkten durch ein Machine-Learning-Modell zu analysieren, welche Variablen die Fehler verursacht haben, und diese Variablen anzupassen, um die Fehlerquote zu reduzieren.
1.2. Hypothesenbildung
Wir haben die Hypothese aufgestellt, dass die Anpassung der Hauptvariablen im Produktionsprozess mithilfe eines Machine-Learning-Modells die Fehlerquote senken wird.
2. Datensammlung
2.1. Festlegung der Datenquelle
Unsere Kunden haben uns direkt Daten von jedem Gerät in der Fabrik zur Verfügung gestellt. Da es sich um interne Unternehmensdaten handelt, ist eine direkte Offenlegung schwierig, daher zeige ich nur einen Screenshot des Ordners.
2.2. Datensammlung
Wir haben um mindestens 10.000 Datensätze gebeten und darum gebeten, so viele Daten wie möglich bereitzustellen. Die erhaltenen Rohdaten betragen 3931 für Gerät 1, 16473 für Gerät 2, 2072 für Gerät 3, 16129 für Gerät 4, 57970 für Gerät 5 und 78781 für Gerät 6. Insgesamt haben wir ungefähr 175.000 Datenzeilen verwendet, um das Modell zu trainieren.
3. Datenbereinigung
3.3. Datenbereinigung
Die Datenbereinigung ist äußerst wichtig für das Training des Modells. Ich würde sagen, dass mehr als 80% des Machine-Learning-Lernens auf der Datenbereinigung beruhen. Wenn schlecht bereinigte Daten zum Training verwendet werden, führt dies letztendlich zu einem schlecht lernenden Modell. (Einfach ausgedrückt: Wenn Sie Müll hineingeben, erhalten Sie Müll als Ergebnis.)
3.4. Arbeitsablauf
3.4.1.
Zunächst habe ich die Dateien geladen und sie in verschiedenen Encoding-Formaten wie 'cp949' und 'utf-8' gelesen.
for file_path in file_paths:
try:
df = pd.read_csv(file_path, encoding='cp949', header=None)
except UnicodeDecodeError:
df = pd.read_csv(file_path, encoding='utf-8', header=None)
3.4.2.
Um Labeling durchzuführen, habe ich Datum und Uhrzeit kombiniert und mit den y-Achsendaten verknüpft.
for i in range(len(result_df_new) - 1):
start_time, end_time = result_df_new['Datetime'].iloc[i], result_df_new['Datetime'].iloc[i + 1]
selected_rows = df_yaxis[(df_yaxis['Datetime'] >= start_time) & (df_yaxis['Datetime'] < end_time)]
results.append(1 if all(selected_rows['결과'].str.contains('OK')) else 0)
results.append(0)
3.4.3.
Zusammenführen der vorverarbeiteten Daten für jedes Gerät.
data = pd.concat([df1,df2,df3,df4,df6])
data.reset_index(drop=True,inplace=True)
3.4.4
Doppelte Daten können eine Verzerrung im Datensatz verursachen und das Modell daran hindern, die Vielfalt der Daten zu lernen. Außerdem kann dies zu Overfitting führen, daher wurden alle doppelten Daten entfernt.
data = data.drop_duplicates().reset_index(drop=True)
Nach dieser Art der Vorverarbeitung habe ich eine gewisse explorative Datenanalyse durchgeführt.
3.4.5.
Ich habe fehlende Werte mit der missingno-Bibliothek visualisiert. Spalten mit vielen fehlenden Werten wurden vollständig entfernt. Das Entfernen von Spalten mit vielen fehlenden Werten erfolgt aus ähnlichen Gründen wie zuvor erwähnt. Es kann zu Problemen bei der Vielfalt der Daten und Overfitting führen. Natürlich können fehlende Werte je nach analysierten Daten wichtige Werte sein.
3.5. Feature Engineering
Feature Engineering beinhaltet die Erstellung neuer Features oder die Transformation vorhandener Features, um die Leistung des Modells zu verbessern. Da wir nicht genau wussten, was jeder einzelne Feature bedeutet und alle Features als wichtig erachteten, haben wir kein spezielles Feature Engineering durchgeführt.
3.6. EDA (Die unten gezeigten Bilder zeigen aus Sicherheitsgründen nur einen Teil)
Überprüfung der Datenverteilung
Durch die Verwendung von Histogrammen, Boxplots usw. wird die Datenverteilung überprüft.
.png?table=block&id=74533625-35d7-4939-96b3-60c4b3763ea6&cache=v2)

Korrelationsanalyse
Durch die Analyse der Korrelationen zwischen den Features werden wichtige Features identifiziert oder das Problem der Multikollinearität gelöst.
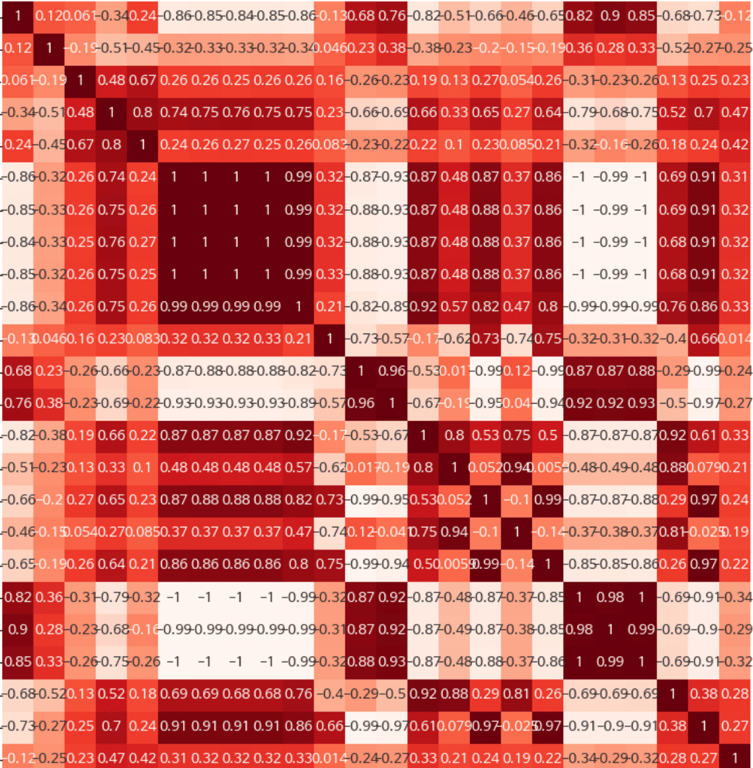
4. Sampling-Typen
4.1. Datenungleichgewicht
Aufgrund erheblicher Datenungleichgewichte haben wir verschiedene Modelle mit Undersampling kombiniert. Der Hauptgrund für Undersampling bei erheblichem Ungleichgewicht besteht darin, dass das Overfitting das größte Problem darstellt. Unser Hauptziel war es, sicherzustellen, dass das Modell ohne Verzerrung auf bestimmte Daten lernt. Random Under-sampling (RUS): Entfernen von Daten aus der Mehrheitsklasse, um das Klassenungleichgewicht zu beheben. Es ist einfach und schnell zu implementieren, aber es besteht die Gefahr, dass wichtige Informationen verloren gehen.
4.2. NearMiss
Diese Methode behält nur die k nächsten Datenpunkte der Mehrheitsklasse bei, die den Daten der Minderheitsklasse am nächsten sind. Es gibt verschiedene Versionen von NearMiss, und jede Version berechnet die Distanz zur Minderheitsklasse auf unterschiedliche Weise.
4.3. Tomek Links
Es werden die nächsten Datenpunkte zwischen den Datenpaaren der Minderheits- und Mehrheitsklasse gefunden, und die Daten der Mehrheitsklasse werden entfernt. Dadurch werden die Grenzen zwischen den Klassen klarer definiert.
4.4. Edited Nearest Neighbors (ENN)
Für alle Datenpunkte der Mehrheitsklasse wird der k-NN-Algorithmus angewendet, und wenn die meisten nächsten Nachbarn zur Minderheitsklasse gehören, werden diese Daten entfernt.
4.5. Neighbourhood Cleaning Rule (NCL)
Eine erweiterte Version von ENN, die Daten der Mehrheitsklasse effektiver entfernt, um die Umgebung der Minderheitsklasse sauber zu halten.
Wir haben verschiedene Arten von Undersampling ausprobiert und auch eine Kombination aus Undersampling und Oversampling versucht. Letztendlich haben wir festgestellt, dass ENN Undersampling am besten zu unserem Modell passt und haben es angewendet.
##### NearMiss 인스턴스 생성
nm = NearMiss()
##### 언더샘플링 수행
X_resampled, y_resampled = nm.fit_resample(data.drop('결과', axis=1), data['결과'])
##### 언더샘플링 결과를 DataFrame으로 변환
data_sample = pd.concat([X_resampled, y_resampled], axis=1)
5. Modellierung
5.1. Modellauswahl
Je nach Art des Problems (Klassifizierung, Regression, Clustering usw.) wird das geeignete Machine-Learning-Modell ausgewählt.
Bei der Modellauswahl haben wir verschiedene Modelle getestet, aber auch auf das von pycaret ausgewählte beste Modell zurückgegriffen. PyCaret ist eine Open-Source-Bibliothek für Datenanalyse und automatisiertes Machine Learning in Python. PyCaret ermöglicht es Benutzern, mit minimalem Codeaufwand eine vollständige Datenanalyse- und Machine-Learning-Pipeline schnell aufzubauen und zu experimentieren.
5.2. Modelltraining
Das Modell wird mit Trainingsdaten trainiert.
Letztendlich ergab die Verwendung des CatBoost-Modells die höchsten AUC- und F1-Score-Werte.
- AUC (Fläche unter der Kurve):
AUC steht für den Bereich unter der ROC (Receiver Operating Characteristic) Kurve.
Die ROC-Kurve wird mit der Empfindlichkeit (True Positive Rate) auf der y-Achse und 1-Spezifität (False Positive Rate) auf der x-Achse gezeichnet.
Der AUC-Wert liegt zwischen 0 und 1, wobei ein Wert nahe 1 auf eine gute Leistung des Klassifikators hinweist. Ein Wert von 0,5 entspricht einer zufälligen Klassifikation.
AUC ist besonders nützlich bei ungleichen Klassenverteilungen.
- F1-Score:
Der F1-Score ist das harmonische Mittel aus Präzision (Precision) und Recall.
Präzision ist das Verhältnis der korrekten positiven Vorhersagen zur Gesamtzahl der positiven Vorhersagen, während Recall das Verhältnis der korrekten positiven Vorhersagen zur Gesamtzahl der tatsächlich positiven Fälle ist.
Der F1-Score liegt zwischen 0 und 1, wobei ein höherer Wert auf eine bessere Leistung des Modells hinweist.
6. Abschluss: Ableitung von Variablen und Hinzufügen von Funktionen zur Verbesserung der Anschaulichkeit
Letztendlich haben wir die Rohdaten, die von den Maschinen in der Fabrik generiert werden, in Echtzeit erhalten und mithilfe dieses Modells Vorhersagen getroffen. Mit der SHAP-Bibliothek haben wir die Variablen für fehlerhafte Produkte abgeleitet.
Zusätzlich haben wir für die Arbeiter in der Fabrik einen einfachen Excel-Exportprozess implementiert, der es ihnen ermöglicht, die Ergebnisse mit einem Klick anzuzeigen. Durch die Verwendung von Pyinstaller haben wir eine EXE-Datei erstellt, mit der die Arbeiter die Variablen und die Entscheidung über fehlerhafte Produkte in den Rohdaten leicht einsehen können.
SHAP - Was ist das?
SHAP steht für SHapley Additive exPlanations und wird verwendet, um zu erklären, wie stark jedes Feature eines Machine-Learning-Modells die Vorhersagen beeinflusst. Dies erhöht die "Transparenz" des Modells und verbessert das Vertrauen in die Art und Weise, wie Vorhersagen getroffen werden.
Hashscraper führt Projekte basierend auf dem oben genannten Ansatz mit KI-Modellen durch.
Lesen Sie auch:
Datensammlung, jetzt automatisieren
Starten Sie in 5 Minuten ohne Codierung · Erfahrung mit über 5.000 Website-Scrapings



