

0. Überblick
Heutzutage ist es dank ChatGPT wirklich einfach geworden, zu entwickeln.
Kann ein Crawling-Bot auch einfach mit ChatGPT erstellt werden?
Lassen Sie uns mit der Entwicklung eines Coupang-Crawling-Bots (mit ChatGPT) beginnen.
1. Prompt erstellen
1.1. Ziel
Ich möchte grundlegende Informationen zu jedem Produkt aus der Ergebnisliste abrufen.
Produktname
Listenpreis
Verkaufspreis
Bewertung
Anzahl der Bewertungen
Kartenrabattinformationen
Bonuspunkteinformationen
Versandinformationen
1.2. Finden der HTML-Produktliste
Lassen Sie uns das HTML-Element finden, das die Produktliste enthält.
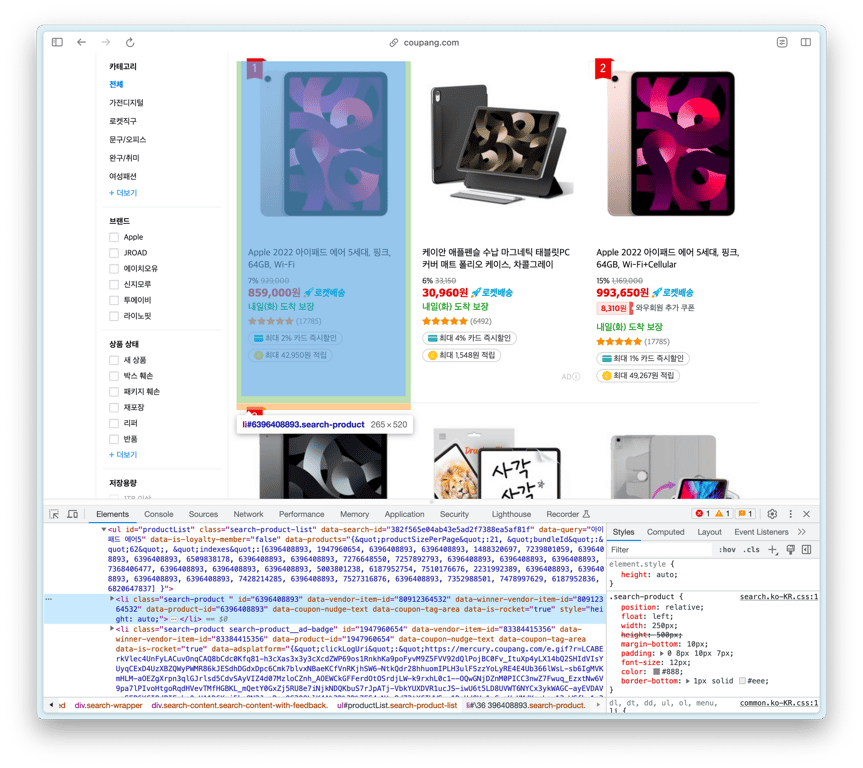
Das ul mit der ID productList ist die Produktliste, und jedes li darin ist ein Produktelelement.
Lassen Sie uns also das oben genannte ul-HTML kopieren und ChatGPT danach fragen.
1.3. HTML-Größenreduzierung

ChatGPT hat eine Tokenbeschränkung, daher kann es nicht mit zu großen HTML-Dateien wie dem obigen ul umgehen.
Wir müssen die Größe des HTML reduzieren, also kopieren wir das erste li-HTML des ul erneut.
1.4. Überlegungen zur Prompterstellung
Bevor wir den Prompt erstellen, lassen Sie uns überlegen, was zu berücksichtigen ist.
1⃣ Wiederholung für alle Produkte in der Produktliste
Sammeln Sie alle Produkte innerhalb von //ul[@id="productList"].
2⃣ Werbung entfernen
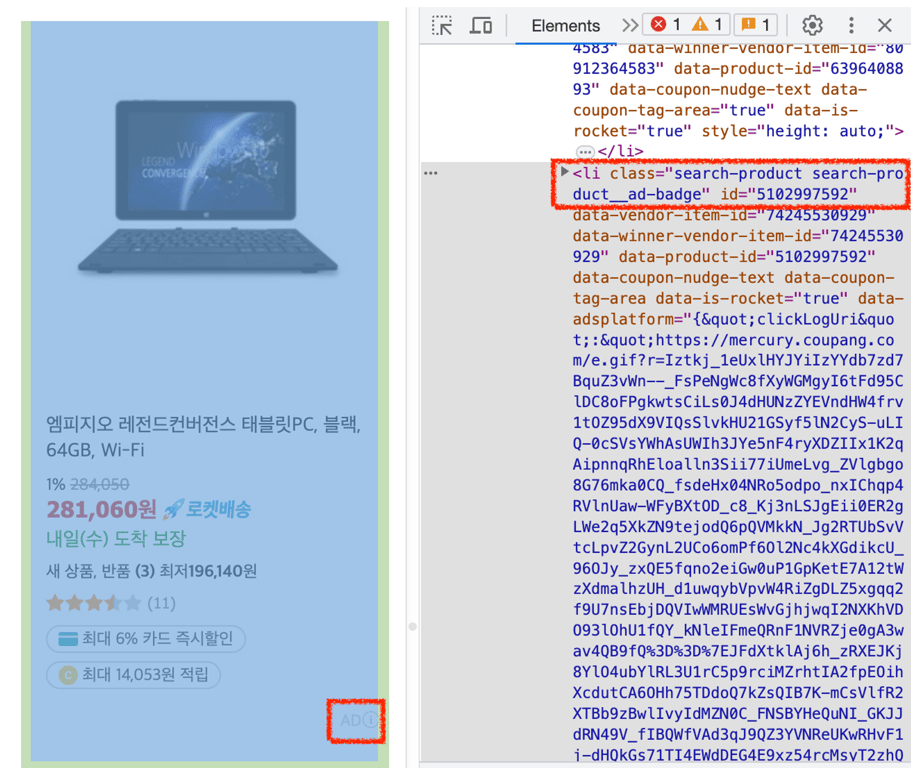
Wenn die Klasse search-product__ad-badge enthält, handelt es sich um ein Werbeprodukt, das nicht gesammelt werden sollte.
1.5. Erstellung des Prompts für ChatGPT
Ich habe GPT-4 verwendet und den Prompt wie folgt eingegeben.
<<li의 HTML>>
상품 정보를 담고 있는 위의 HTML에서 상품 이름, 가격, 정가, 별점, 리뷰 개수, 카드 할인, 적립 정보, 배송 정보를 가져오는 웹 크롤러를 셀레니움을 사용하여 만들어 줘.
이 li 요소는 "//ul[@id='productList']" 안에 있으므로, 상품 리스트를 가져와 그 안의 li 태그에 대해 수집 작업을 반복하도록 코드를 생성해 줘.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
수집 내용을 콘솔에 출력할 때 각 상품마다 서로 구별될 수 있도록 구분선을 추가해 줘.
1.6. ChatGPT-Codierungsergebnis
## import 및 크롬 드라이버 설정 생략 ##
# 웹페이지 열기
driver.get('<https://www.coupang.com/np/search?component=&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&channel=auto>')
# 상품 리스트 가져오기
product_list = driver.find_element(By.XPATH, "//ul[@id='productList']")
# BeautifulSoup으로 파싱
soup = BeautifulSoup(product_list.get_attribute('outerHTML'), 'html.parser')
# 광고 상품 제외하고 각 상품 정보 가져오기
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
product_name = product.find("div", class_="name").text.strip()
original_price = product.find("del", class_="base-price").text.strip()
sale_price = product.find("strong", class_="price-value").text.strip()
rating = product.find("em", class_="rating").text.strip()
review_count = product.find("span", class_="rating-total-count").text.strip()
card_discount = product.find("span", class_="ccid-txt").text.strip() if product.find("span", class_="ccid-txt") else "N/A"
reward_info = product.find("span", class_="reward-cash-txt").text.strip() if product.find("span", class_="reward-cash-txt") else "N/A"
delivery_info = product.find("span", class_="arrival-info").text.strip()
# 콘솔에 출력
print('-'*40)
print("상품 이름:", product_name)
print("정가:", original_price)
print("판매 가격:", sale_price)
print("별점:", rating)
print("리뷰 개수:", review_count)
print("카드 할인 정보:", card_discount)
print("적립 정보:", reward_info)
print("배송 정보:", delivery_info)
driver.quit()
2. Debugging
Wenn Sie den vom ChatGPT generierten Code ausführen, wird er höchstwahrscheinlich nicht ordnungsgemäß funktionieren.
In diesem Beispiel bin ich sofort auf den folgenden Fehler gestoßen:
Traceback (most recent call last):
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 13, in <module>
AttributeError: 'NoneType' object has no attribute 'text'
Lassen Sie uns nun den Debugging-Prozess durchgehen.
2.1. AttributeError: 'NoneType' object hat kein Attribut 'text'
Problembeschreibung
Lassen Sie uns den Code überprüfen, der den Produktnamen abruft.
product_name = product.find("div", class_="name").text.strip()
Dies ist der Code, der das Element mit dem Produktnamen findet und den Text abruft.
Wenn jedoch das div mit der Klasse "name" nicht gefunden wird, wird product.find("div", class_="name") zu einem 'NoneType'-Objekt.
Da von None kein Text abgerufen werden kann, tritt der AttributeError auf.
Fehlerbehebung
Lassen Sie uns das in verschiedenen Fällen lösen.
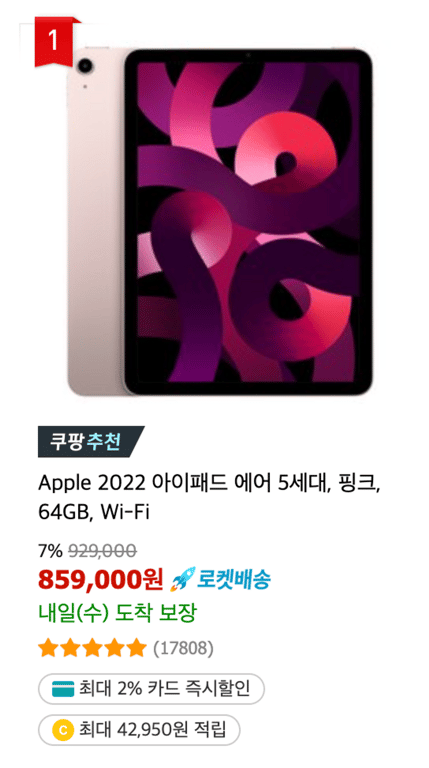
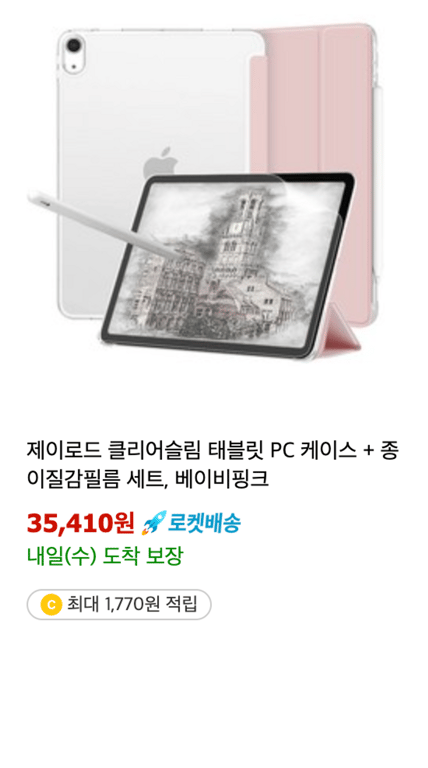
Wie Sie auf dem Bild sehen können, variiert die Menge an Informationen je nach Produkt.
Deshalb möchten wir die Informationen in zwei Kategorien aufteilen.
Erforderliche Informationen
Informationen wie Produktname und Preis müssen vorhanden sein und dürfen nicht None sein.
Wenn sie None sind, sollte ein Fehler ausgelöst werden.
try:
# 요소를 찾음
product_name = product.find("div", class_="name").text.strip()
except AttributeError:
# 에러 발생 시 raise
raise AttributeError("상품 이름을 가져오는 중 에러가 발생했습니다.")
Optionale Informationen
Für Informationen wie die Anzahl der Bewertungen, die nicht vorhanden sein müssen, benötigen wir eine andere Behandlung.
Wenn das Element mit den Informationen nicht gefunden wird, weisen wir der Variablen None zu.
# 요소를 찾음
review_count_span = product.find("span", class_="rating-total-count")
# 요소가 None이라면 변수에 None 할당
review_count = review_count_span.text.strip() if review_count_span else None
Das könnte auch in einer Zeile geschrieben werden:
review_count_span = product.find("span", class_="rating-total-count").text.strip() if product.find("span", class_="rating-total-count") else None
2.2. Überspringen von Werbeprodukten
Die Prompt enthielt diese Information.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
Daraufhin generierte ChatGPT den folgenden Code:
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
# ...후략
Problembeschreibung
Im obigen Code wird übersprungen, wenn ein Element mit der Klasse 'search-product__ad-badge' gefunden wird.
Das Problem ist, dass dies im inneren Element von product gesucht wird.
Dies scheint ein Problem zu sein, das durch meine ungenaue Prompterstellung verursacht wurde, aber lassen Sie uns versuchen, es zu lösen.
Lösung
if 'search-product__ad-badge' in product['class']:
continue
Ich habe die Bedingung in der Schleife geändert, um sicherzustellen, dass die Klasse 'search-product__ad-badge' im Klassenattribut von product enthalten ist.
2.3. Anpassung unvollständiger URLs
Nach dem Ausführen des Crawling-Bots haben wir die folgenden Produkt-URLs erhalten.
상품 URL: /vp/products/6396408893?itemId=13659935611&vendorItemId=80912364532&pickType=COU_PICK&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=c12ac6801b8042dbbe20f91a2e875bc0&rank=1
Problem
Beim Parsen von HTML mit BeautifulSoup kann es vorkommen, dass die URL im href-Attribut nicht vollständig angezeigt wird.
Wenn Sie die obige URL mit der tatsächlichen vergleichen, fehlt der Anfang https://www.coupang.com/.
Lösung
Fügen Sie den Anfang der URL hinzu.
product_url = "https://www.coupang.com" + product.find('a', class_='search-product-link')['href']
3. Überprüfung der Sammelergebnisse
Lassen Sie uns die gesammelten Daten mit dem aktualisierten Crawling-Bot überprüfen.
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/6396408893?itemId=13659935634&vendorItemId=80912364549&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=e5fbb32250614118b4a65b814ec1b9ae&rank=10>
상품 이름: Apple 2022 아이패드 에어 5세대, 스타라이트, 256GB, Wi-Fi
정가: 1,169,000
판매 가격: 1,098,860
별점: 5.0
리뷰 개수: (17833)
카드 할인 정보: 최대 1% 카드 즉시할인
적립 정보: 최대 50,000원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/1947960654?itemId=5913484902&vendorItemId=83384415356&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 케이안 애플펜슬 수납 마그네틱 태블릿PC 커버 매트 폴리오 케이스, 차콜그레이
정가: 33,150
판매 가격: 30,960
별점: 5.0
리뷰 개수: (6498)
카드 할인 정보: 최대 4% 카드 즉시할인
적립 정보: 최대 1,548원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/5540742883?itemId=8726176862&vendorItemId=79466342181&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 신지모루 애플펜슬 수납 아이패드 클리어 케이스 + 강화유리 2P, 웜그레이
정가: 26,900
판매 가격: 25,900
별점: 5.0
리뷰 개수: (1313)
카드 할인 정보: 최대 2% 카드 즉시할인
적립 정보: 최대 1,295원 적립
배송 정보: 내일(목) 도착 보장
Obwohl es sich um eine einfache Struktur eines Crawling-Bots handelt, der nur die in den Suchergebnissen angezeigten Produkte sammelt, können wir feststellen, dass wir ziemlich viele Informationen erhalten!
4. Fazit
In diesem Beitrag haben wir den Prozess des Crawlings der Suchergebnisse von Coupang mithilfe von ChatGPT untersucht. ChatGPT ist ein sehr nützliches Tool, erforderte jedoch etwas Debugging und Anpassung. Dennoch konnten wir ziemlich nützliche Ergebnisse erzielen.
Um jedoch die Suchergebnisse von Coupang reibungslos zu sammeln, müssen verschiedene Aspekte berücksichtigt werden. Coupang erkennt und blockiert Bots schnell, daher ist es wichtig, Möglichkeiten zu finden, dies effizient zu umgehen. Darüber hinaus erfordert das Sammeln von Informationen, die je nach Anmeldestatus unterschiedlich angezeigt werden, zusätzliche Arbeit. Diese Einschränkungen können das Crawling kompliziert machen und Schwierigkeiten bei der genauen und schnellen Datensammlung verursachen.
Um diese Probleme effektiv zu lösen, sind professionelle Tools und Services erforderlich. Hashscraper bietet einen spezialisierten Webscraping-Service, der diese komplexen Probleme lösen kann. Sie können problemlos und schnell eine Vielzahl von Informationen von Coupang sammeln.
In diesem Beitrag haben wir untersucht, wie man mithilfe von ChatGPT einen Webcrawler entwickelt. Es gibt viele Tools und Methoden, aber für eine effiziente und genaue Datensammlung empfehlen wir die Nutzung professioneller Services.
Vielen Dank.
Lesen Sie auch:
Daten sammeln, jetzt automatisieren
Beginnen Sie in 5 Minuten ohne Codierung · Erfahrung mit dem Crawlen von über 5.000 Websites



