

0. Qu'est-ce que XPath?
XPath est l'abréviation de 'XML Path Language', un langage qui spécifie le chemin d'accès à des éléments ou attributs spécifiques d'un document XML.
XPath est principalement utilisé dans les tâches de crawling web, examinons d'abord la syntaxe de base de XPath.
1. Syntaxe de base de XPath
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>hashscraper</title>
</head>
<body>
<div id="container">
<div class="title">
<p class="content1">let's start crawling!</p>
<p class="content2">crawling is fun!</p>
</div>
</div>
</body>
</html>
2. Code HTML
Voici un code HTML simple.
Le code HTML est composé d'éléments et d'attributs, et chaque élément et attribut forme une relation hiérarchique.
XPath représente le document XML sous forme d'arborescence et indique le chemin permettant d'extraire tous les nœuds, attributs et données du nœud le plus haut au nœud le plus bas.
(*Ici, un nœud fait référence à chaque partie du document XML telle que les éléments, les attributs, le contenu texte, etc.)
Voyons le chemin d'accès à l'élément title dans le code ci-dessus.
En termes d'ordre dans la structure arborescente, l'élément title est composé des éléments html → head → title.
Par conséquent, le chemin d'accès XPath de l'élément title est le suivant.
/html/head/title
De plus, en XPath, les attributs qui lient les éléments comme class sont représentés par "@".
En utilisant "@", le chemin d'accès du premier élément p dans le code ci-dessus est le suivant.
/html/body/div/div/p[@class='content1']
3. Deux façons d'exprimer XPath
XPath peut être exprimé de deux manières, chemin absolu et chemin relatif.
3.1. XPath : Chemin absolu
Le chemin absolu est similaire à celui utilisé précédemment, sélectionnant les éléments depuis le nœud racine le plus haut.
html/body/div/div/p[@class='content1']
3.2. XPath : Chemin relatif
Le chemin relatif utilise '//' pour sauter les nœuds intermédiaires et explorer séquentiellement à partir du nœud spécifié. En exprimant le chemin absolu précédent en chemin relatif, cela donne ceci.
//p[@class='content1']
4. Autres syntaxes d'expression
En plus, XPath utilise diverses syntaxes pour exprimer les chemins.
4.1. contains
: Récupère les cas où la valeur est incluse.
#'aa'를 포함하는 class명을 가진 div 요소를 선택
//div[contains(@class, "aa")]
4.2. last
: Récupère le dernier nœud correspondant au chemin.
//div[@class="aa")/span[last()]
4.3. and
: Récupère les nœuds qui satisfont les deux conditions.
#class명에 'aa'와 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") and contains(@class, "bb")]
4.4. or
: Récupère les nœuds qui satisfont au moins l'une des deux conditions.
#class명에 'aa' 또는 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") or contains(@class, "bb")]
4.5. not
: Récupère les nœuds qui ne satisfont pas la condition.
#class명에 'aa'를 포함하고 'bb'를 포함하지 않는 img 요소를 선택
//img[contains(@class, "aa") and not(contains(@class, "bb")
5. Exemple pratique
Nous avons examiné la syntaxe de base de XPath jusqu'à présent. Et si nous extrayons le XPath de la partie souhaitée d'un site web?
5.1. Ouvrir l'outil de développement
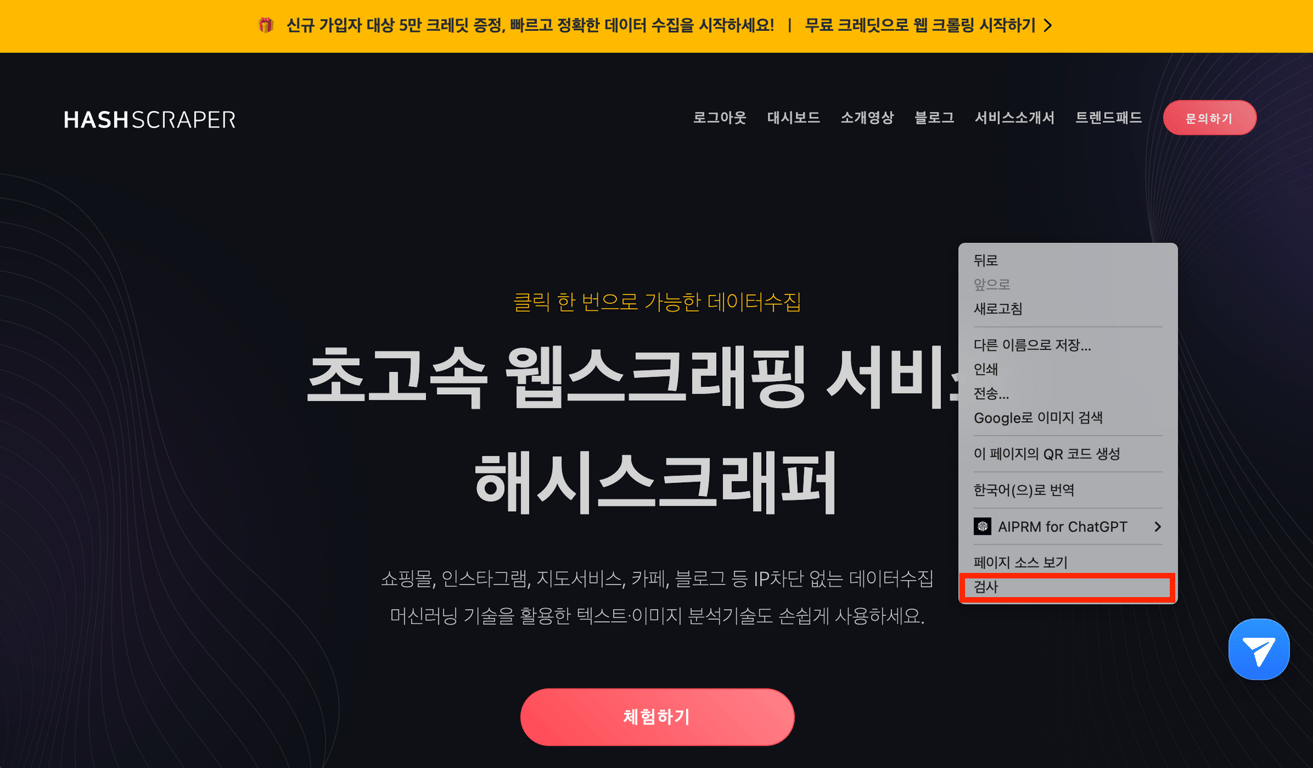
Tout d'abord, ouvrez le site web souhaité, cliquez avec le bouton gauche de la souris, puis appuyez sur 'Inspecter' pour ouvrir l'outil de développement de Chrome.
5.2. Vérifier la balise souhaitée
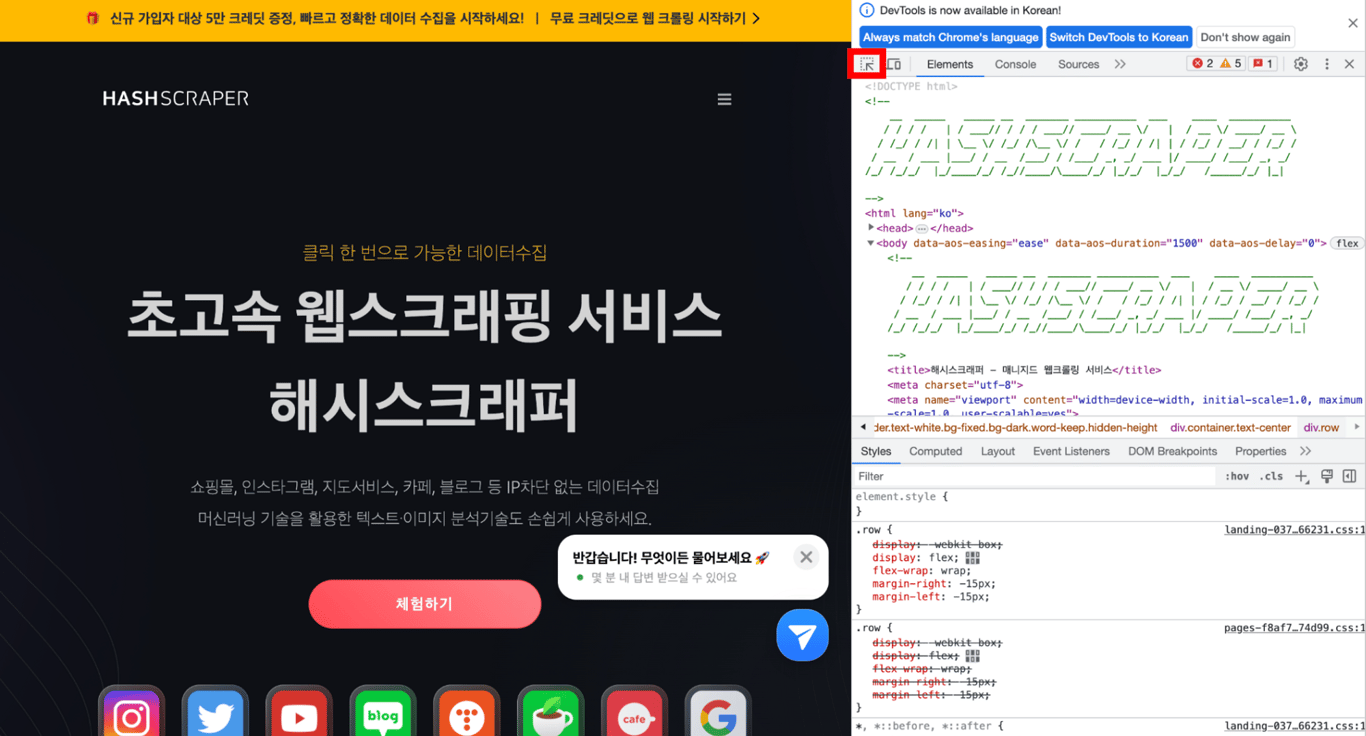
Dans l'outil de développement, cliquez sur l'icône de la souris en haut à gauche. Ensuite, placez le curseur sur la partie du site que vous souhaitez extraire, comme indiqué ci-dessous.
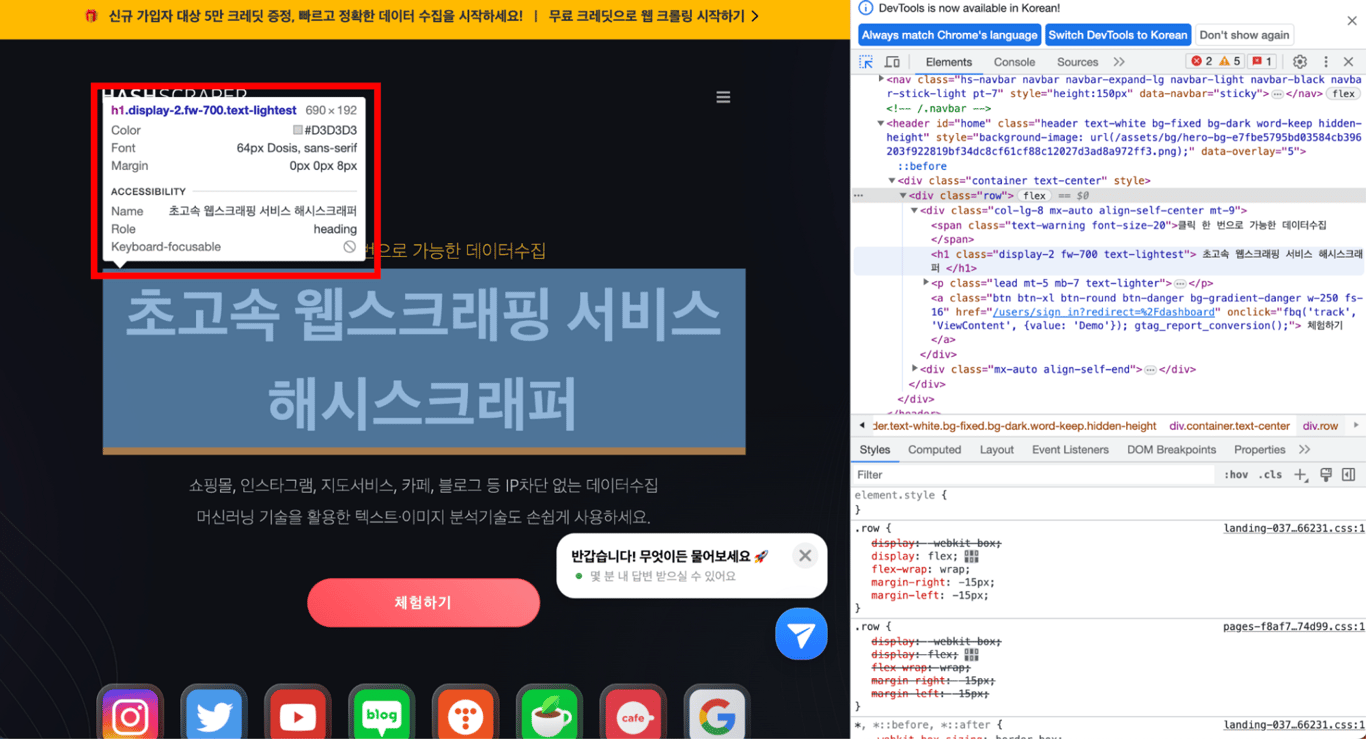
En cliquant à l'endroit désiré, l'outil de développement affiche la balise correspondante dans le code HTML réel.
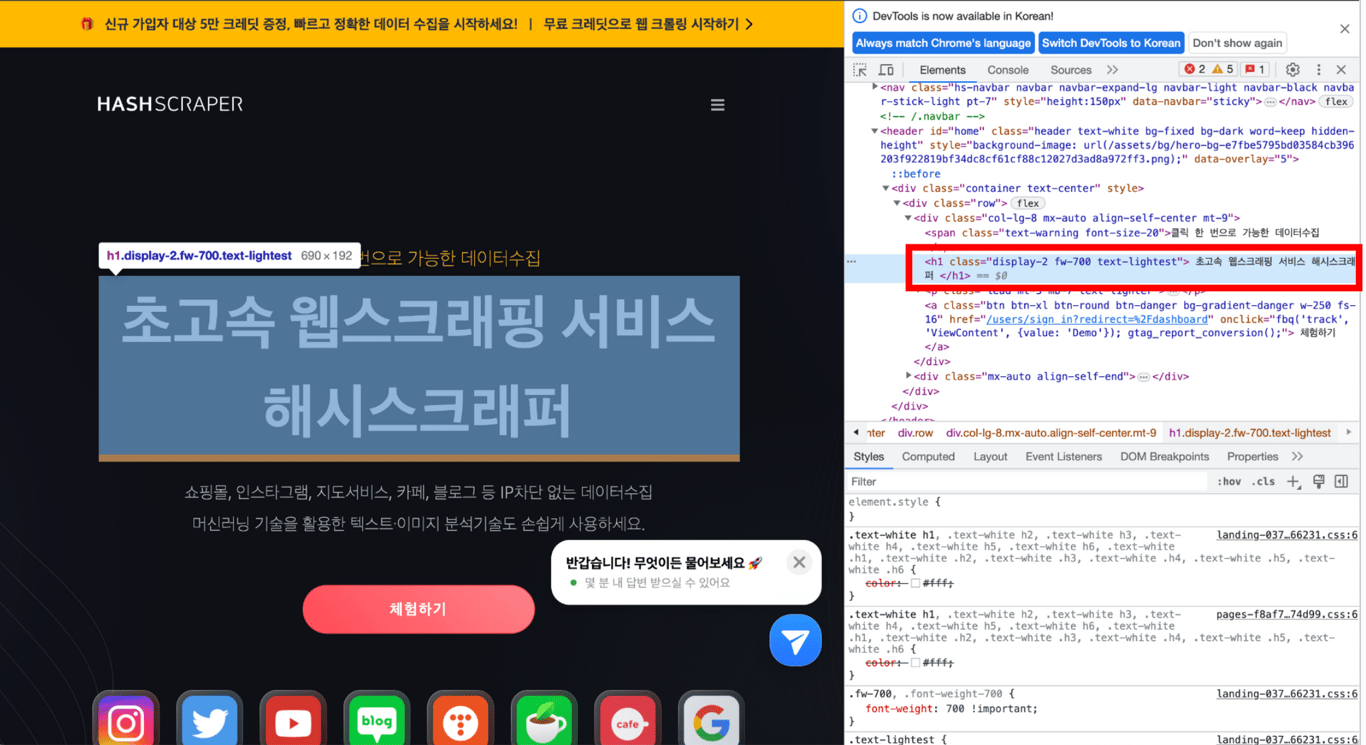
5.3. Copier le XPath
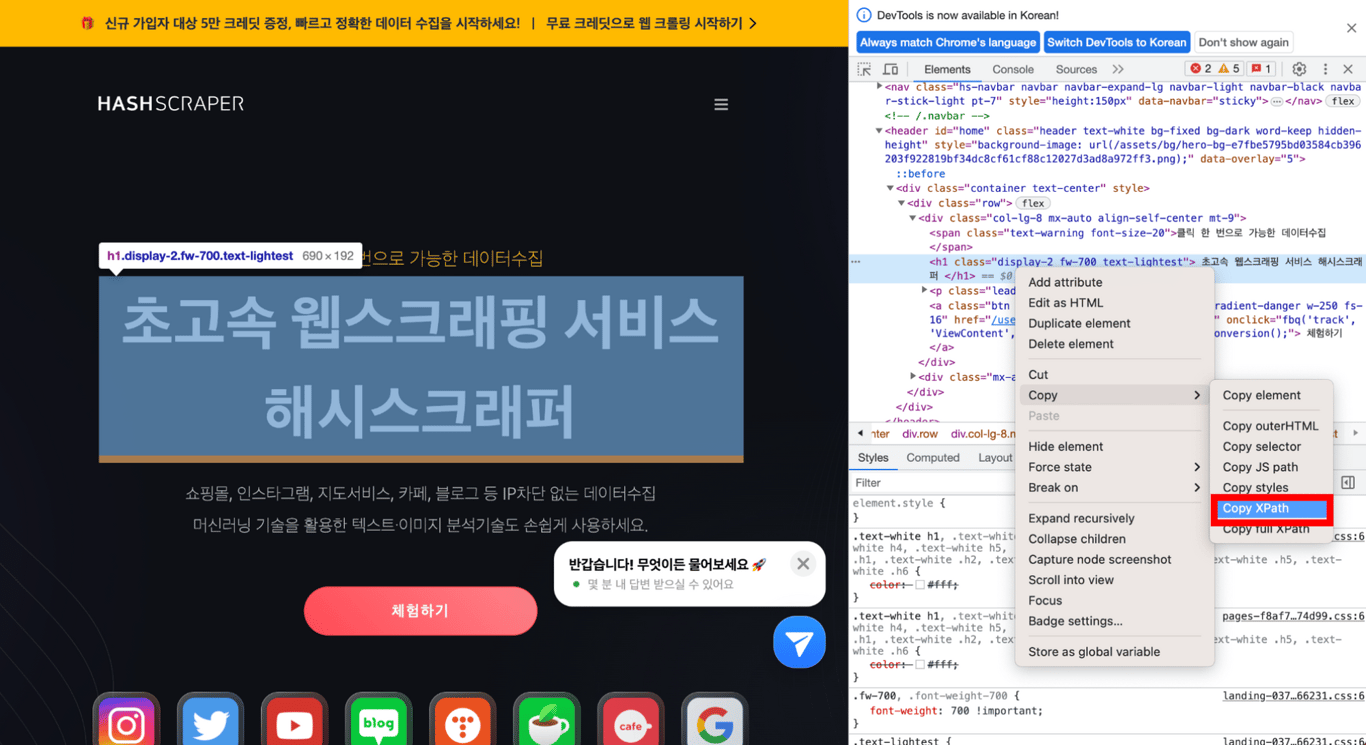
Copiez le XPath de la partie en sélectionnant Copier > Copier le XPath, puis collez-le pour obtenir le XPath de la partie souhaitée!
Vous pouvez vérifier que le XPath de la partie souhaitée a été correctement copié comme suit.
//*[@id="home"]/div/div/div[1]/h1
Comment ce XPath extrait peut-il être utilisé dans le crawling? Voici un extrait du code de crawling.
get_browser.goto "<https://www.hashscraper.com>"
x = get_browser.element(xpath: "//*[@id='home']/div/div/div[1]/h1").text
5.4. Vérification du fonctionnement
En utilisant XPath pour extraire l'élément souhaité et le stocker dans x, puis en imprimant x, vous verrez le texte souhaité s'afficher.
6. Conclusion : Commencez par apprendre XPath pour un crawling efficace
Nous avons examiné les bases du crawling, XPath. Pour collecter les données souhaitées via le crawling, il est essentiel de savoir comment ces données peuvent être représentées et XPath permet une expression simple de cela. Nous vous recommandons de commencer par étudier XPath avant de commencer le crawling!
Lisez également cet article :
Collecte de données, automatisez maintenant
Commencez en 5 minutes sans coder · Expérience de crawling sur plus de 5 000 sites web



