

0. Aperçu
Dans la première partie sur XPath, nous avons discuté des concepts essentiels et de la syntaxe de base de XPath, essentiels pour le web scraping. Dans cette deuxième partie, nous aborderons des aspects plus avancés de XPath.
1. Compréhension des caractères génériques
Avant d'entrer dans les détails avancés, il est essentiel de comprendre la signification de l'astérisque ('*') en XPath.
- L'astérisque correspond à n'importe quel élément en XPath et est utilisé pour sélectionner tous les éléments. Expliquons cela avec un exemple.
//div[contains(@class, "aa")]
Le XPath ci-dessus représente un élément div avec une classe contenant 'aa'. Que se passe-t-il si nous utilisons un astérisque à la place de div ?
//*[contains(@class, "aa")]
Dans ce XPath, '*' correspond à tous les éléments, donc ce XPath représente tous les éléments ayant une classe contenant 'aa'.
2. Compréhension de la structure hiérarchique de XPath
Explorons maintenant des aspects avancés de XPath.
Voici un exemple de code HTML simple.
<AAA>
<BBB>
<CCC/>
<DDD/>
</BBB>
<EEE>
<FFF>
<GGG/>
<GGG/>
<III>
<JJJ/>
</III>
</FFF>
</EEE>
<KKK>
<LLL/>
</KKK>
</AAA>
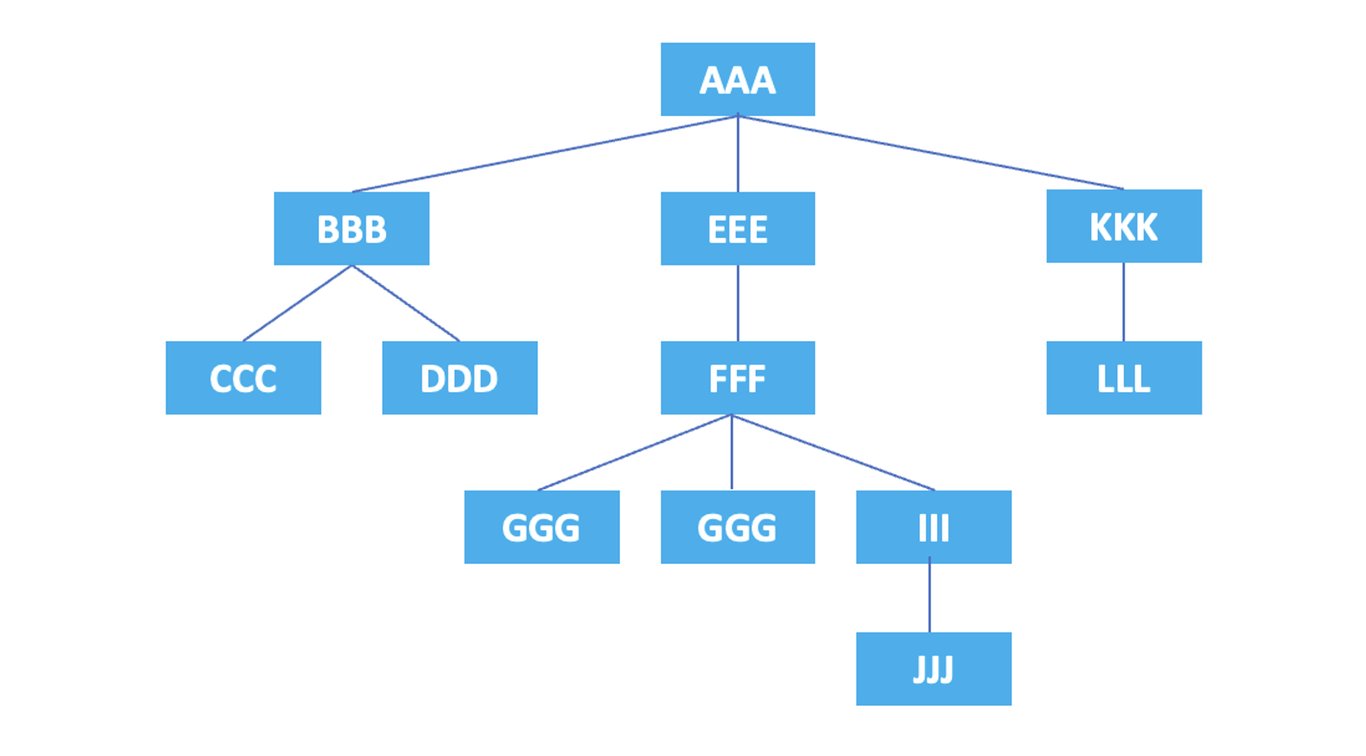
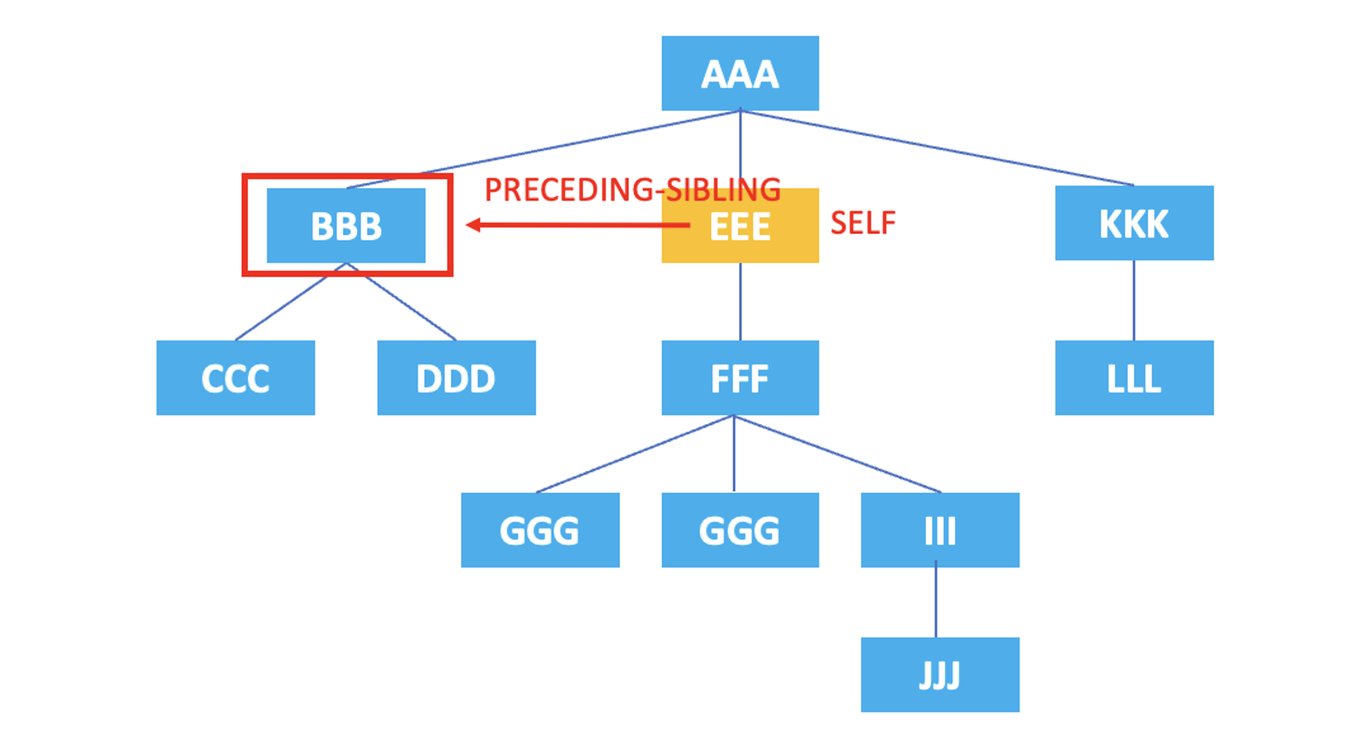
Chaque élément et attribut du code HTML forme une structure hiérarchique, représentée sous forme d'arborescence (Tree) en XPath. Les axes indiquent la direction ou la relation utilisée pour référencer et sélectionner les nœuds (node : point de données, unité) dans la structure en arborescence. Les axes incluent l'axe self, parent, child, etc. Nous expliquerons chacun d'eux un par un à l'aide d'exemples ci-dessous.
La structure hiérarchique des éléments ci-dessus est représentée graphiquement comme suit.
Explorons maintenant comment représenter les nœuds en utilisant les axes.
3. Méthodes de représentation des nœuds
3.1. self
: Représente le nœud actuel lui-même.
/AAA/self::*
Le XPath ci-dessus sélectionne l'élément <AAA>, qui est le nœud actuel.
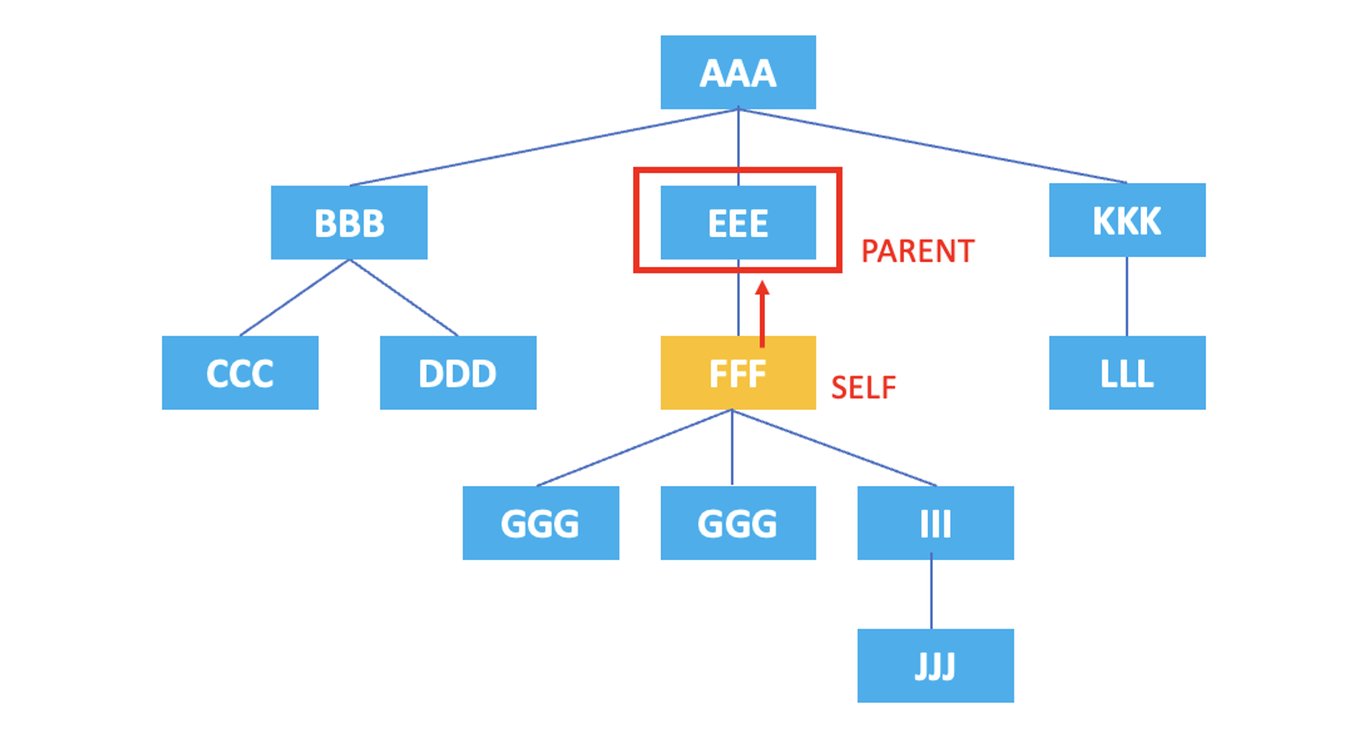
3.2. parent
: Représente le nœud parent du nœud actuel.
/AAA/EEE/FFF/parent::*
Le XPath ci-dessus sélectionne l'élément <EEE>, parent de l'élément actuel <FFF>.
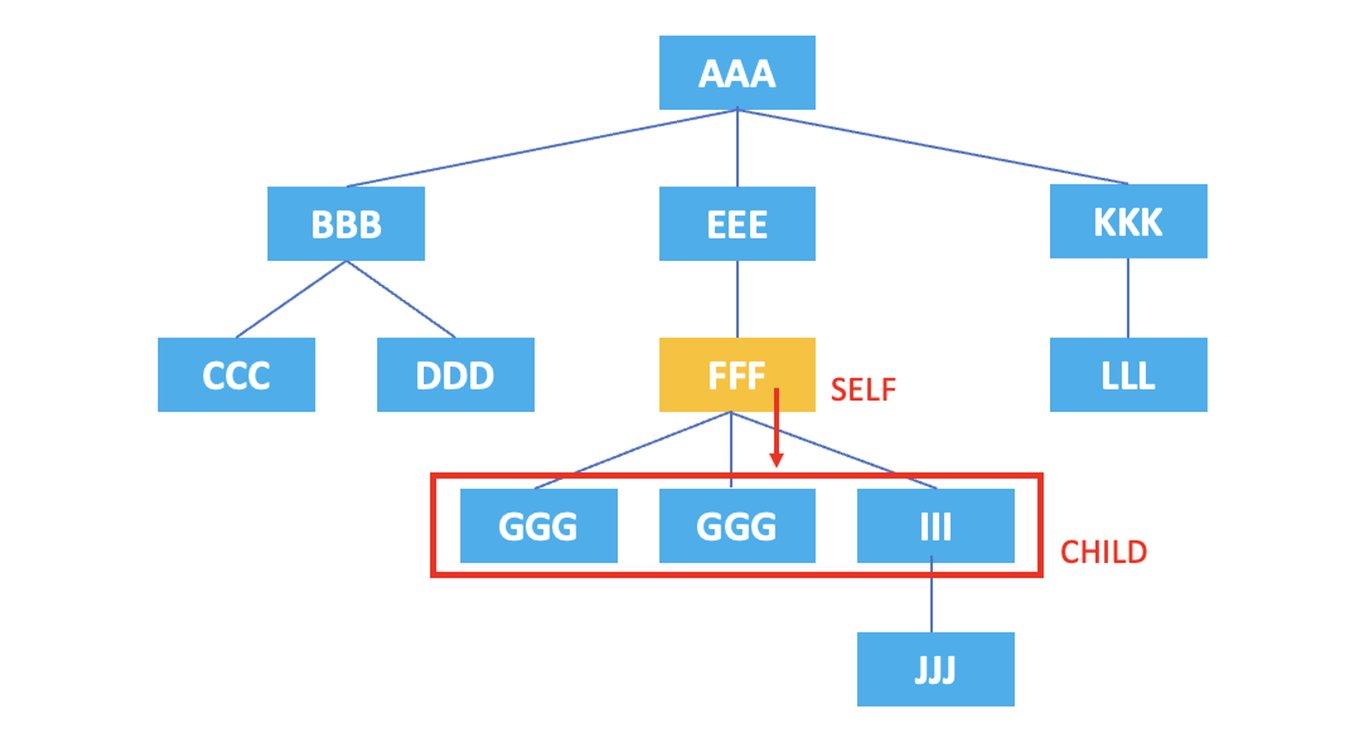
3.3. child : Représente les nœuds enfants du nœud actuel.
/AAA/EEE/FFF/child::*
Le XPath ci-dessus sélectionne tous les enfants de l'élément <FFF> : <GGG>, <GGG>, <III>.
Si vous souhaitez sélectionner uniquement l'élément <III>, vous pouvez modifier le XPath comme suit.
/AAA/EEE/FFF/child::III
De plus, si vous souhaitez sélectionner le premier des deux éléments <GGG>, vous pouvez le faire comme suit.
/AAA/EEE/FFF/child::GGG[1]
Il est important de noter que contrairement à la plupart des autres langages de programmation, les index en XPath commencent à 1!
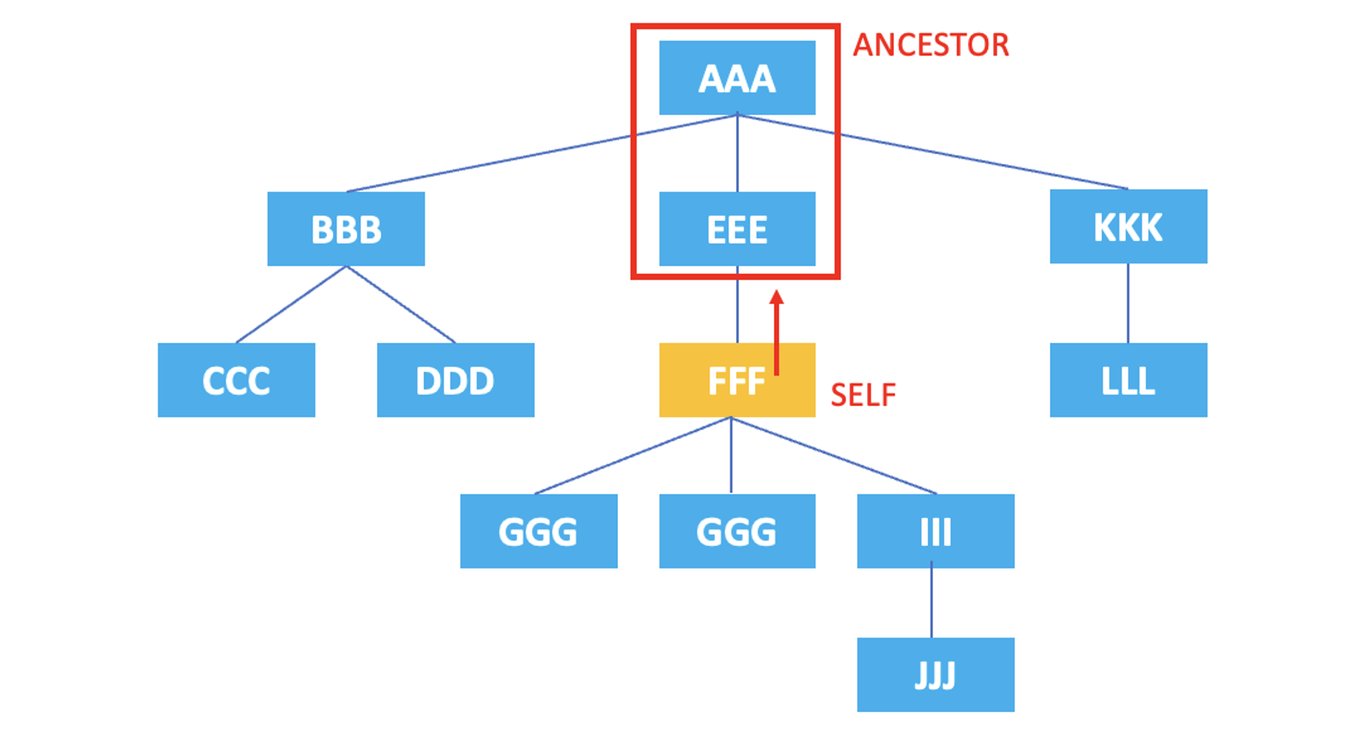
3.3. ancestor
: Représente tous les ancêtres du nœud actuel.
/AAA/EEE/FFF/ancestor::*
Le XPath ci-dessus sélectionne tous les ancêtres de l'élément <FFF> : <EEE>, <AAA>.
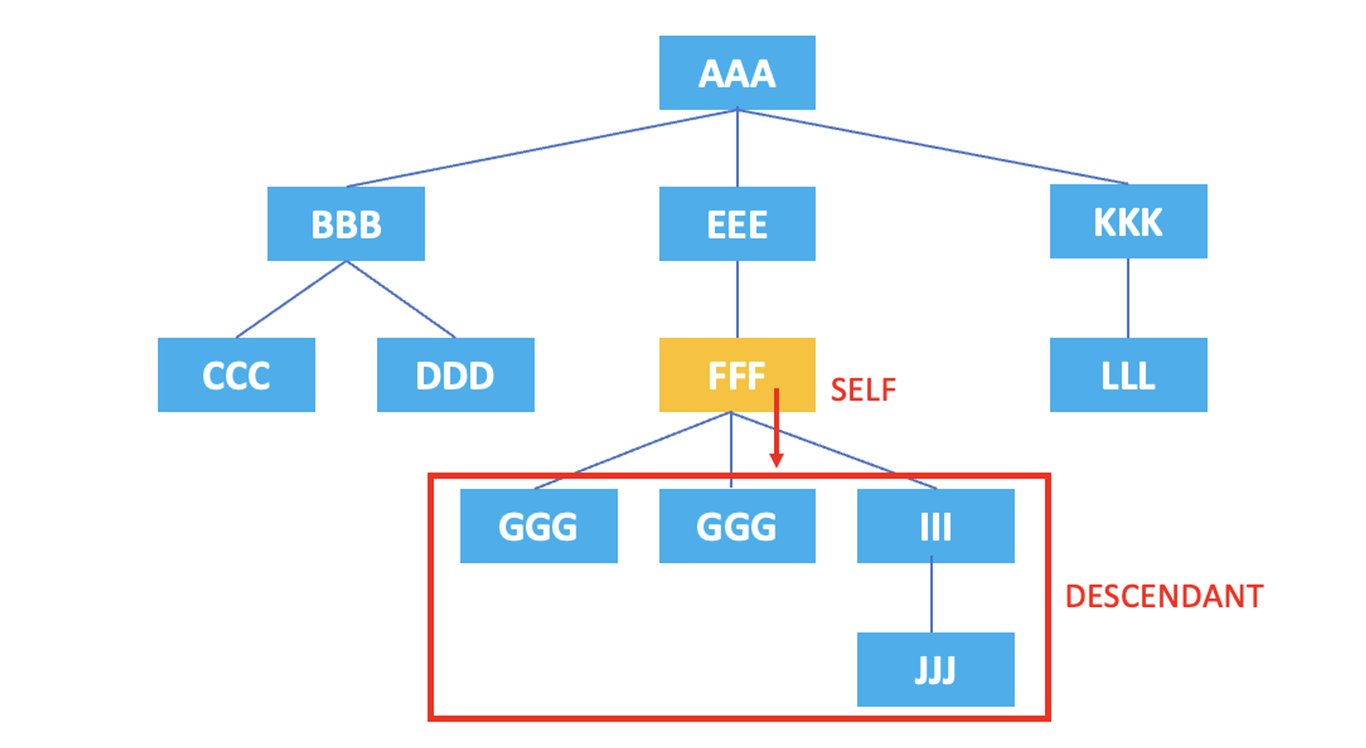
3.4. descendant
: Représente tous les descendants du nœud actuel.
/AAA/EEE/FFF/descendant::*
Le XPath ci-dessus sélectionne tous les descendants de l'élément <FFF> : <GGG>, <GGG>, <III>, <JJJ>.
3.5. ancestor-or-self
: Représente le nœud actuel et tous ses ancêtres.
/AAA/EEE/FFF/ancestor-or-self::*
Le XPath ci-dessus sélectionne à la fois le nœud actuel <FFF> et ses ancêtres <EEE>, <AAA>.
3.6. descendant-or-self
: Représente le nœud actuel et tous ses descendants.
/AAA/EEE/FFF/descendant-or-self::*
Le XPath ci-dessus sélectionne à la fois le nœud actuel <FFF> et ses descendants <GGG>, <GGG>, <III>, <JJJ>.
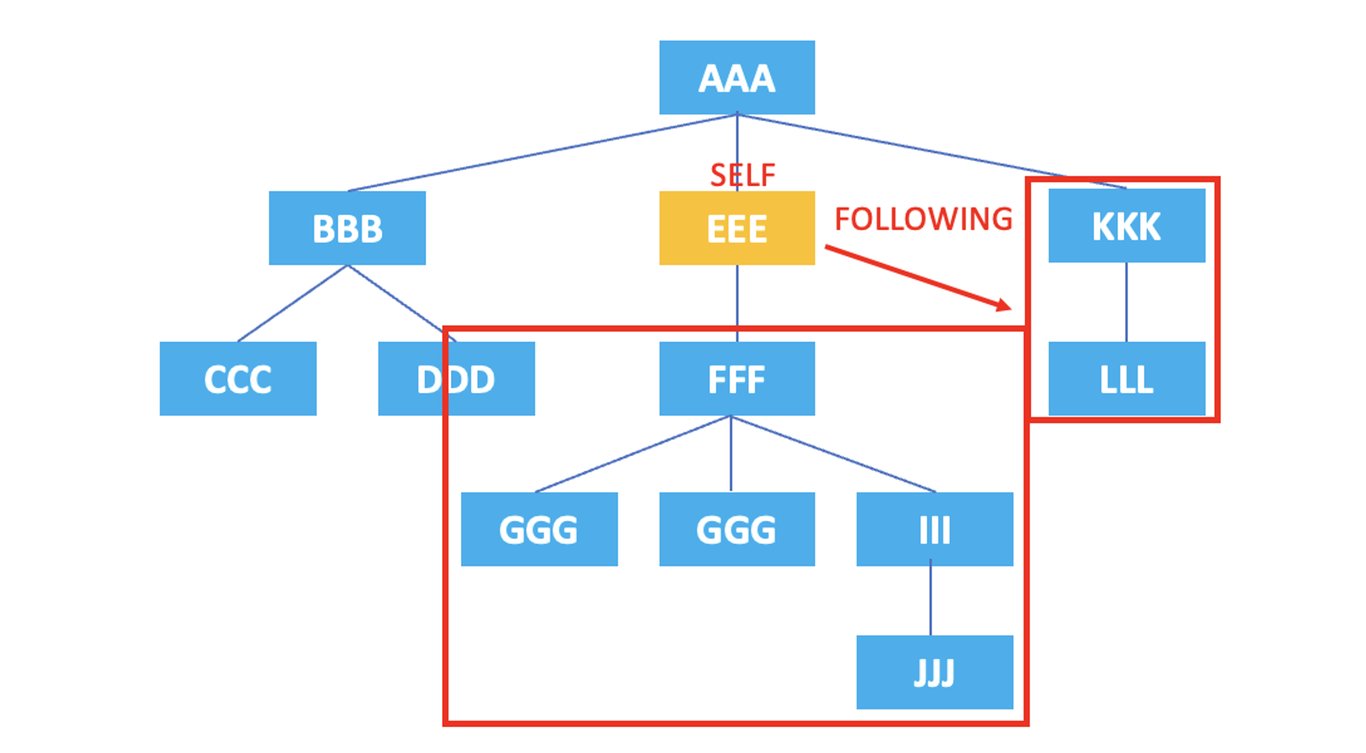
3.7. following
: Représente tous les nœuds qui apparaissent après la balise du nœud actuel.
/AAA/EEE/following::*
Le XPath ci-dessus sélectionne tous les nœuds suivant l'élément <EEE> après sa balise : <FFF>, <GGG>, <GGG>, <III>, <JJJ>, <KKK>, <LLL>.
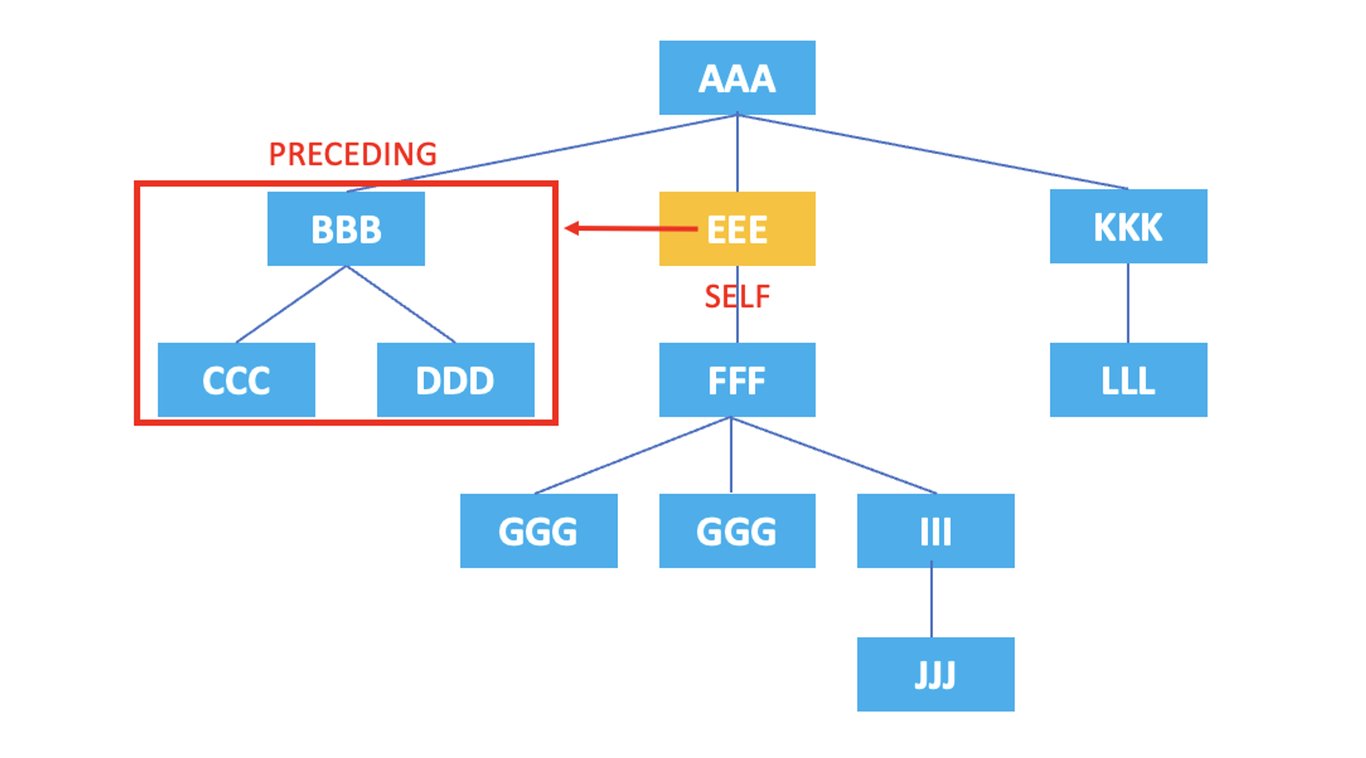
3.8. preceding
: Représente tous les nœuds qui apparaissent avant le début de la balise du nœud actuel.
/AAA/EEE/preceding::*
Le XPath ci-dessus sélectionne tous les nœuds précédant l'élément <EEE> avant sa balise : <BBB>, <CCC>, <DDD>.
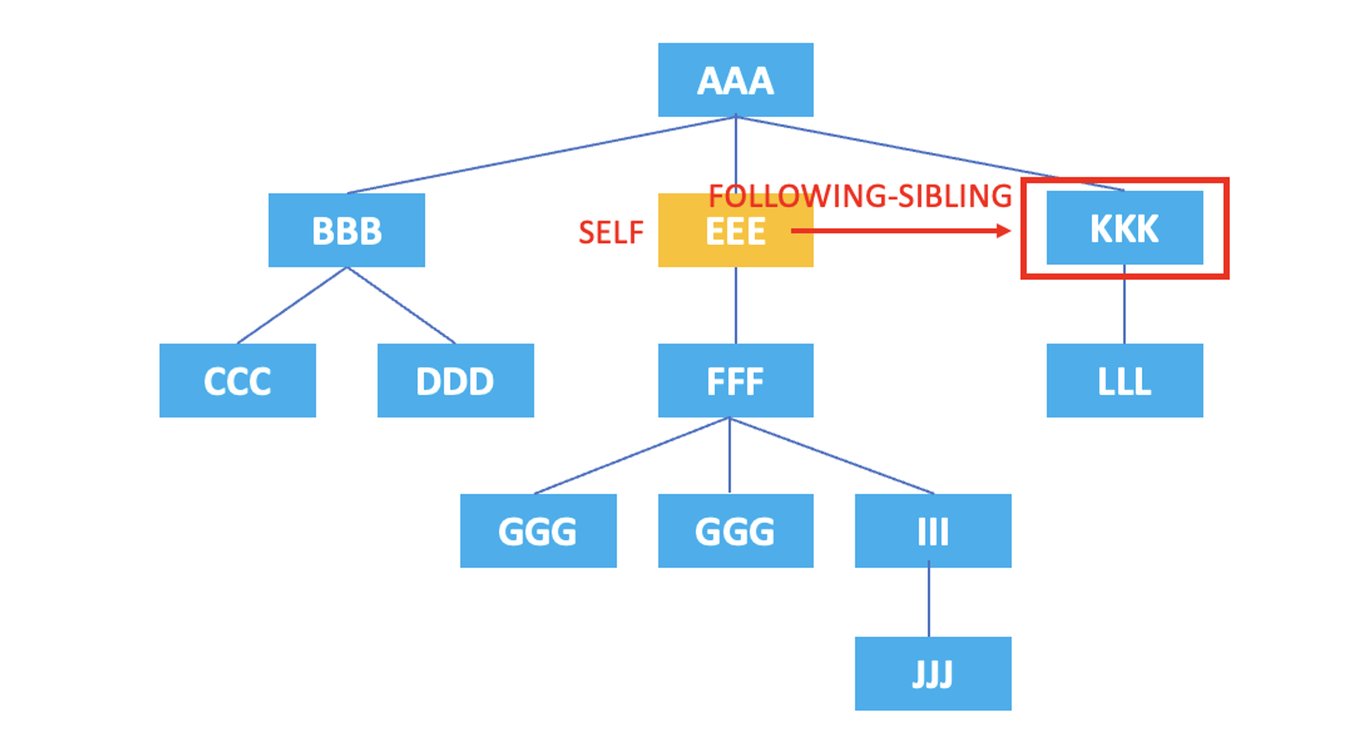
3.9. following-sibling
: Représente tous les nœuds frères qui suivent immédiatement le nœud actuel.
/AAA/EEE/following-sibling::*
Le XPath ci-dessus sélectionne le nœud frère suivant immédiatement l'élément <EEE> : <KKK>.
3.10. preceding-sibling
: Représente tous les nœuds frères qui précèdent immédiatement le nœud actuel.
/AAA/EEE/preceding-sibling::*
Le XPath ci-dessus sélectionne le nœud frère précédant immédiatement l'élément <EEE> : <BBB>.
Nous avons maintenant examiné les axes utilisés pour représenter les nœuds en XPath.
En outre, explorons deux autres fonctions utilisées en XPath.
4. Fonctions utilisées en XPath
4.1. count
: Retourne le nombre de nœuds répondant à une condition spécifique.
#class 속성 값이 ‘example인 div 요소의 개수를 반환
count(//div[@class="example"])
#p 요소의 총 개수를 반환
count(//p)
4.2. position
: Retourne la position du nœud actuel. (La position commence à 1 et augmente séquentiellement.)
<root>
<item>Item 1</item>
<item>Item 2</item>
<item>Item 3</item>
</root>
Par exemple, avec le code XML suivant, vous pouvez écrire le XPath comme ceci.
//item[position() = 2]
En utilisant la fonction position, vous pouvez sélectionner le deuxième élément item parmi trois éléments item.
5. Conclusion
Nous avons maintenant exploré les aspects avancés de XPath. Si vous avez maîtrisé à la fois les bases et les aspects avancés, vous avez acquis une connaissance de base suffisante pour trouver précisément les éléments souhaités et extraire des données à partir de documents XML en utilisant XPath.
XPath est un outil puissant pour explorer et manipuler des documents XML, largement utilisé dans des domaines tels que le scraping de données, le scraping web, l'extraction de données à partir de services web basés sur XML, etc. Nous vous souhaitons du succès dans l'extraction et l'utilisation efficaces des données en utilisant XPath!
Lisez également:
Collecte de données, automatisez maintenant
Commencez en 5 minutes sans coder · Expérience de scraping de plus de 5 000 sites web



