

0. ¿Qué es XPath?
XPath es la abreviatura de 'Lenguaje de Ruta XML', un lenguaje que especifica la ruta para acceder a elementos o atributos específicos de un documento XML.
XPath se utiliza principalmente en tareas de web scraping, y primero veremos la sintaxis básica de XPath.
1. Sintaxis básica de XPath
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>hashscraper</title>
</head>
<body>
<div id="container">
<div class="title">
<p class="content1">let's start crawling!</p>
<p class="content2">crawling is fun!</p>
</div>
</div>
</body>
</html>
2. Código HTML
Aquí hay un código HTML simple.
El código HTML está compuesto por elementos y atributos, y cada elemento y atributo forman una jerarquía.
XPath representa un documento XML en una estructura de árbol y proporciona un camino para extraer todos los nodos, atributos y datos desde el nodo raíz hasta los nodos más bajos.
(*Aquí, el nodo se refiere a cada parte del documento XML, como elementos, atributos, contenido de texto, etc.)
Veamos el camino para acceder al elemento title en el código anterior.
En términos de la estructura de árbol, el elemento title está compuesto por los elementos html → head → title en ese orden.
Por lo tanto, el XPath para el elemento title sería el siguiente.
/html/head/title
Además, en XPath, los atributos que vinculan elementos como class se representan con "@".
Para representar el XPath del primer elemento p en el código anterior usando "@", sería el siguiente.
/html/body/div/div/p[@class='content1']
3. Dos formas de representar XPath
XPath se puede representar de dos maneras, ruta absoluta y ruta relativa.
3.1. XPath: Ruta Absoluta
La ruta absoluta es similar al enfoque utilizado anteriormente, seleccionando elementos desde el nodo raíz superior.
html/body/div/div/p[@class='content1']
3.2. XPath: Ruta Relativa
La ruta relativa utiliza '//' para omitir la ruta de nodos intermedios y realizar la búsqueda secuencial desde el nodo especificado. Si representamos la ruta absoluta anterior como una ruta relativa, sería la siguiente.
//p[@class='content1']
4. Otras formas de expresión en XPath
Además, XPath utiliza varias sintaxis para representar caminos.
4.1. contains
: Obtiene los casos que contienen el valor especificado.
#'aa'를 포함하는 class명을 가진 div 요소를 선택
//div[contains(@class, "aa")]
4.2. last
: Obtiene el último nodo que coincide con la ruta.
//div[@class="aa")/span[last()]
4.3. and
: Obtiene los nodos que cumplen ambas condiciones.
#class명에 'aa'와 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") and contains(@class, "bb")]
4.4. or
: Obtiene los nodos que cumplen al menos una de las dos condiciones.
#class명에 'aa' 또는 'bb'를 포함하는 img 요소를 선택
//img[contains(@class, "aa") or contains(@class, "bb")]
4.5. not
: Obtiene los nodos que no cumplen la condición especificada.
#class명에 'aa'를 포함하고 'bb'를 포함하지 않는 img 요소를 선택
//img[contains(@class, "aa") and not(contains(@class, "bb")
5. Ejemplo práctico
Hemos revisado la sintaxis básica de XPath hasta ahora. ¿Por qué no intentamos obtener el XPath de la parte que queremos de un sitio web?
5.1. Abrir Herramientas de Desarrollo
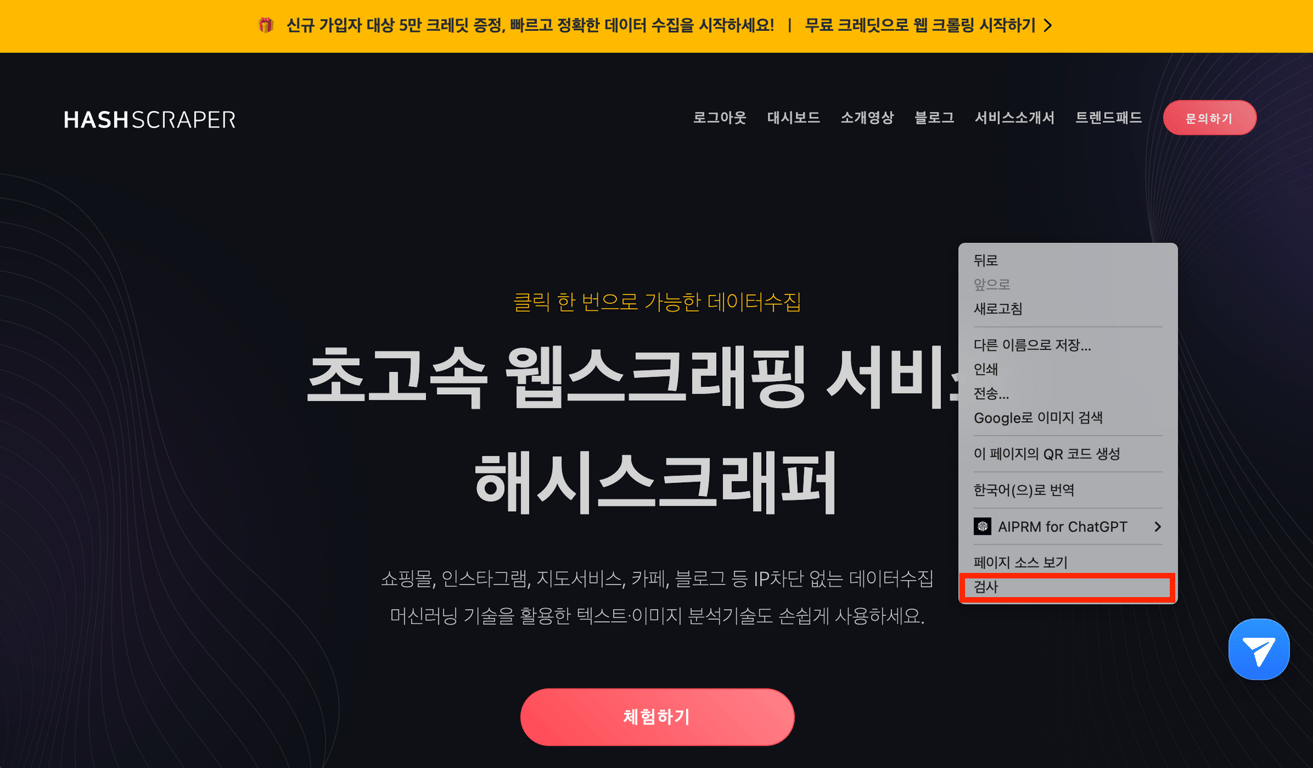
Primero, abre el sitio web deseado y haz clic izquierdo y luego en 'Inspeccionar' para abrir las herramientas de desarrollo de Chrome.
5.2. Confirmar la Etiqueta Deseada
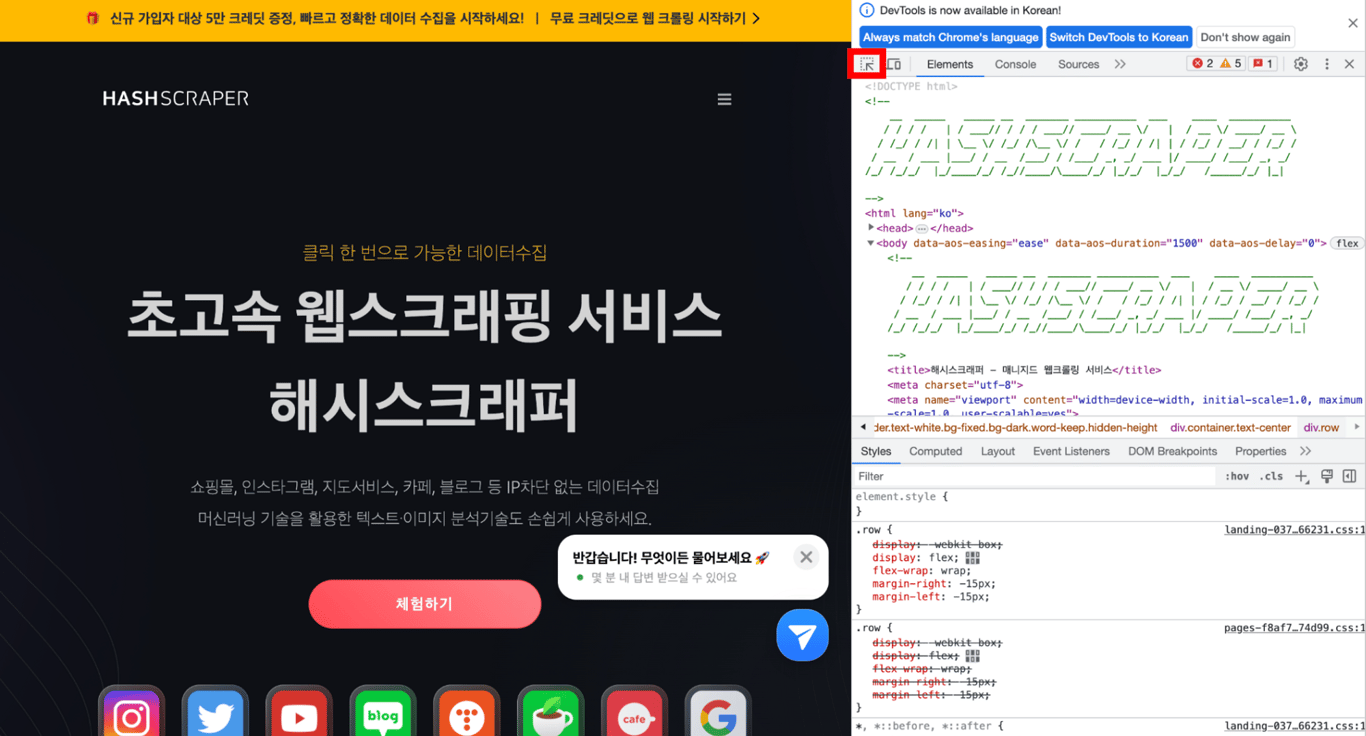
En las herramientas de desarrollo, haz clic en el ícono del mouse en la esquina superior izquierda. Luego, al pasar el mouse sobre la parte del sitio web que deseas obtener, verás lo siguiente.
Haz clic en la ubicación señalada por el mouse y las herramientas de desarrollo mostrarán la etiqueta de la parte deseada en el código HTML real.
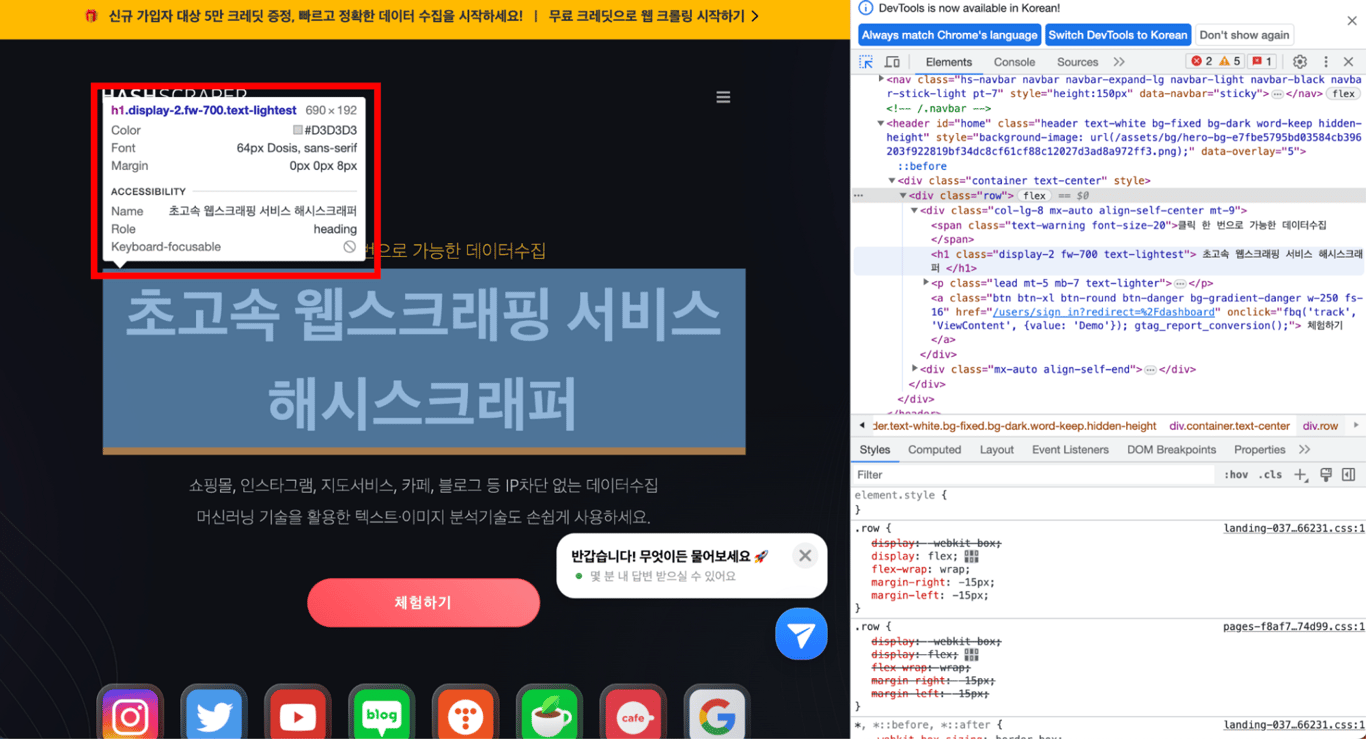
5.3. Copiar XPath
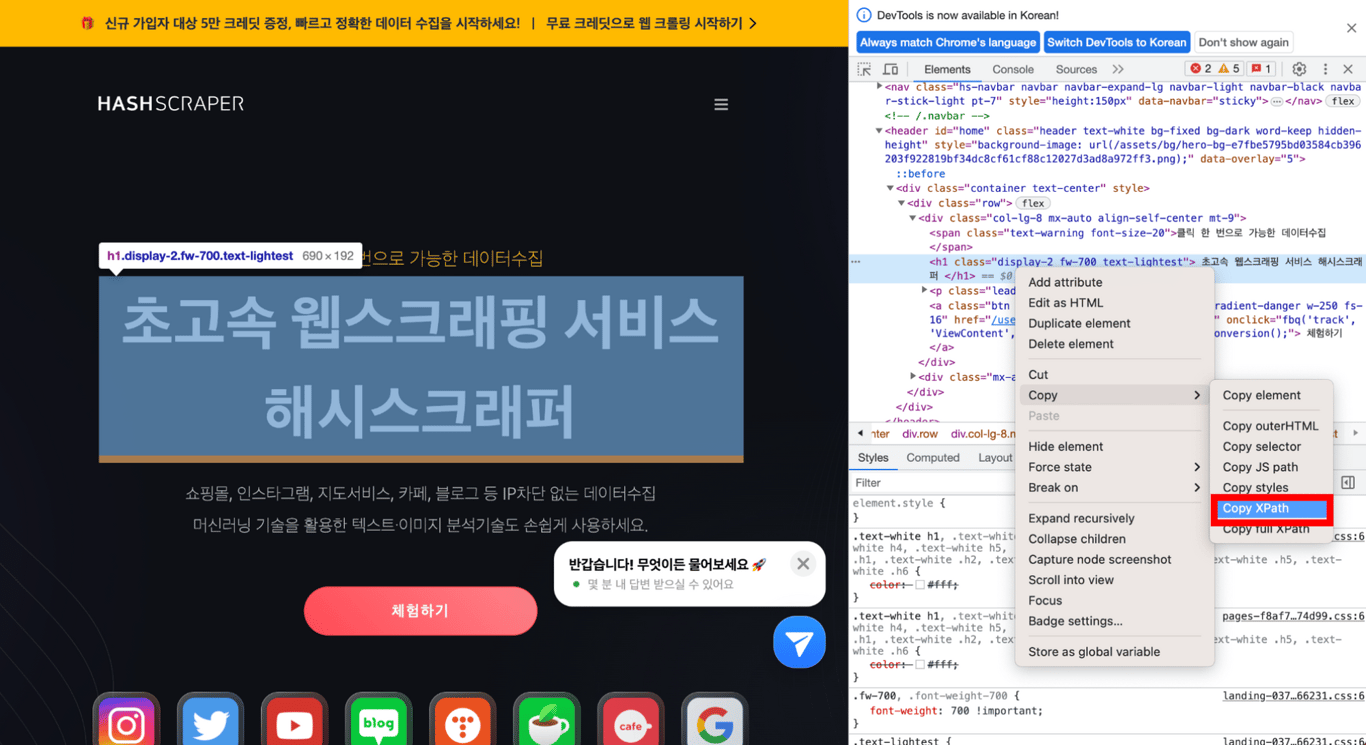
Copia el XPath de la parte seleccionada y pégalo. Así podrás obtener el XPath de la parte deseada.
Puedes confirmar que el XPath de la parte deseada se ha movido correctamente de la siguiente manera.
//*[@id="home"]/div/div/div[1]/h1
Entonces, ¿cómo se puede utilizar este XPath en el web scraping? Aquí hay una parte del código de web scraping.
get_browser.goto "<https://www.hashscraper.com>"
x = get_browser.element(xpath: "//*[@id='home']/div/div/div[1]/h1").text
5.4. Confirmar el Funcionamiento
Almacenamos el elemento deseado en x utilizando XPath y, al imprimir x, podemos ver que se muestra el texto deseado.
6. Conclusión: Comencemos aprendiendo XPath para realizar un web scraping adecuado
Hemos aprendido los conceptos básicos del web scraping y XPath hasta ahora. Para recopilar los datos deseados a través del web scraping, es importante comprender cómo se pueden representar los datos y esto se puede hacer de manera sencilla a través de XPath. ¡Recomendamos comenzar por estudiar XPath antes de iniciar el web scraping!
¡Lee también este artículo!
Recopilación de datos, ahora automatizada
Comienza en 5 minutos sin necesidad de programar · Experiencia en web scraping de más de 5,000 sitios web



