

0. Resumen
En XPath 1, cubrimos los conceptos básicos y la sintaxis fundamental de XPath, que son esenciales para el web scraping. En esta segunda parte, discutiremos contenido más avanzado de XPath.
1. Comprensión de los comodines
Antes de adentrarnos en el contenido avanzado, es crucial comprender el significado del '*(comodín)' en XPath.
- El comodín (*) en XPath coincide con cualquier elemento y se utiliza para seleccionar todos los elementos. Explicaré esto con un ejemplo.
//div[contains(@class, "aa")]
El XPath anterior representa un elemento div con un nombre de clase que contiene 'aa'. ¿Qué sucede si usamos un comodín en lugar de div?
//*[contains(@class, "aa")]
En este XPath, '*' coincide con todos los elementos, por lo que este XPath representaría todos los elementos que tienen un nombre de clase que contiene 'aa'.
2. Comprensión de la estructura jerárquica de XPath
Ahora, adentrémonos en el contenido avanzado de XPath.
Aquí hay un código HTML simple.
<AAA>
<BBB>
<CCC/>
<DDD/>
</BBB>
<EEE>
<FFF>
<GGG/>
<GGG/>
<III>
<JJJ/>
</III>
</FFF>
</EEE>
<KKK>
<LLL/>
</KKK>
</AAA>
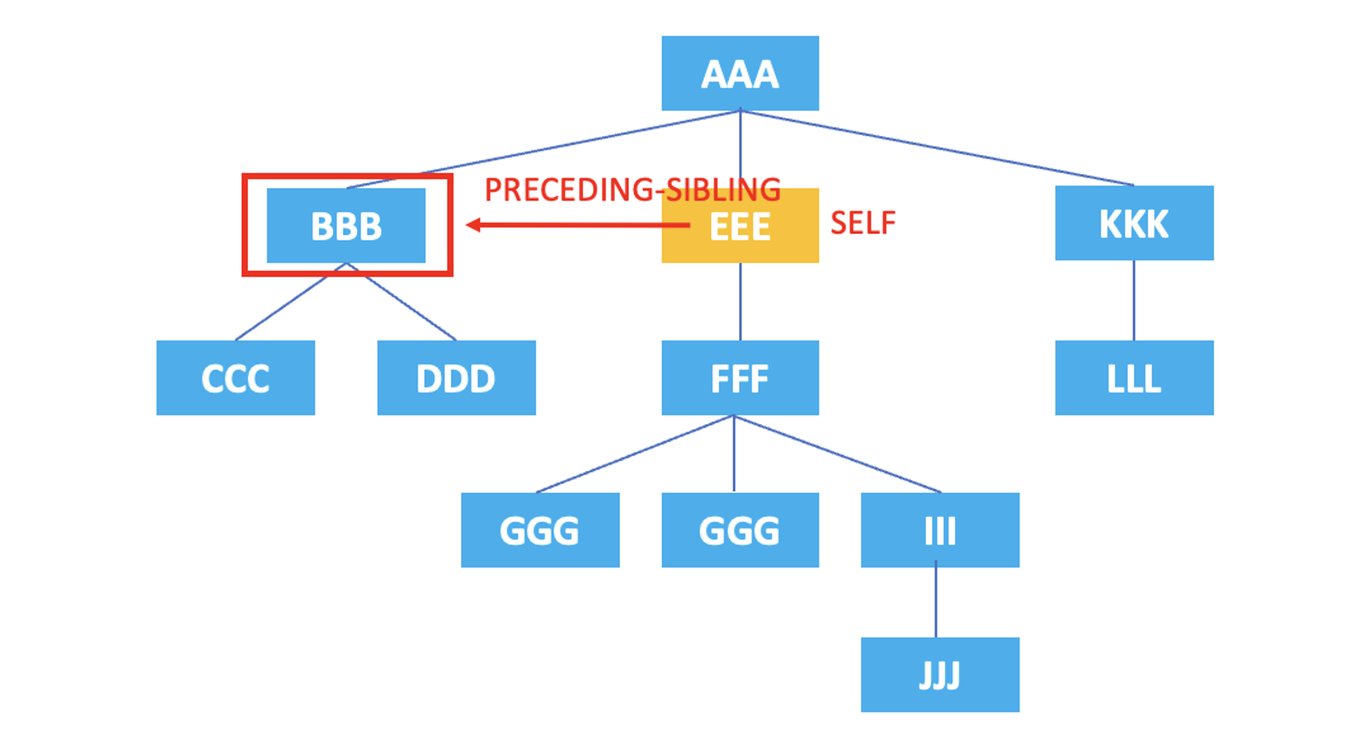
Cada elemento y atributo en el código HTML forman una jerarquía, y en XPath, esta jerarquía se representa como una estructura de árbol. Los ejes en XPath indican la dirección o relación utilizada para referenciar y seleccionar nodos en la estructura de árbol. Hay ejes como eje de sí mismo, eje padre, eje hijo, etc. Explicaré cada uno de ellos con ejemplos a continuación.
Si representamos la estructura jerárquica de los elementos anteriores en un diagrama, se vería así:
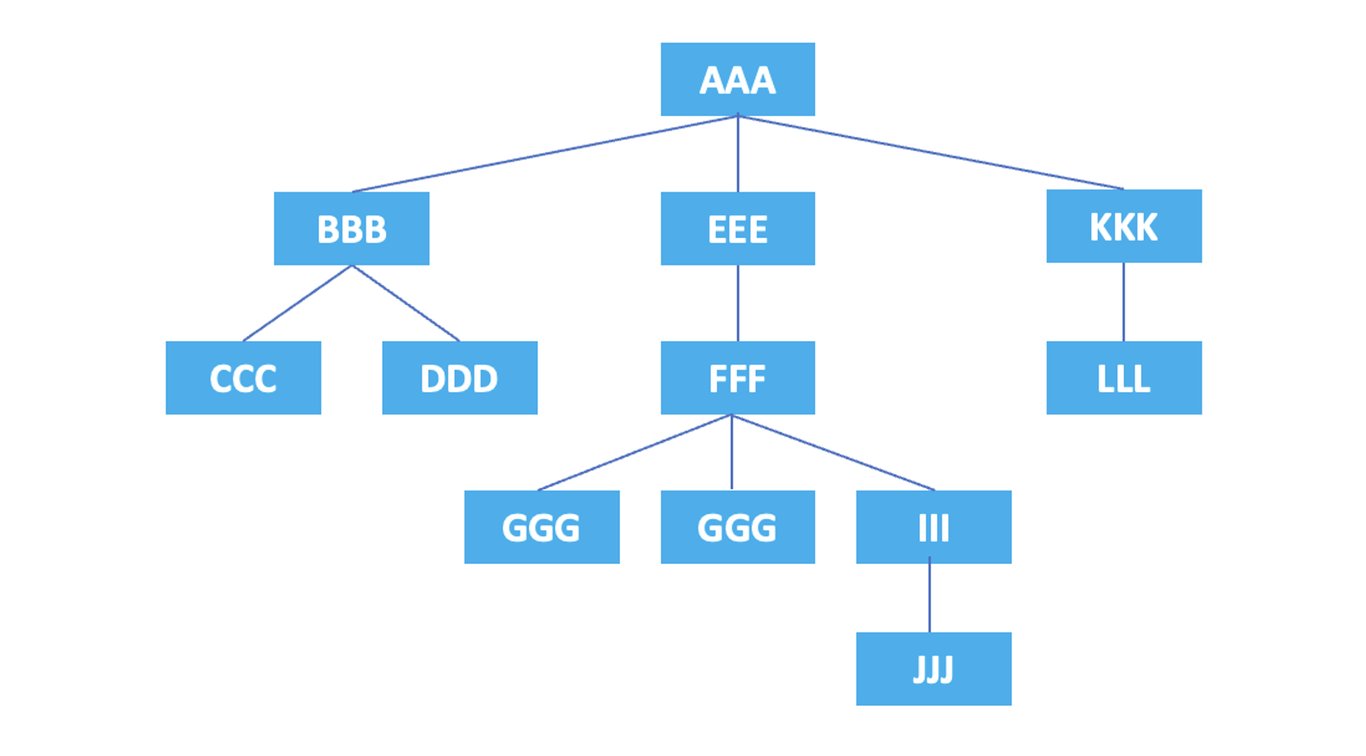
Ahora, veamos cómo se pueden representar los nodos utilizando ejes.
3. Formas de representar nodos
3.1. self
: Representa el nodo actual.
/AAA/self::*
El XPath anterior seleccionaría el elemento <AAA>, que es el nodo actual.
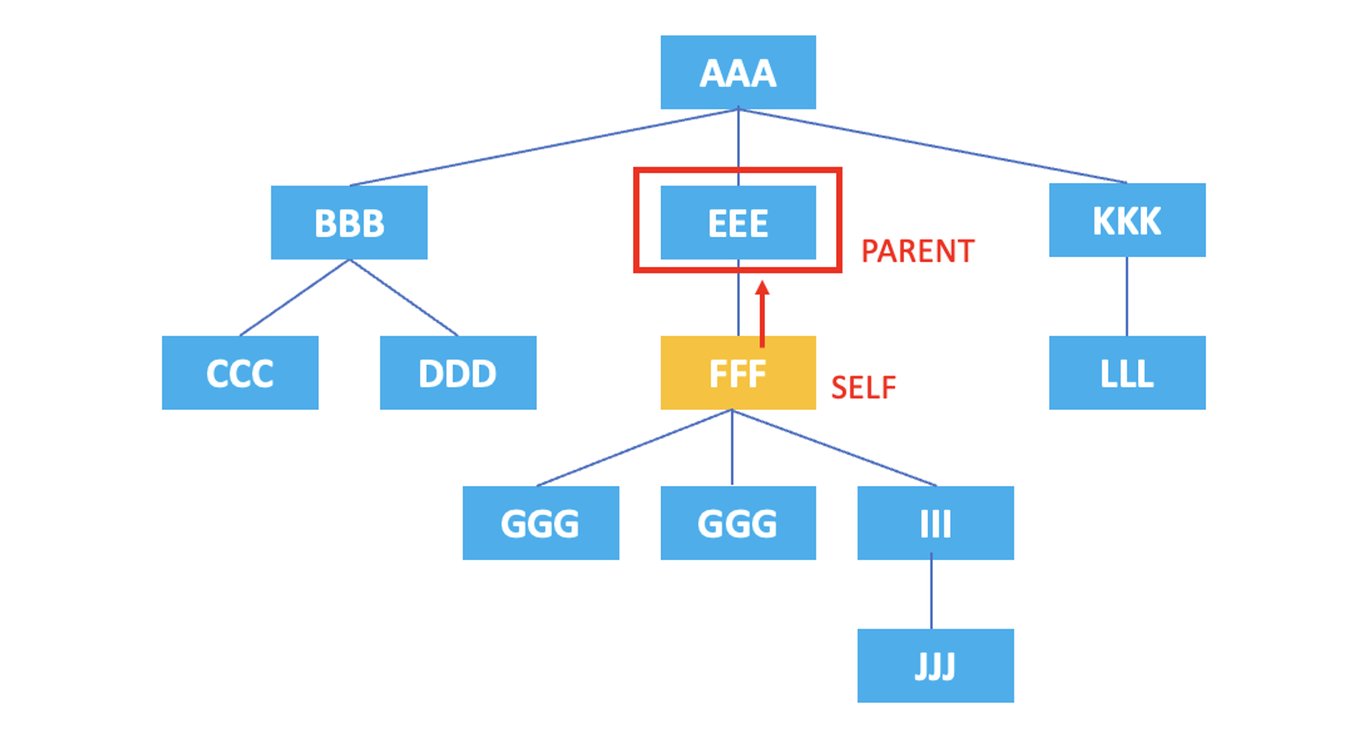
3.2. parent
: Representa el nodo padre del nodo actual.
/AAA/EEE/FFF/parent::*
El XPath anterior seleccionaría el elemento <EEE>, que es el nodo padre del elemento <FFF> actual.
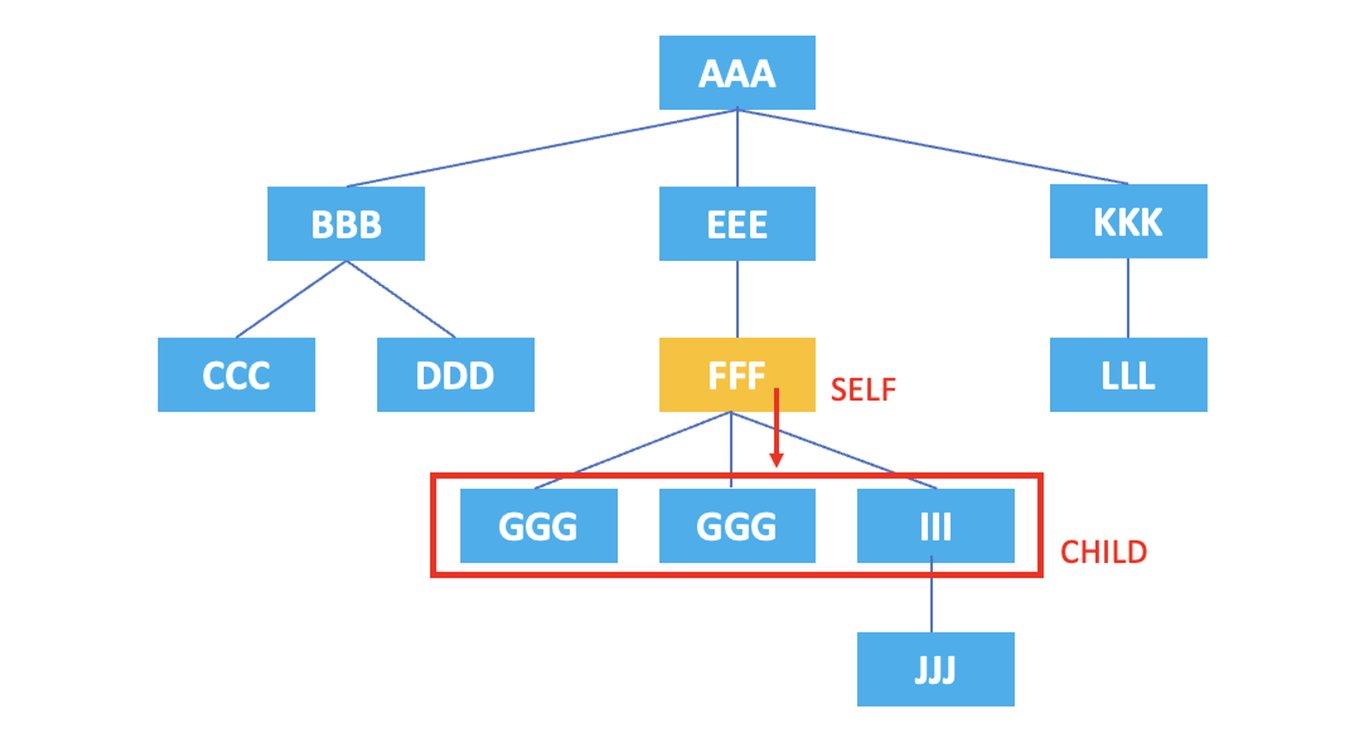
3.3. child : Representa los nodos hijos del nodo actual.
/AAA/EEE/FFF/child::*
El XPath anterior seleccionaría todos los nodos hijos del elemento <FFF> actual, que son <GGG>, <GGG>, <III>.
Si solo queremos seleccionar el elemento <III>, podemos modificar el XPath de la siguiente manera.
/AAA/EEE/FFF/child::III
Además, si queremos seleccionar el primer elemento <GGG> de los dos, podemos modificarlo de la siguiente manera.
/AAA/EEE/FFF/child::GGG[1]
¡Recuerda que en XPath, los índices comienzan desde 1, a diferencia de la mayoría de los otros lenguajes de programación!
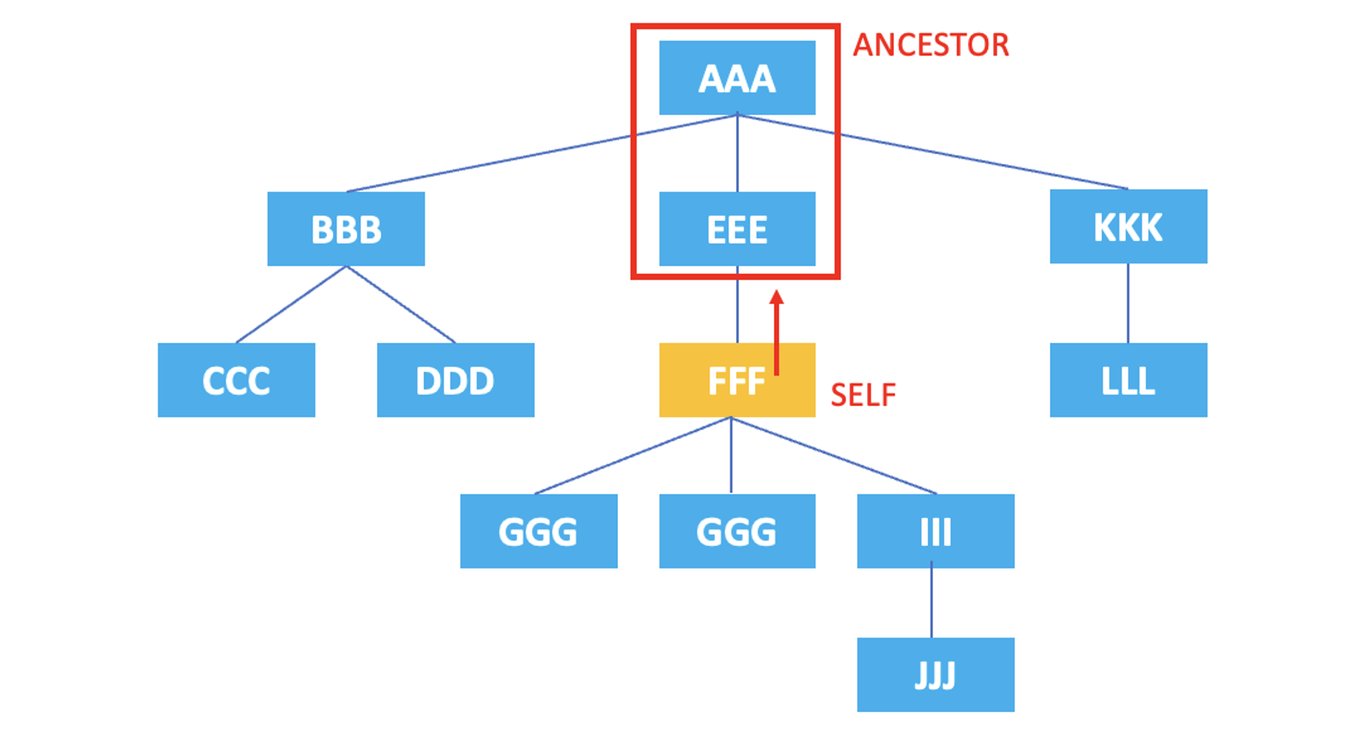
3.3. ancestor
: Representa todos los nodos ancestros del nodo actual.
/AAA/EEE/FFF/ancestor::*
El XPath anterior seleccionaría todos los nodos ancestros del elemento <FFF> actual, que son <EEE> y <AAA>.
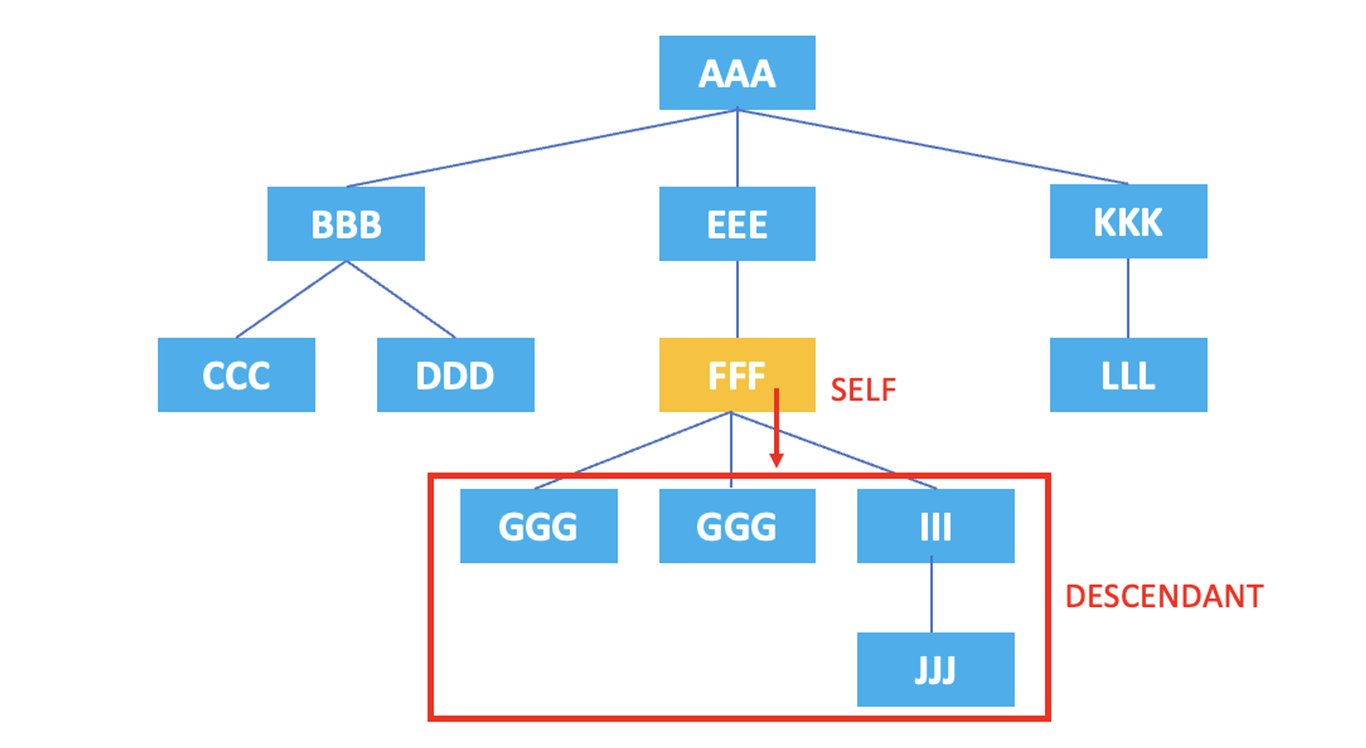
3.4. descendant
: Representa todos los nodos descendientes del nodo actual.
/AAA/EEE/FFF/descendant::*
El XPath anterior seleccionaría todos los nodos descendientes del elemento <FFF> actual, que son <GGG>, <GGG>, <III>, <JJJ>.
3.5. ancestor-or-self
: Representa el nodo actual y todos los nodos ancestros del nodo actual.
/AAA/EEE/FFF/ancestor-or-self::*
El XPath anterior seleccionaría tanto el nodo actual <FFF> como los nodos ancestros <EEE> y <AAA>.
3.6. descendant-or-self
: Representa el nodo actual y todos los nodos descendientes del nodo actual.
/AAA/EEE/FFF/descendant-or-self::*
El XPath anterior seleccionaría tanto el nodo actual <FFF> como los nodos descendientes <GGG>, <GGG>, <III>, <JJJ>.
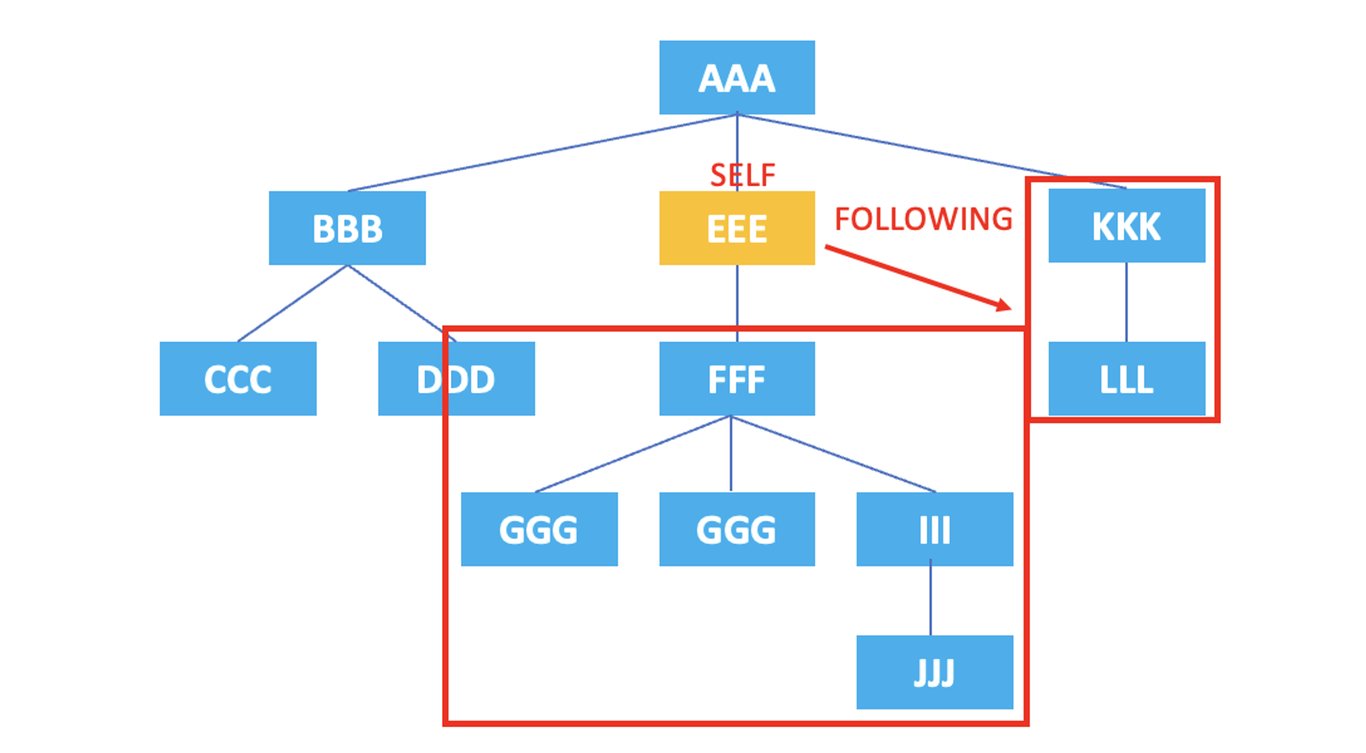
3.7. following
: Representa todos los nodos que aparecen después de la etiqueta del nodo actual.
/AAA/EEE/following::*
El XPath anterior seleccionaría todos los nodos que aparecen después del nodo <EEE> actual, que son <FFF>, <GGG>, <GGG>, <III>, <JJJ>, <KKK>, <LLL>.
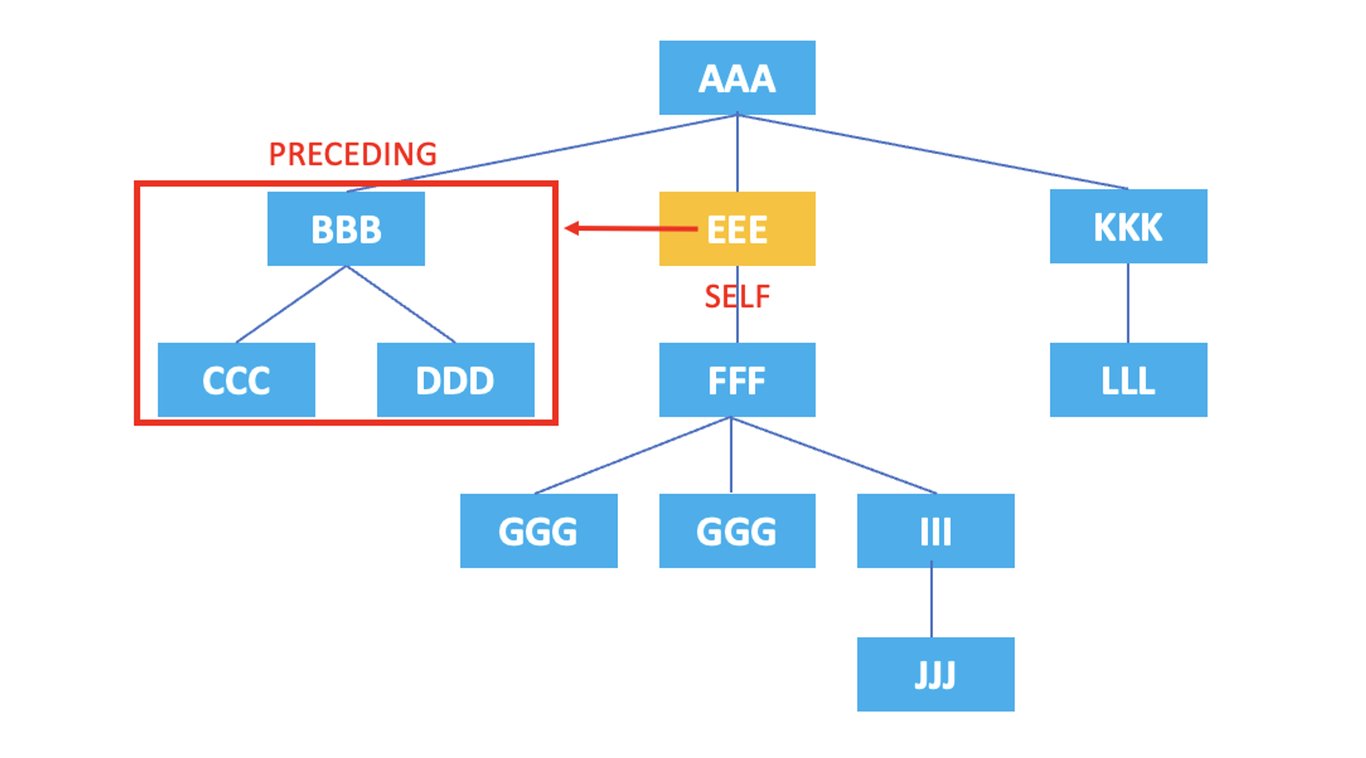
3.8. preceding
: Representa todos los nodos que aparecen antes de que comience la etiqueta del nodo actual.
/AAA/EEE/preceding::*
El XPath anterior seleccionaría todos los nodos que aparecen antes del nodo <EEE> actual, que son <BBB>, <CCC>, <DDD>.
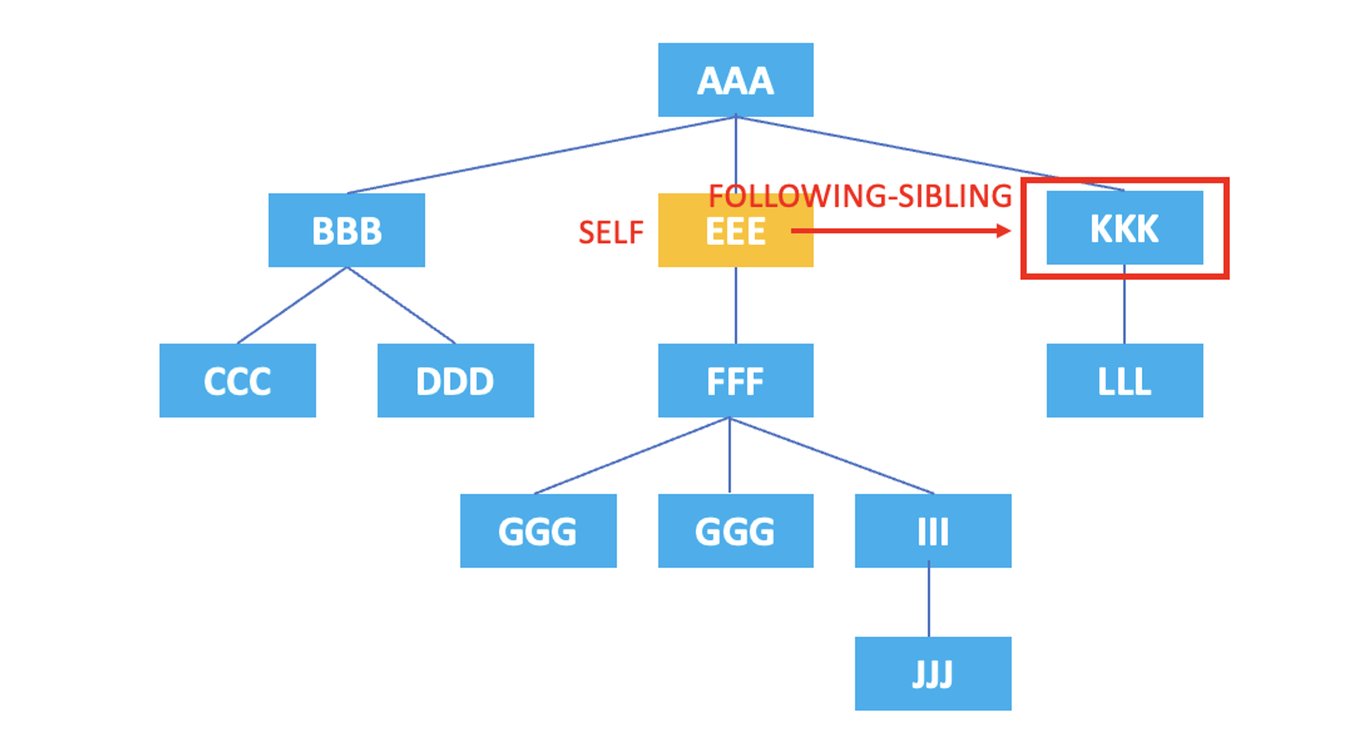
3.9. following-sibling
: Representa todos los nodos hermanos que aparecen después del nodo actual.
/AAA/EEE/following-sibling::*
El XPath anterior seleccionaría el nodo hermano <KKK> que aparece después del nodo <EEE> actual.
3.10. preceding-sibling
: Representa todos los nodos hermanos que aparecen antes del nodo actual.
/AAA/EEE/preceding-sibling::*
El XPath anterior seleccionaría el nodo hermano <BBB> que aparece antes del nodo <EEE> actual.
Hasta ahora, hemos discutido los ejes utilizados para representar nodos en XPath.
Además, exploraremos dos funciones adicionales que se pueden utilizar en XPath.
4. Funciones utilizadas en XPath
4.1. count
: Devuelve el número de nodos que cumplen una condición específica.
#class 속성 값이 ‘example인 div 요소의 개수를 반환
count(//div[@class="example"])
#p 요소의 총 개수를 반환
count(//p)
4.2. position
: Devuelve la posición del nodo actual. (La posición comienza en 1 y aumenta secuencialmente).
<root>
<item>Item 1</item>
<item>Item 2</item>
<item>Item 3</item>
</root>
Por ejemplo, con el siguiente código XML, se puede escribir un XPath de la siguiente manera.
//item[position() = 2]
Usando la función position, se puede seleccionar el segundo elemento item de los tres elementos item.
5. Conclusión
Hasta aquí, hemos cubierto el contenido avanzado de XPath. Si has dominado desde los conceptos básicos hasta los avanzados, es seguro decir que has adquirido un conocimiento fundamental necesario para encontrar y extraer datos con precisión de documentos XML utilizando XPath.
XPath es una herramienta poderosa para explorar y manipular documentos XML, y se utiliza en diversos campos como scraping de datos, web scraping, extracción de datos en servicios web basados en XML, entre otros. ¡Espero que tengas éxito al extraer y utilizar datos de manera eficiente con XPath!
Echa un vistazo a este artículo también:
Recopilación de datos, automatízalo ahora
Comienza en 5 minutos sin necesidad de programación · Experiencia en el scraping de más de 5,000 sitios web



