

1. Google 搜索控制台确认问题
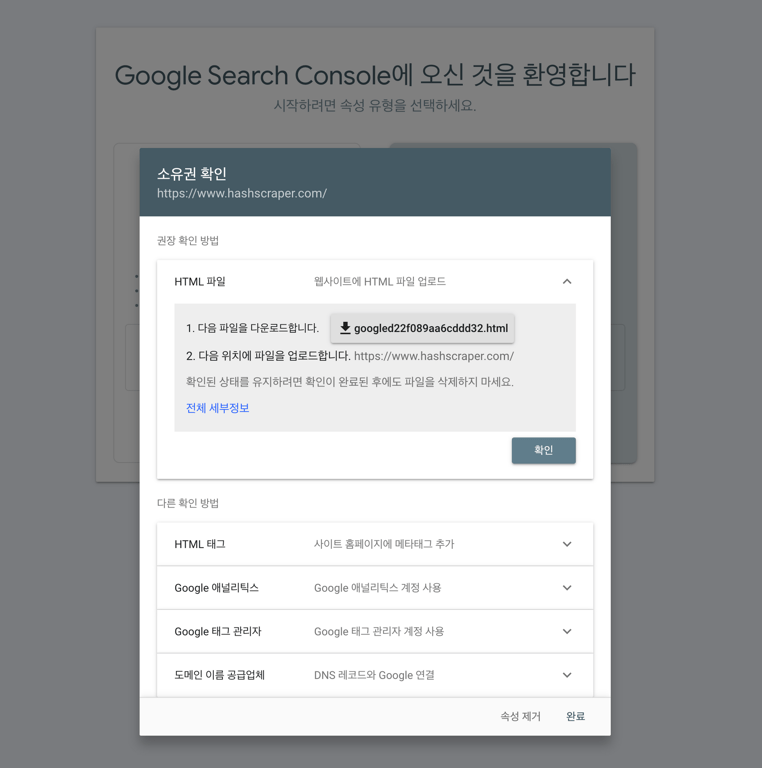
域名确认后,爬虫开始爬取数据后,几天后再访问,您将看到数据。
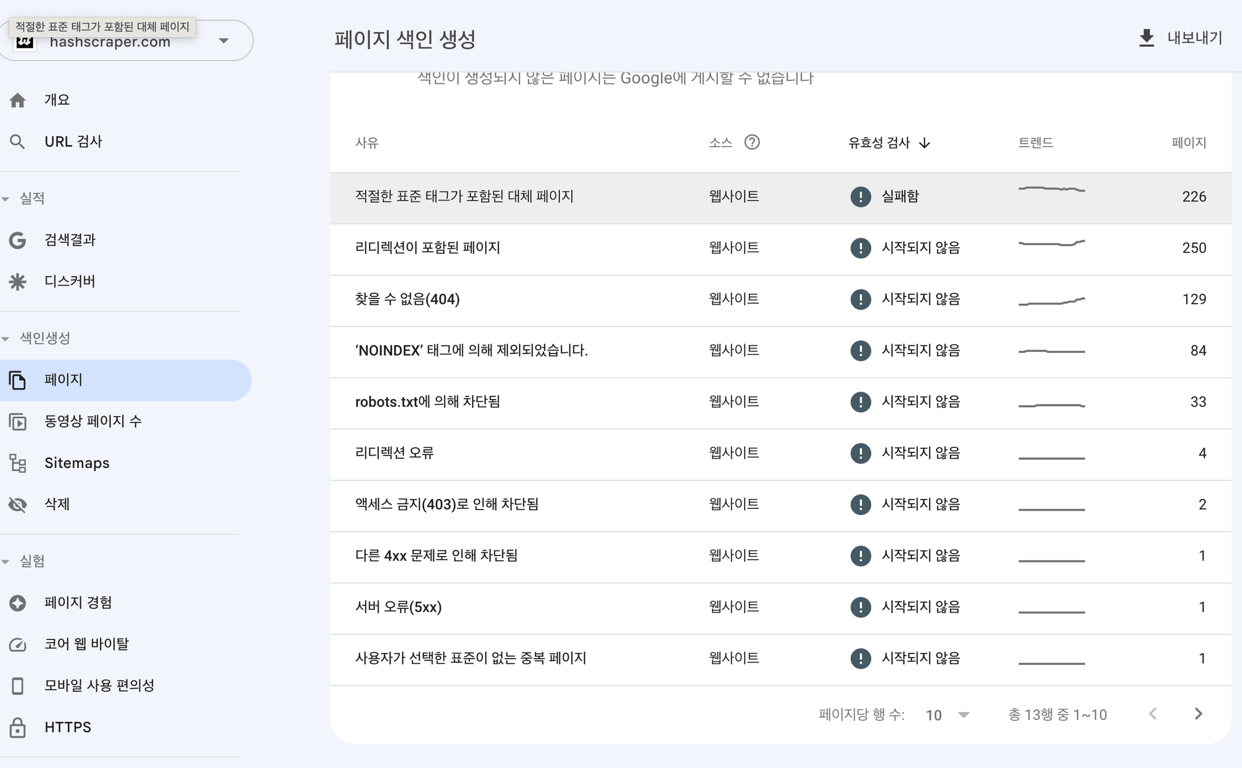
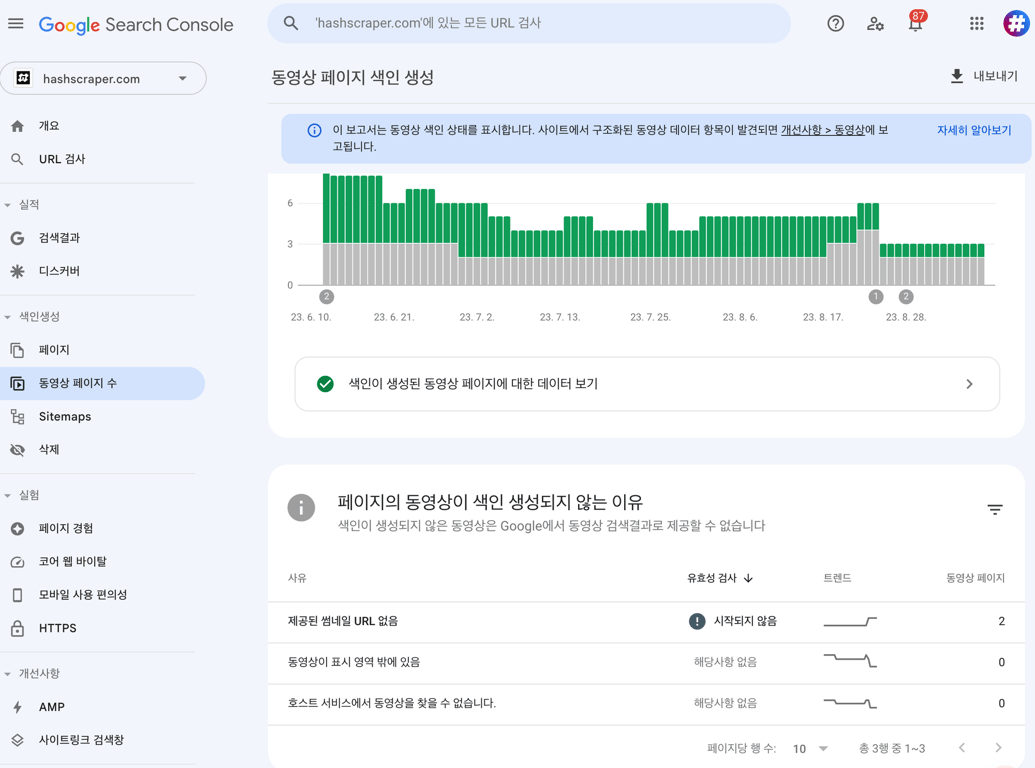
爬取时常见问题如下。
超时
连接被拒绝
连接失败
连接超时
无响应
大多数情况下,服务器错误通常是暂时性的,但如果错误持续,请检查服务器是否有问题
有时候可能是由于托管提供商的错误,请咨询托管提供商
如果 robots.txt 文件返回 200 或 404 错误,则表示搜索引擎在尝试检索此文件时遇到困难。
必须确保 robots.txt 网站地图没有错误并提交,或者检查服务器端是否对机器人进行了阻止。
2. 创建网站地图
爬虫首先查看主页上的站点地图,然后开始爬取。
制作无错误的站点地图可以使爬虫更容易爬取。
3. 定期更新新内容
定期制作新内容会导致搜索引擎更频繁地爬取您的网站。
4. 创建移动友好网站
随着移动优先索引的推出,必须创建针对移动设备优化的页面。
如果不优化移动设备,则可能会降低排名。
以下是创建移动友好网站的主要方法。
a. 实现响应式网页设计
b. 在内容中插入视口元标记
c. 最小化页面内资源(CSS 和 JS)
d. 使用 AMP 缓存为页面标记
e. 优化图像以缩短加载时间
f. 减小页面内 UI 元素的大小
在移动平台上测试网站并通过 Google PageSpeed 进行优化
页面速度是重要的排名因素,可能会影响搜索引擎爬取网站的速度。
5. 删除重复内容
重复内容页面会受到惩罚。
通过优化 canonical 标签或 meta 标签可以避免这种情况。
6. 限制特定页面的显示
如果要阻止搜索引擎爬取特定页面,可以使用以下方法。
放置 'noindex' 标签。
将 URL 放置在 robots.txt 文件中。
7. 在外部网站上创建回链到主页
回链是其他网站链接到您的网站。
这些链接将您的网站连接到权威来源的内容
搜索引擎通过这种方式评估您的网站的可信度和权威性。
如果链接来自可信赖的来源,则会产生更大的影响。
一起阅读:
数据收集,现在自动化
5 分钟即可开始,5000 多个网站爬取经验



