

1. Vérification des problèmes avec la Google Search Console
Après avoir vérifié le domaine, une fois que le robot de crawl a commencé à crawler, les données seront visibles après quelques jours lorsque vous revisitez le site.
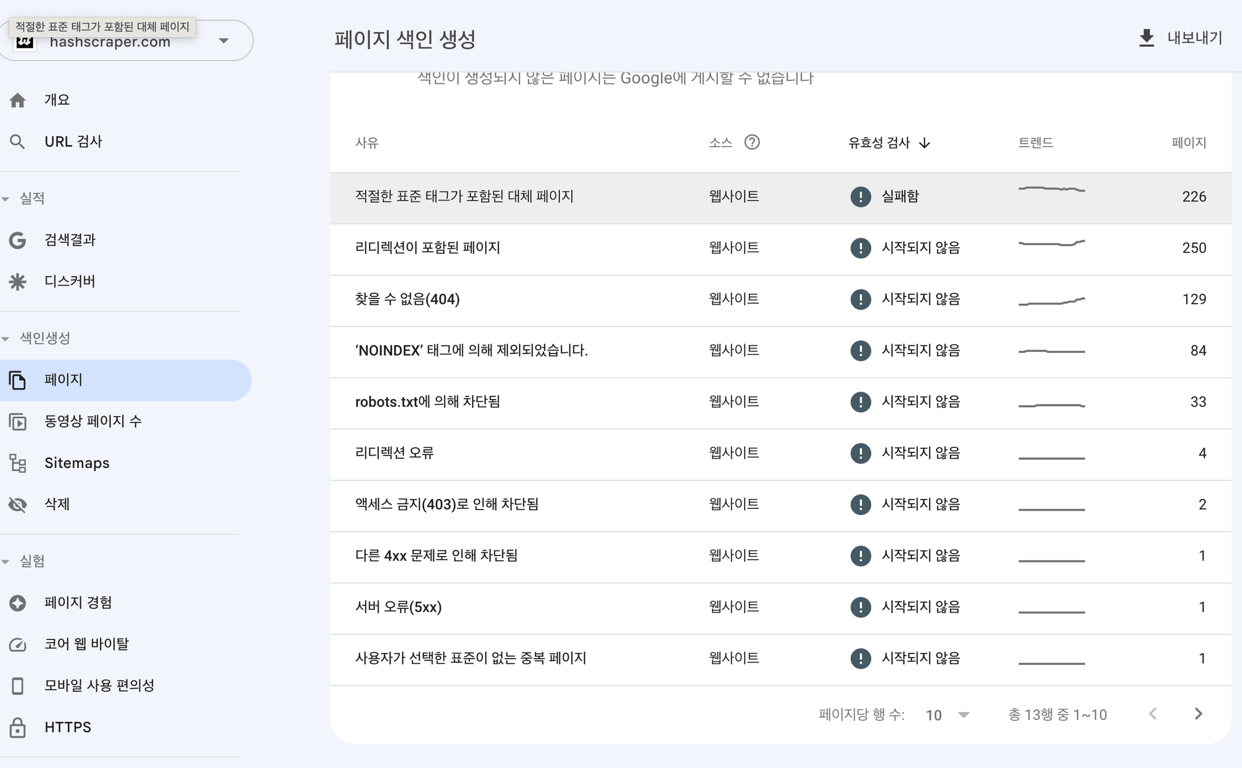
Les erreurs courantes lors du crawling sont les suivantes :
- Dépassement du temps
- Connexion refusée
- Échec de la connexion
- Délai de connexion dépassé
- Pas de réponse
En général, les erreurs de serveur sont souvent temporaires, mais si elles persistent, vérifiez s'il y a un problème avec le serveur. Parfois, les erreurs peuvent être dues à l'hébergeur, dans ce cas, contactez le fournisseur d'hébergement.
Si le fichier robots.txt renvoie une erreur 200 ou 404, cela signifie que les moteurs de recherche rencontrent des difficultés à accéder à ce fichier.
Vous devez vous assurer que le fichier robots.txt du site est exempt d'erreurs et le soumettre, ou vérifier s'il y a un blocage des bots au niveau du serveur.
2. Création d'un plan de site
Les crawlers commencent par consulter le plan de site de la page d'accueil pour commencer le crawling.
Créer un plan de site sans erreur rend le crawling plus facile pour les bots.
3. Mise à jour régulière du contenu
En produisant régulièrement de nouveaux contenus, les moteurs de recherche crawleront le site plus fréquemment.
4. Création d'un site adapté aux mobiles
Avec l'introduction de l'indexation mobile en premier, il est essentiel de créer des pages optimisées pour les mobiles.
Si le site n'est pas optimisé pour les mobiles, son classement peut en souffrir.
Voici quelques méthodes courantes pour créer un site adapté aux mobiles :
a. Implémentation du design web réactif
b. Inclusion de balises meta viewport dans le contenu
c. Minimisation des ressources (CSS et JS) sur la page
d. Attribution de balises de page aux pages via le cache AMP
e. Optimisation des images pour réduire le temps de chargement
f. Réduction de la taille des éléments d'interface utilisateur sur la page
Testez votre site web sur des plateformes mobiles et optimisez-le via Google PageSpeed.
La vitesse de la page est un facteur de classement important et peut influencer la vitesse à laquelle les moteurs de recherche crawlers accèdent au site.
5. Suppression du contenu en double
Les pages de contenu en double peuvent être pénalisées.
Vous pouvez éviter cela en optimisant les balises canoniques ou meta tags.
6. Limiter l'exposition de certaines pages
Si vous souhaitez empêcher les moteurs de recherche de crawler certaines pages, vous pouvez utiliser les méthodes suivantes :
- Placer la balise 'noindex'.
- Placer l'URL dans le fichier robots.txt.
7. Créer des backlinks vers votre site depuis des sites externes
Les backlinks sont des liens provenant d'autres sites web vers le vôtre.
Ces liens servent à relier votre site à des sources d'autorité sur un sujet donné.
Les moteurs de recherche utilisent cela pour évaluer la crédibilité et l'autorité de votre site.
Les liens provenant de sources fiables ont un impact plus important.
Consultez également cet article :
Collecte de données, automatisez maintenant
Commencez en 5 minutes sans codage · Expérience de crawling sur plus de 5 000 sites web



