

0. Aperçu
L'un des cas clients de Hashscraper a utilisé un modèle d'IA pour réduire le taux de défauts sur le site de production. J'ai rédigé cet article pour expliquer plus en détail les prédictions du modèle d'apprentissage automatique.
1. Définition du problème
1.1. Objectif
En bref, dans le cas client, les taux de défauts variaient d'une machine à l'autre en fonction de 128 variables. L'objectif était de prédire les produits défectueux à l'aide d'un modèle d'apprentissage automatique, d'analyser les variables responsables des défauts prédits et de les ajuster pour réduire le taux de défauts.
1.2. Hypothèse
Nous avons formulé l'hypothèse selon laquelle en extrayant et en ajustant les variables clés du processus à l'aide d'un modèle d'apprentissage automatique, nous pourrions réduire le taux de défauts.
2. Collecte de données
2.1. Détermination de la source de données
Nos clients nous ont fourni directement les données de chaque machine de l'usine. Comme il s'agit de données internes à l'entreprise, nous ne pouvons pas les partager publiquement, donc nous montrons juste une capture d'écran des dossiers.
2.2. Collecte de données
Nous avons demandé un minimum de 10 000 données et nos clients nous ont fourni autant de données que possible. Ainsi, nous avons reçu respectivement 3 931 données pour la machine 1, 16 473 pour la machine 2, 2 072 pour la machine 3, 16 129 pour la machine 4, 57 970 pour la machine 5 et 78 781 pour la machine 6. Au total, nous avons utilisé environ 175 000 données pour former notre modèle.
3. Prétraitement des données
3.3. Nettoyage des données
Le nettoyage des données est crucial pour former un modèle. Je dirais que plus de 80% de l'apprentissage automatique dépend du nettoyage des données. Si vous entraînez un modèle avec des données mal nettoyées, vous obtiendrez un modèle mal formé (en d'autres termes, si vous mettez des ordures en entrée, vous obtiendrez des ordures en sortie).
3.4. Séquence de travail
3.4.1.
Nous avons dû encoder les fichiers de différentes manières (certains en 'cp949', d'autres en 'utf-8') pour les lire à partir de fichiers CSV.
for file_path in file_paths:
try:
df = pd.read_csv(file_path, encoding='cp949', header=None)
except UnicodeDecodeError:
df = pd.read_csv(file_path, encoding='utf-8', header=None)
3.4.2.
Pour étiqueter les données, nous avons fusionné les colonnes de date et d'heure, puis les avons reliées aux données sur l'axe y.
for i in range(len(result_df_new) - 1):
start_time, end_time = result_df_new['Datetime'].iloc[i], result_df_new['Datetime'].iloc[i + 1]
selected_rows = df_yaxis[(df_yaxis['Datetime'] >= start_time) & (df_yaxis['Datetime'] < end_time)]
results.append(1 if all(selected_rows['결과'].str.contains('OK')) else 0)
results.append(0)
3.4.3.
Nous avons fusionné les données prétraitées pour chaque machine.
data = pd.concat([df1,df2,df3,df4,df6])
data.reset_index(drop=True,inplace=True)
3.4.4
Les données en double peuvent entraîner un biais dans l'ensemble de données et poser des problèmes de diversité et de surapprentissage du modèle. Par conséquent, nous avons supprimé toutes les données en double.
data = data.drop_duplicates().reset_index(drop=True)
Après ce prétraitement, nous avons effectué une analyse exploratoire des données.
3.4.5.
Nous avons visualisé les valeurs manquantes à l'aide de la bibliothèque missingno. Les colonnes avec de nombreuses valeurs manquantes ont été entièrement supprimées. Supprimer les colonnes avec de nombreuses valeurs manquantes est important pour les mêmes raisons évoquées précédemment. Cela peut poser des problèmes de diversité des données et de surapprentissage. Bien sûr, les valeurs manquantes peuvent également être importantes en fonction des données analysées. Cela peut varier en fonction des données analysées.
3.5. Ingénierie des fonctionnalités
L'ingénierie des fonctionnalités consiste à créer de nouvelles fonctionnalités ou à transformer des fonctionnalités existantes pour améliorer les performances du modèle. Comme nous considérions que chaque valeur de fonctionnalité était importante et que nous ne les connaissions pas toutes précisément, nous n'avons pas effectué d'ingénierie des fonctionnalités.
3.6. Analyse exploratoire des données (l'image ci-dessous montre une partie pour des raisons de sécurité)
Vérification de la distribution des données
Nous utilisons des graphiques tels que des histogrammes et des boîtes à moustaches pour vérifier la distribution des données.
.png?table=block&id=74533625-35d7-4939-96b3-60c4b3763ea6&cache=v2)

Analyse de la corrélation
Nous analysons la corrélation entre les fonctionnalités pour identifier les fonctionnalités importantes ou résoudre les problèmes de multicollinéarité.
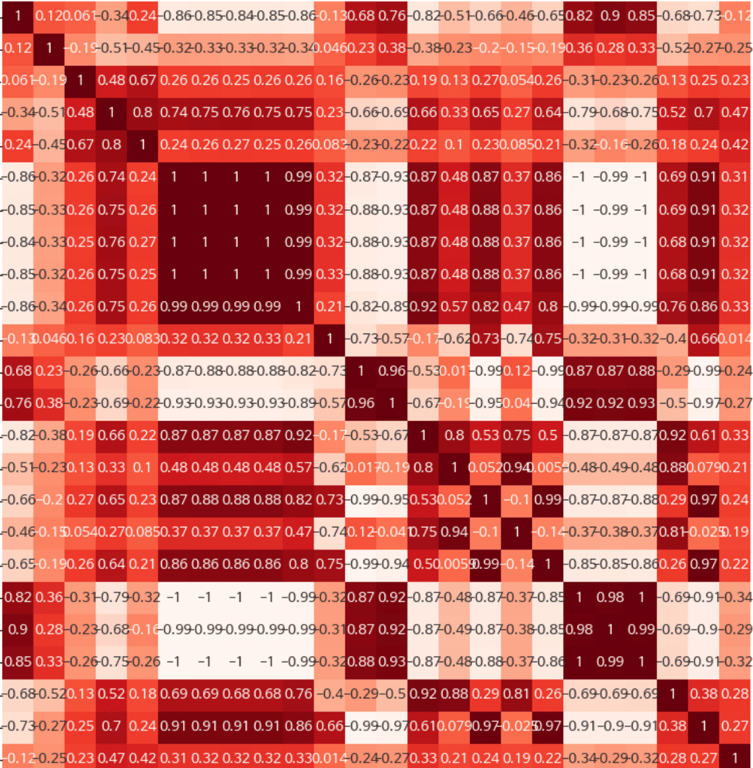
4. Types d'échantillonnage
4.1. Déséquilibre des données
Étant donné le déséquilibre des données, nous avons combiné plusieurs modèles en utilisant la sous-échantillonnage. La principale raison de la sous-échantillonnage en cas de fort déséquilibre est de lutter contre le surapprentissage. Notre objectif principal était de permettre au modèle d'apprendre sans être biaisé par des données spécifiques. Sous-échantillonnage aléatoire (RUS) : Supprime aléatoirement des données de la classe majoritaire pour équilibrer les classes. Il est simple et rapide à mettre en œuvre, mais il existe un risque de perte d'informations importantes.
4.2. NearMiss
Cette méthode consiste à conserver uniquement les k données de la classe majoritaire qui sont les plus proches des données de la classe minoritaire. Il existe plusieurs versions de NearMiss, chacune calculant légèrement différemment la distance entre les données de la classe minoritaire.
4.3. Tomek Links
En identifiant les paires de données les plus proches entre la classe minoritaire et la classe majoritaire, cette méthode supprime les données de la classe majoritaire. Cela permet de clarifier les limites entre les classes.
4.4. Edited Nearest Neighbors (ENN)
Pour chaque donnée de la classe majoritaire, cette méthode utilise l'algorithme des k plus proches voisins. Si la majorité des voisins les plus proches appartiennent à la classe minoritaire, ces données sont supprimées.
4.5. Neighbourhood Cleaning Rule (NCL)
C'est une version étendue de ENN qui supprime de manière plus efficace les données de la classe majoritaire pour nettoyer la zone autour de la classe minoritaire.
Nous avons essayé ces méthodes de sous-échantillonnage et avons également combiné sous-échantillonnage et suréchantillonnage. Cependant, la méthode qui convenait le mieux au modèle était l'ENN sous-échantillonnage, nous l'avons donc appliquée.
##### NearMiss 인스턴스 생성
nm = NearMiss()
##### 언더샘플링 수행
X_resampled, y_resampled = nm.fit_resample(data.drop('결과', axis=1), data['결과'])
##### 언더샘플링 결과를 DataFrame으로 변환
data_sample = pd.concat([X_resampled, y_resampled], axis=1)
5. Modélisation
5.1. Sélection du modèle
En fonction du type de problème (classification, régression, clustering, etc.), nous choisissons le modèle d'apprentissage automatique approprié. Nous avons testé plusieurs modèles, mais nous avons finalement choisi notre modèle en nous basant sur le meilleur modèle sélectionné par la bibliothèque pycrat. PyCaret est une bibliothèque open source d'automatisation de l'analyse de données et de l'apprentissage automatique en Python. PyCaret permet de construire et d'expérimenter rapidement des pipelines d'analyse de données et d'apprentissage automatique avec peu de code.
5.2. Entraînement du modèle
Nous avons formé notre modèle en utilisant les données d'apprentissage. Finalement, le modèle CatBoost a donné les valeurs les plus élevées pour l'AUC et le score F1.
- AUC (Area Under the Curve) :
L'AUC représente la zone sous la courbe ROC (Receiver Operating Characteristic).
La courbe ROC représente la sensibilité (taux de vrais positifs) sur l'axe y et 1-spécificité (taux de faux positifs) sur l'axe x.
La valeur de l'AUC est comprise entre 0 et 1, et plus elle est proche de 1, meilleure est la performance du classificateur. Une valeur de 0,5 correspond à une classification aléatoire.
L'AUC est particulièrement utile pour les distributions de classes déséquilibrées.
- Score F1 :
Le score F1 est la moyenne harmonique de la précision et du rappel.
La précision est le ratio des vrais positifs parmi les prédictions positives, et le rappel est le ratio des vrais positifs parmi les vrais positifs.
Le score F1 équilibre ces deux mesures, permettant de surmonter les limites des modèles optimisant uniquement l'une des deux.
La valeur du score F1 est comprise entre 0 et 1, et plus elle est élevée, meilleure est la performance du modèle.
6. Conclusion : Extraction des variables et ajout de fonctionnalités pour améliorer l'intuition
En fin de compte, nous avons mis en place un système qui récupère en temps réel les données brutes des machines de l'usine, effectue des prédictions à l'aide de ce modèle, extrait les variables liées aux défauts à l'aide de la bibliothèque SHAP, et crée un fichier Excel pour que les travailleurs de l'usine puissent facilement visualiser les résultats. Nous avons utilisé Pyinstaller pour automatiser ce processus et créer un fichier .exe, permettant aux utilisateurs de voir les variables et de déterminer si un produit est défectueux en un seul clic.
** Qu'est-ce que SHAP ?
SHAP signifie SHapley Additive exPlanations, un outil utilisé pour expliquer l'impact de chaque fonctionnalité d'un modèle d'apprentissage automatique sur les prédictions. Cela améliore la "transparence" du modèle et renforce la confiance dans la façon dont les prédictions sont faites.
Dans des cas comme celui-ci, Hashscraper mène des projets basés sur des modèles d'IA selon les méthodes mentionnées ci-dessus.
Lisez aussi cet article :
Collecte de données, automatisez-la maintenant
Commencez en 5 minutes sans codage · Expérience de plus de 5 000 sites Web crawlés



