

0. Aperçu
De nos jours, grâce à ChatGPT, le développement est devenu vraiment facile.
Est-il possible de créer facilement un bot de crawl avec ChatGPT?
Commençons le développement d'un bot de crawl Coupang (avec ChatGPT).
1. Rédaction de l'invite
1.1. Objectif
Nous souhaitons extraire des informations de base de chaque produit de la liste des résultats de recherche.
Nom du produit
Prix régulier
Prix de vente
Évaluation
Nombre de critiques
Informations sur la réduction par carte
Informations sur l'accumulation
Informations sur la livraison
1.2. Recherche de la liste de produits HTML
Trouvons l'élément HTML contenant la liste des produits
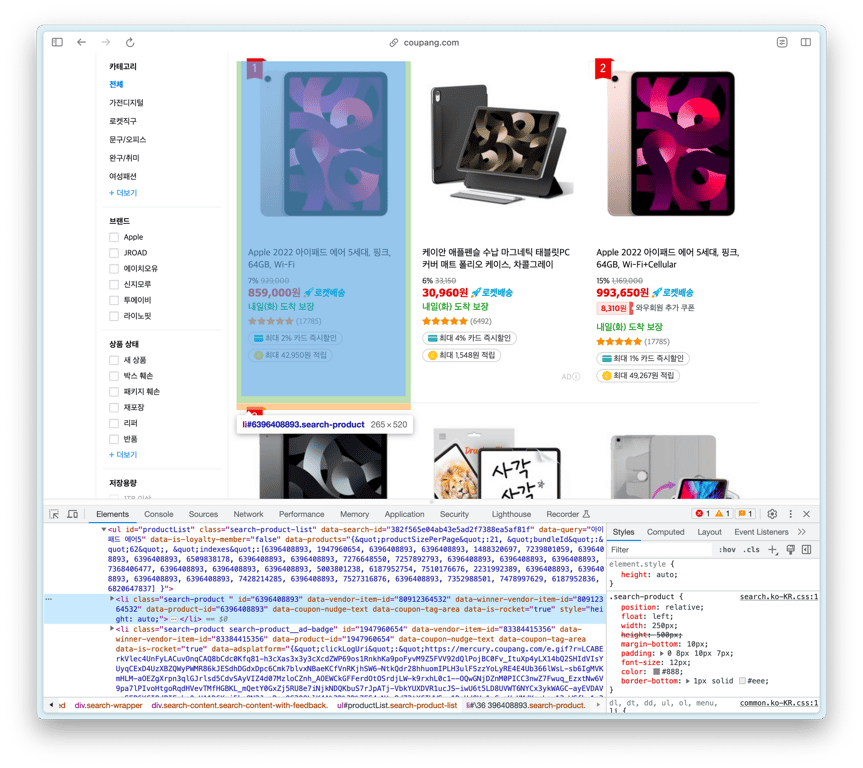
L'ul avec l'ID productList est la liste des produits, et chaque li à l'intérieur est un élément de produit.
Copions cet HTML ul ci-dessus et demandons à ChatGPT.
1.3. Réduction de la taille de l'HTML

ChatGPT a une limite de tokens, donc il ne peut pas traiter un HTML trop volumineux comme l'ul ci-dessus.
Nous devons réduire la taille de l'HTML en copiant le premier li de l'ul.
1.4. Considérations pour l'invite
Avant de rédiger l'invite, réfléchissons à ce que nous devons prendre en compte.
1⃣ Répéter pour tous les **li** de la liste de produits
Nous devons collecter tous les produits à l'intérieur de //ul[@id="productList"].
2⃣ Éliminer les produits publicitaires
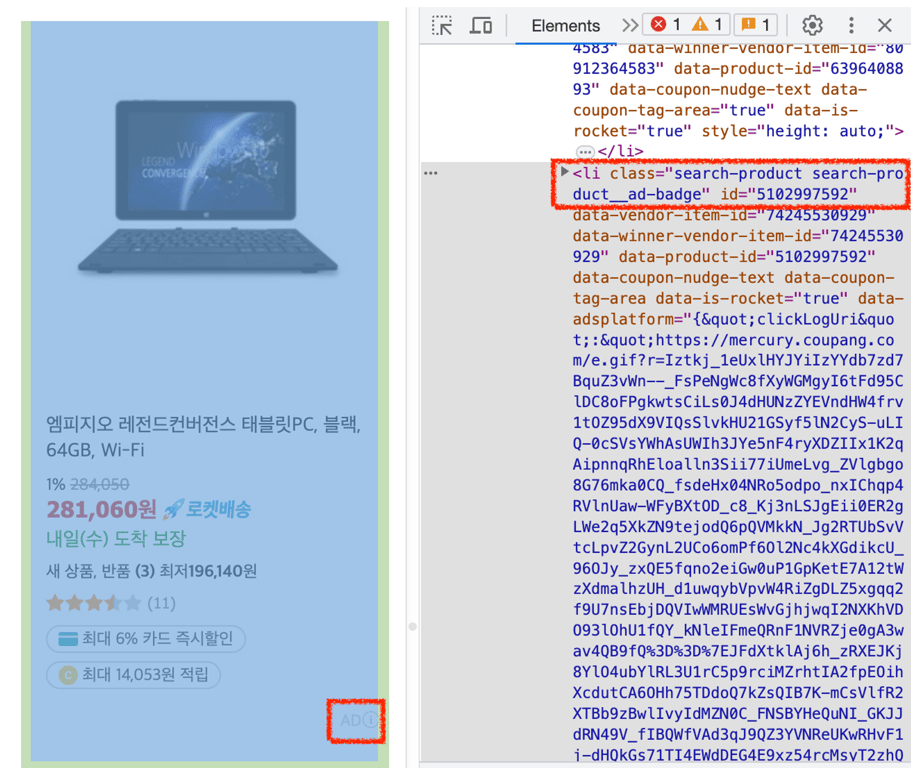
Si la classe contient search-product__ad-badge, il s'agit d'un produit publicitaire et ne doit pas être collecté.
1.5. Rédaction de l'invite pour ChatGPT
J'ai utilisé GPT-4 et voici comment j'ai formulé l'invite.
<<li의 HTML>>
상품 정보를 담고 있는 위의 HTML에서 상품 이름, 가격, 정가, 별점, 리뷰 개수, 카드 할인, 적립 정보, 배송 정보를 가져오는 웹 크롤러를 셀레니움을 사용하여 만들어 줘.
이 li 요소는 "//ul[@id='productList']" 안에 있으므로, 상품 리스트를 가져와 그 안의 li 태그에 대해 수집 작업을 반복하도록 코드를 생성해 줘.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
수집 내용을 콘솔에 출력할 때 각 상품마다 서로 구별될 수 있도록 구분선을 추가해 줘.
1.6. Résultat du codage par ChatGPT
## import 및 크롬 드라이버 설정 생략 ##
# 웹페이지 열기
driver.get('<https://www.coupang.com/np/search?component=&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&channel=auto>')
# 상품 리스트 가져오기
product_list = driver.find_element(By.XPATH, "//ul[@id='productList']")
# BeautifulSoup으로 파싱
soup = BeautifulSoup(product_list.get_attribute('outerHTML'), 'html.parser')
# 광고 상품 제외하고 각 상품 정보 가져오기
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
product_name = product.find("div", class_="name").text.strip()
original_price = product.find("del", class_="base-price").text.strip()
sale_price = product.find("strong", class_="price-value").text.strip()
rating = product.find("em", class_="rating").text.strip()
review_count = product.find("span", class_="rating-total-count").text.strip()
card_discount = product.find("span", class_="ccid-txt").text.strip() if product.find("span", class_="ccid-txt") else "N/A"
reward_info = product.find("span", class_="reward-cash-txt").text.strip() if product.find("span", class_="reward-cash-txt") else "N/A"
delivery_info = product.find("span", class_="arrival-info").text.strip()
# 콘솔에 출력
print('-'*40)
print("상품 이름:", product_name)
print("정가:", original_price)
print("판매 가격:", sale_price)
print("별점:", rating)
print("리뷰 개수:", review_count)
print("카드 할인 정보:", card_discount)
print("적립 정보:", reward_info)
print("배송 정보:", delivery_info)
driver.quit()
2. Débogage
Lorsque vous exécutez le code généré par ChatGPT, il y a de fortes chances que l'exécution ne se déroule pas correctement.
Dans cet exemple, j'ai rencontré immédiatement l'erreur suivante :
Traceback (most recent call last):
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 13, in <module>
AttributeError: 'NoneType' object has no attribute 'text'
Je vais maintenant vous montrer le processus de débogage.
2.1. AttributeError: 'NoneType' object has no attribute 'text'
** Situation du problème**
Vérifions le code qui extrait le nom du produit.
product_name = product.find("div", class_="name").text.strip()
Il s'agit du code qui trouve l'élément contenant le nom du produit et extrait le texte.
Cependant, si le div avec la classe "name" n'est pas trouvé, product.find("div", class_="name") devient un objet de type 'NoneType'.
Comme on ne peut pas extraire de texte de None, une AttributeError est déclenchée.
** Résolution de l'erreur**
Essayons de résoudre le problème par cas.
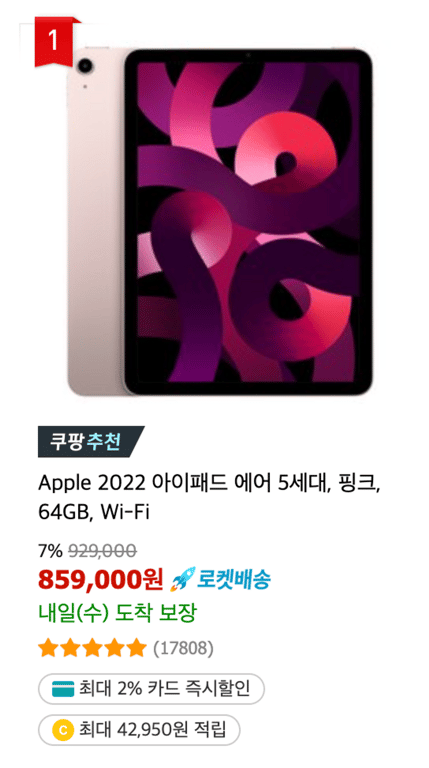
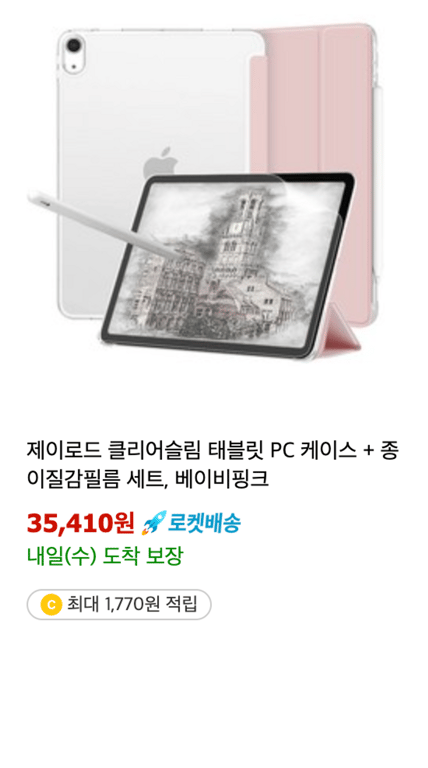
Comme le montrent les images ci-dessus, la quantité d'informations varie pour chaque produit.
Nous voulons donc diviser les types d'informations en deux catégories.
** Informations obligatoires**
Comme le nom du produit, le prix, etc., des informations qui doivent obligatoirement être présentes ne doivent pas être None.
Si c'est le cas, une erreur doit être déclenchée.
try:
# 요소를 찾음
product_name = product.find("div", class_="name").text.strip()
except AttributeError:
# 에러 발생 시 raise
raise AttributeError("상품 이름을 가져오는 중 에러가 발생했습니다.")
** Informations facultatives**
Pour des informations comme le nombre de critiques qui peuvent être absentes, un traitement différent est nécessaire.
Si l'élément contenant les informations n'est pas trouvé, nous allons assigner None à la variable.
# 요소를 찾음
review_count_span = product.find("span", class_="rating-total-count")
# 요소가 None이라면 변수에 None 할당
review_count = review_count_span.text.strip() if review_count_span else None
Cela peut également être écrit en une seule ligne :
review_count_span = product.find("span", class_="rating-total-count").text.strip() if product.find("span", class_="rating-total-count") else None
2.2. Saut des produits publicitaires
Voici ce qui était dans l'invite.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
En voyant cela, ChatGPT a généré le code suivant :
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
# ...후략
** Situation du problème**
Dans ce code, si un élément avec la classe 'search-product__ad-badge' est trouvé, il est sauté.
Le problème est que cela recherche la classe dans les éléments internes de product.
Cela semble être dû à une erreur dans la rédaction de l'invite, mais essayons de résoudre cela.
** Résolution**
if 'search-product__ad-badge' in product['class']:
continue
J'ai modifié la condition de saut dans la boucle pour rechercher la classe 'search-product__ad-badge' à l'intérieur de la classe de product.
2.3. Ajustement d'URL incomplet
Après avoir exécuté le bot de crawl, j'ai obtenu les URL des produits comme suit.
상품 URL: /vp/products/6396408893?itemId=13659935611&vendorItemId=80912364532&pickType=COU_PICK&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=c12ac6801b8042dbbe20f91a2e875bc0&rank=1
** Problème**
Lorsque vous parcourez un HTML avec BeautifulSoup, l'URL dans l'attribut href peut ne pas afficher l'URL complète.
En comparant l'URL ci-dessus avec l'URL réelle, on peut voir que la partie initiale https://www.coupang.com/ est manquante.
** Solution**
Ajoutons la partie manquante de l'URL.
product_url = "https://www.coupang.com" + product.find('a', class_='search-product-link')['href']
3. Vérification des résultats de collecte
Vérifions les données collectées avec le bot de crawl modifié.
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/6396408893?itemId=13659935634&vendorItemId=80912364549&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=e5fbb32250614118b4a65b814ec1b9ae&rank=10>
상품 이름: Apple 2022 아이패드 에어 5세대, 스타라이트, 256GB, Wi-Fi
정가: 1,169,000
판매 가격: 1,098,860
별점: 5.0
리뷰 개수: (17833)
카드 할인 정보: 최대 1% 카드 즉시할인
적립 정보: 최대 50,000원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/1947960654?itemId=5913484902&vendorItemId=83384415356&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 케이안 애플펜슬 수납 마그네틱 태블릿PC 커버 매트 폴리오 케이스, 차콜그레이
정가: 33,150
판매 가격: 30,960
별점: 5.0
리뷰 개수: (6498)
카드 할인 정보: 최대 4% 카드 즉시할인
적립 정보: 최대 1,548원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/5540742883?itemId=8726176862&vendorItemId=79466342181&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 신지모루 애플펜슬 수납 아이패드 클리어 케이스 + 강화유리 2P, 웜그레이
정가: 26,900
판매 가격: 25,900
별점: 5.0
리뷰 개수: (1313)
카드 할인 정보: 최대 2% 카드 즉시할인
적립 정보: 최대 1,295원 적립
배송 정보: 내일(목) 도착 보장
Bien que ce soit une structure de bot de crawl simple qui collecte uniquement les produits affichés dans les résultats de recherche, on peut voir qu'il est capable de recueillir un bon nombre d'informations!
4. Conclusion
Jusqu'à présent, nous avons examiné le processus de crawl des résultats de recherche de Coupang en utilisant ChatGPT. ChatGPT est un outil très utile, mais il a nécessité un peu de débogage et de modification. Malgré tout, nous avons pu obtenir des résultats assez utilisables.
Cependant, pour collecter efficacement les résultats de recherche de Coupang, plusieurs aspects doivent être pris en compte. Coupang détecte et bloque rapidement les bots, donc des solutions efficaces pour contourner cela sont nécessaires. De plus, pour collecter des informations qui varient en fonction de la connexion, des actions supplémentaires sont nécessaires en fonction de l'état de connexion. Ces contraintes rendent le processus de crawl complexe et peuvent poser des difficultés pour une collecte d'informations précise et rapide.
Pour résoudre efficacement ces problèmes, des outils et services spécialisés sont nécessaires. HashScraper propose un service professionnel de crawl web capable de résoudre ces problèmes complexes. Vous pouvez collecter facilement et rapidement une grande variété d'informations de Coupang sans rencontrer d'obstacles.
Dans ce post, nous avons exploré comment développer un crawler web en utilisant ChatGPT. Bien qu'il existe de nombreux outils et méthodes, si vous recherchez une collecte d'informations efficace et précise, je vous recommande d'utiliser un service professionnel.
Merci.
Consultez également cet article :
Collecte de données, automatisez maintenant
Commencez en 5 minutes sans coder · Expérience de crawl sur plus de 5 000 sites web



