

0. 概要
最近はChatGPTのおかげで本当に開発が簡単になった世界です。果たしてクローリングボットもChatGPTと一緒なら簡単に作成できるでしょうか?Coupangのクローリングボットの開発(ChatGPTを使用)、始めてみましょう。
1. プロンプトの作成
1.1. 目標
検索結果に表示される商品リストから各商品の基本情報を取得したいです。
- 商品名
- 定価
- 販売価格
- 評価
- レビュー数
- カード割引情報
- ポイント情報
- 配送情報
1.2. 商品リストのHTMLを見つける
商品リストを含むHTML要素を見つけましょう
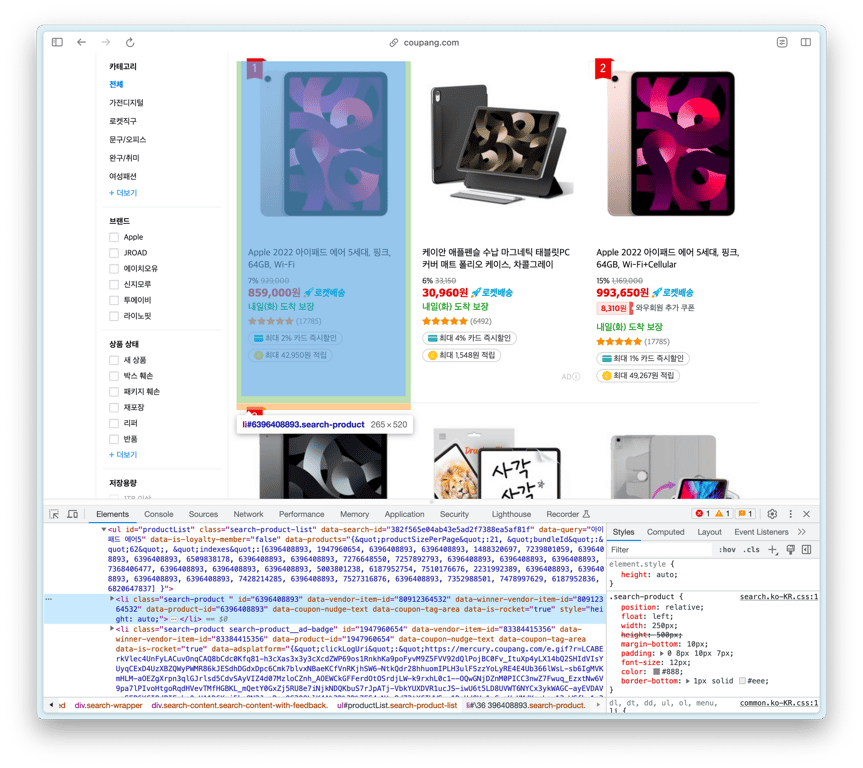
idがproductListであるulが商品リストであり、その中にある各liが商品要素であることがわかります。
それでは、上記のulのHTMLをコピーしてChatGPTに尋ねましょうか?
1.3. HTMLのサイズを縮小

ChatGPTにはトークン数の制限があるため、上記のように大きなHTMLは処理できません。
HTMLのサイズを縮小する必要があるため、ulの最初のliのHTMLをコピーして再度尋ねてみましょう。
1.4. プロンプトの考慮事項
プロンプトを作成する前に、考慮すべきことを整理してみましょう。
1⃣ 商品リスト内のすべての **li**に対して繰り返し
//ul[@id="productList"]内のすべての商品を収集するようにします。
2⃣ 広告商品の除外
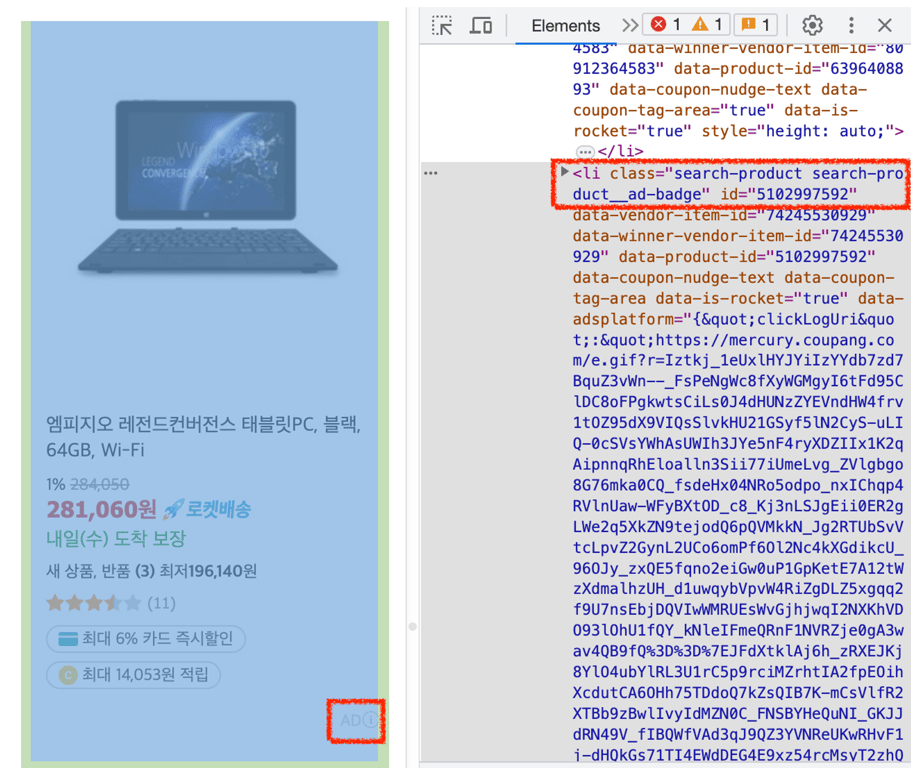
classにsearch-product__ad-badgeが含まれている場合、広告商品であるためその商品は収集されないようにします。
1.5. ChatGPTにプロンプトを作成する
GPT-4を使用し、プロンプトは次のように入力しました。
<<li의 HTML>>
상품 정보를 담고 있는 위의 HTML에서 상품 이름, 가격, 정가, 별점, 리뷰 개수, 카드 할인, 적립 정보, 배송 정보를 가져오는 웹 크롤러를 셀레니움을 사용하여 만들어 줘.
이 li 요소는 "//ul[@id='productList']" 안에 있으므로, 상품 리스트를 가져와 그 안의 li 태그에 대해 수집 작업을 반복하도록 코드를 생성해 줘.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
수집 내용을 콘솔에 출력할 때 각 상품마다 서로 구별될 수 있도록 구분선을 추가해 줘.
1.6. ChatGPTのコーディング結果
## import 및 크롬 드라이버 설정 생략 ##
# 웹페이지 열기
driver.get('<https://www.coupang.com/np/search?component=&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&channel=auto>')
# 상품 리스트 가져오기
product_list = driver.find_element(By.XPATH, "//ul[@id='productList']")
# BeautifulSoup으로 파싱
soup = BeautifulSoup(product_list.get_attribute('outerHTML'), 'html.parser')
# 광고 상품 제외하고 각 상품 정보 가져오기
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
product_name = product.find("div", class_="name").text.strip()
original_price = product.find("del", class_="base-price").text.strip()
sale_price = product.find("strong", class_="price-value").text.strip()
rating = product.find("em", class_="rating").text.strip()
review_count = product.find("span", class_="rating-total-count").text.strip()
card_discount = product.find("span", class_="ccid-txt").text.strip() if product.find("span", class_="ccid-txt") else "N/A"
reward_info = product.find("span", class_="reward-cash-txt").text.strip() if product.find("span", class_="reward-cash-txt") else "N/A"
delivery_info = product.find("span", class_="arrival-info").text.strip()
# 콘솔에 출력
print('-'*40)
print("상품 이름:", product_name)
print("정가:", original_price)
print("판매 가격:", sale_price)
print("별점:", rating)
print("리뷰 개수:", review_count)
print("카드 할인 정보:", card_discount)
print("적립 정보:", reward_info)
print("배송 정보:", delivery_info)
driver.quit()
2. デバッグ
ChatGPTが生成したコードを実行すると、正常に実行されない可能性が高いです。
この例でもすぐに以下のエラーに遭遇しました:
Traceback (most recent call last):
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 13, in <module>
AttributeError: 'NoneType' object has no attribute 'text'
これからデバッグプロセスをご紹介します。
2.1. AttributeError: 'NoneType' object has no attribute 'text'
問題点
商品名を取得するコードを確認してみます。
product_name = product.find("div", class_="name").text.strip()
商品名を持つ要素を見つけてテキストを取得するコードです。
しかし、もしclassが"name"であるdivを見つけられない場合、product.find("div", class_="name")は'NoneType'オブジェクトになります。
Noneからはテキストを取得できないため、AttributeErrorが発生することになります。
エラーの解決
ケースごとに解決してみましょう。
上記の画像からわかるように、商品ごとに情報量が異なります。
そのため、情報の種類を2つに分けることにします。
必須の情報
商品名、価格など、必ず存在する情報はNoneであってはいけません。
これらがNoneであればエラーを発生させる必要があります。
try:
# 요소를 찾음
product_name = product.find("div", class_="name").text.strip()
except AttributeError:
# 에러 발생 시 raise
raise AttributeError("상품 이름을 가져오는 중 에러가 발생했습니다.")
不要な情報
レビュー数など、存在しなくてもよい情報には別の処理が必要です。
情報を含む要素が見つからなかった場合、変数にNoneを割り当てるようにします。
# 요소를 찾음
review_count_span = product.find("span", class_="rating-total-count")
# 요소가 None이라면 변수에 None 할당
review_count = review_count_span.text.strip() if review_count_span else None
これを1行で書くこともできます:
review_count_span = product.find("span", class_="rating-total-count").text.strip() if product.find("span", class_="rating-total-count") else None
2.2. 広告商品をスキップ
プロンプトには以下の内容がありました。
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
これを見てChatGPTは次のようなコードを生成しました:
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
# ...후략
問題点
上記のコードでは、classが'search-product__ad-badge'である要素を見つけた場合にスキップするようになっています。
問題は、これをproductの内部要素で検索していることです。
おそらくこれは私がプロンプトを正確に書かなかったために発生した問題のようですが、解決してみましょう。
解決方法
if 'search-product__ad-badge' in product['class']:
continue
ループ内でスキップする条件を上記のように変更して、productのクラスに'search-product__ad-badge'が含まれるように修正しました。
2.3. 不完全なURLの修正
クローリングボットを実行した結果、以下のように商品のURLを取得しました。
상품 URL: /vp/products/6396408893?itemId=13659935611&vendorItemId=80912364532&pickType=COU_PICK&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=c12ac6801b8042dbbe20f91a2e875bc0&rank=1
問題
BeautifulSoupでHTMLを解析して収集する場合、href属性にURLが完全に表示されていないことがあります。
上記のURLと実際のURLを比較すると、先頭にhttps://www.coupang.com/が欠けていることがわかります。
解決方法
URLの先頭部分を追加してください。
product_url = "https://www.coupang.com" + product.find('a', class_='search-product-link')['href']
3. 収集結果の確認
修正されたクローリングボットで収集されたデータを確認しましょう。
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/6396408893?itemId=13659935634&vendorItemId=80912364549&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=e5fbb32250614118b4a65b814ec1b9ae&rank=10>
상품 이름: Apple 2022 아이패드 에어 5세대, 스타라이트, 256GB, Wi-Fi
정가: 1,169,000
판매 가격: 1,098,860
별점: 5.0
리뷰 개수: (17833)
카드 할인 정보: 최대 1% 카드 즉시할인
적립 정보: 최대 50,000원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/1947960654?itemId=5913484902&vendorItemId=83384415356&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 케이안 애플펜슬 수납 마그네틱 태블릿PC 커버 매트 폴리오 케이스, 차콜그레이
정가: 33,150
판매 가격: 30,960
별점: 5.0
리뷰 개수: (6498)
카드 할인 정보: 최대 4% 카드 즉시할인
적립 정보: 최대 1,548원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/5540742883?itemId=8726176862&vendorItemId=79466342181&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 신지모루 애플펜슬 수납 아이패드 클리어 케이스 + 강화유리 2P, 웜그레이
정가: 26,900
판매 가격: 25,900
별점: 5.0
리뷰 개수: (1313)
카드 할인 정보: 최대 2% 카드 즉시할인
적립 정보: 최대 1,295원 적립
배송 정보: 내일(목) 도착 보장
表示される商品のみを収集する簡単な構造のクローリングボットですが、かなり多くの情報を取得できることが確認できます!
4. 結論
これまでChatGPTを使用してCoupangの検索結果をクロールするプロセスを見てきました。ChatGPTは非常に便利なツールですが、少しのデバッグと修正が必要でした。それでも、かなり使える結果を得ることができました。
しかし、Coupangの検索結果をスムーズに収集するには、さまざまな点を考慮する必要があります。Coupangはボットを素早く検出してブロックするため、これを効果的に回避する方法が必要であり、ログイン状態によって表示が異なる情報を収集するには追加の作業が必要です。これらの制約はクローリング作業を複雑にし、正確で迅速な情報収集に困難をもたらす可能性があります。
これらの問題を効果的に解決するには、専門的なツールやサービスが必要です。HashScraperは、これらの複雑な問題を解決できる専門のWebクローリングサービスを提供しています。スムーズかつ迅速にCoupangのさまざまな情報を収集することができます。
このポストを通じて、ChatGPTを使用してWebクローラーを開発する方法を学びました。さまざまなツールや方法がありますが、最も効率的で正確な情報収集を望む場合は、専門のサービスを利用することをお勧めします。
ありがとうございました。
この記事もチェックしてみてください:
データ収集、自動化しましょう
コーディング不要、5分で開始・5,000以上のウェブサイトをクロールした経験



