해시스크래퍼 고객사례 중 하나로 AI모델을 통하여 공정에서 나타는 불량률을 줄이기 위해 AI모델을 사용하였습니다. 머신러닝 모델의 예측을 좀 더 깊고 이해하기 쉽게 설명해드리고자 글을 작성하였습니다.
1.문제 정의
1.1. 목표 설정
먼저 고객 사례를 간략하게 설명해드리자면, 128개의 변수들에 나와있는 것을 토대로 물건을 만드는데에 있어서 각 호기마다 불량률이 차이가 났고, 불량품에 대한 예측을 머신러닝 모델을 통해서 하고나서, 머신러닝 모델을 통해 어떠한 변수들이 불량을 나오게 했는지 분석하여 그 변수들을 조절해 불량률을 줄이는 것이 목표였습니다.
1.2. 가설 수립
공정과정에서 머신러닝 모델을 통해 주요 변수들을 추출하여 조절하면 공정률을 낮출 것이라는 가설을 세웠습니다.
2. 데이터 수집
2.1. 데이터 소스 결정
데이터 소스들은 저희 고객께서 공장에서 직접 각 호기마다의 데이터들을 제공하여 주셨습니다.
이 데이터는 회사내부데이터이므로 직접적인 공개는 어려워 폴더만 캡쳐해서 보여드립니다.
2.2. 데이터 수집
필요한 데이터는 최소 1만건을 요청을 드렸었고, 그에 있어서 최대한 많은 데이터를 주셨으면 좋겠다고 말씀을 드렸었습니다. 그래서 받은 raw 데이터는 1호기 3931개, 2호기 16473개, 3호기 2072개, 4호기 16129개, 5호기 57970개, 6호기 78781개 입니다. 총 로우 데이터의 개수는 대략 17만 5천개의 데이터를 활용하여 모델을 학습하였습니다.
3. 데이터 전처리
3.3. 데이터 정제
모델을 학습하는데에 있어서 데이터의 정제는 굉장히 중요합니다. 제가 생각하기에는 머신러닝을 통한 데이터학습에 8할이상이라고 말씀드릴 수 있을 것 같습니다. 데이터 정제가 잘 안된 데이터를 학습하게 된다면, 결국에 머신러닝 또한 학습이 잘 되지않는 모델이 나옵니다.(쉽게 말씀드리면 쓰레기를 넣으면 쓰레기가 나온다고 생각하시면 됩니다.)
3.4. 작업 순서
3.4.1.
일단 파일을 불러오는데, csv를 읽어들이는데에 있어서 encoding형식이 모두 달라 어떠한 것은 'cp949' 어떠한 것은 'utf-8'로 인코딩을 해서 읽어왔습니다.
for file_path in file_paths:
try:
df = pd.read_csv(file_path, encoding='cp949', header=None)
except UnicodeDecodeError:
df = pd.read_csv(file_path, encoding='utf-8', header=None)
3.4.2.
라벨링을 해주기 위해서 날짜와 시간 열을 합쳐주고, 그 시간에 나온 y축데이터와 연결시켜주기
for i in range(len(result_df_new) - 1):
start_time, end_time = result_df_new['Datetime'].iloc[i], result_df_new['Datetime'].iloc[i + 1]
selected_rows = df_yaxis[(df_yaxis['Datetime'] >= start_time) & (df_yaxis['Datetime'] < end_time)]
results.append(1 if all(selected_rows['결과'].str.contains('OK')) else 0)
results.append(0)
3.4.3.
호기마다 전처리된 데이터 합쳐주기
data = pd.concat([df1,df2,df3,df4,df6])
data.reset_index(drop=True,inplace=True)
3.4.4
중복 데이터들은 데이터셋에 편향을 초래할 수 잇고, 모델이 데이터의 다양성을 학습하는데에 문제가 될 수 있습니다. 또한 과적합문제가 생길 수 있기때문에 중복데이터는 모두 제거
data = data.drop_duplicates().reset_index(drop=True)
그리고 이정도의 전처리를 하고나서 어느정도 EDA를 해보았습니다.
3.4.5.
missingno라이브러리를 통해서 결측치값을 시각화하였습니다. 그리고 결측치가 많은 열은 아예 제거를 하였습니다. 결측치가 많은 컬럼을 제거해주는 이유는 위와 비슷한 이유입니다. 데이터의 다양성을 학습하는데 문제가되고, 과적합에 문제가 될 수 있습니다. 물론, 데이터에 대해서 결측치도 중요한 값이 될 수 있습니다. 이것은 분석하는 데이터에 따라 달라질 수 있습니다.
3.5. 피처 엔지니어링
모델의 성능을 향상시키기 위해 새로운 피처를 생성하거나 기존의 피처를 변형하는 것이 피처 엔지니어링이라고 볼 수 있는데, 저희는 피쳐값 하나하나 모두 정확히 알지를 못하고, 피쳐값이 모두 중요하다고 봤기때문에 피쳐엔지니어링은 따로 해주지 않았습니다.
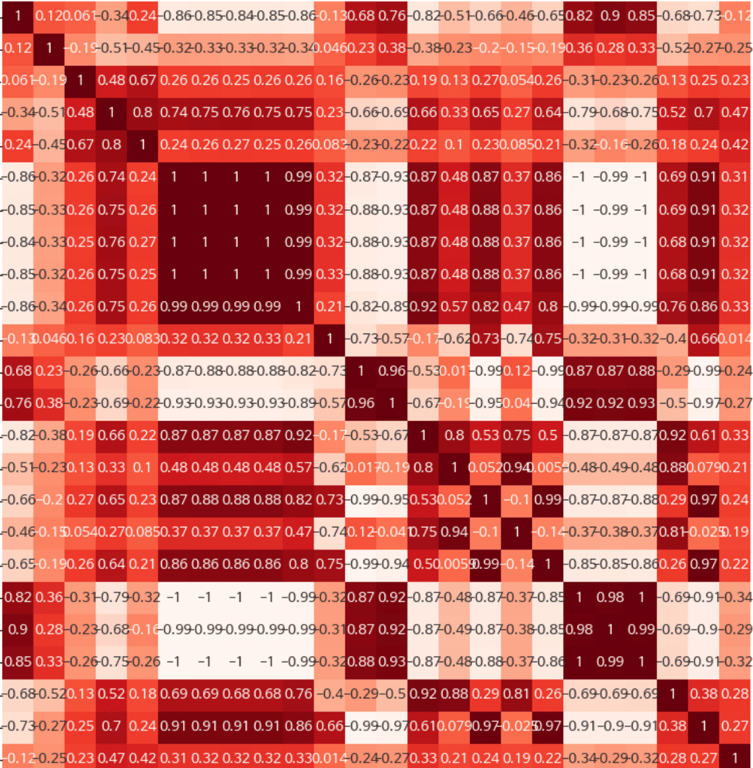
3.6. EDA(아래 캡처이미지는 보안상 일부만 보여드립니다)
데이터 분포 확인
히스토그램, 박스 플롯 등의 그래프를 사용하여 데이터의 분포를 확인합니다.
상관 관계 분석
피처 간의 상관 관계를 분석하여 중요한 피처를 파악하거나 다중 공선성 문제를 해결합니다.
4. 샘플링 유형
4.1. 데이터 불균형도
데이터에 대해서 불균형도가 많이 있었기 때문에 언더샘플링을 통하여 여러 모델과 결합을 해보았습니다. 불균형도가 클때 언더샘플링을 해주는 이유 역시, 과적합문제가 가장 큽니다. 모델이 학습하는데에 있어서 어떠한 데이터에 치우치지 않고 학습하는 것을 가장 큰 목표로 두었습니다. Random Under-sampling (RUS): 다수 클래스에서 임의로 데이터를 제거하여 클래스 불균형을 해소합니다. 단순하고 빠르게 구현할 수 있지만, 중요한 정보가 손실될 위험이 있습니다.
4.2. NearMiss
소수 클래스의 데이터와 가장 가까운 k개의 다수 클래스 데이터만을 유지하는 방식입니다. NearMiss에는 여러 버전이 있으며, 각 버전마다 소수 클래스 데이터와의 거리를 계산하는 방식이 조금씩 다릅니다.
4.3. Tomek Links
소수 클래스와 다수 클래스의 데이터 쌍 중에서 서로 가장 가까운 데이터 쌍을 찾아, 다수 클래스의 데이터를 제거합니다. 이로써 클래스 간의 경계를 명확하게 합니다.
4.4. Edited Nearest Neighbors (ENN)
모든 다수 클래스 데이터에 대해 k-NN 알고리즘을 사용하고, 만약 다수의 최근접 이웃이 소수 클래스에 속한다면 그 데이터를 제거합니다.
4.5. Neighbourhood Cleaning Rule (NCL)
ENN의 확장된 버전으로, 다수 클래스의 데이터를 더욱 효과적으로 제거하여 소수 클래스 주변의 영역을 깔끔하게 정리합니다.
위와 같은 언더샘플링도 해보았고, 언더샘플링과 오버샘플링을 결합을 해보기도 하였습니다. 하지만 모델과 가장 적합했던 것은 ENN 언더 샘플링이라고 판단되어 ENN을 적용하였습니다.
##### NearMiss 인스턴스 생성
nm = NearMiss()
##### 언더샘플링 수행
X_resampled, y_resampled = nm.fit_resample(data.drop('결과', axis=1), data['결과'])
##### 언더샘플링 결과를 DataFrame으로 변환
data_sample = pd.concat([X_resampled, y_resampled], axis=1)
5. 모델링
5.1. 모델 선택
문제의 유형(분류, 회귀, 클러스터링 등)에 따라 적절한 머신러닝 모델을 선택합니다.
모델 선택에 있어서는 직접적으로 여러 모델을 돌려보기도 했지만 pycrat라이브러리를 통해서
best로 뽑히는 모델을 참고하여 모델을 선택하였습니다.PyCaret은 Python의 오픈소스 데이터 분석 및 머신러닝 자동화 라이브러리입니다. PyCaret은 사용자에게 적은 코드량으로 전체 데이터 분석 및 머신러닝 파이프라인을 빠르게 구축하고 실험하는 능력을 제공합니다.
5.2. 모델 훈련
학습 데이터를 사용하여 모델을 훈련시킵니다.
최종적으로는 catboost모델을 통해서 AUC값과 f1-score값이 제일 높게 나왔습니다.
AUC (Area Under the Curve):
AUC는 ROC (Receiver Operating Characteristic) 커브 아래의 영역을 의미합니다.
ROC 커브는 민감도 (True Positive Rate)를 y축에, 1-특이도 (False Positive Rate)를 x축에 놓고 그려집니다.
AUC 값은 0과 1 사이에 있으며, 값이 1에 가까울수록 분류기의 성능이 좋다고 판단합니다. 반면 0.5는 무작위 분류의 성능과 같습니다.
AUC는 불균형한 클래스 분포에서 특히 유용하게 사용됩니다.
F1-Score:
F1-Score는 정밀도 (Precision)와 재현율 (Recall)의 조화 평균입니다.
정밀도는 양성으로 예측한 것 중 실제 양성의 비율이며, 재현율은 실제 양성 중 양성으로 올바르게 예측된 비율입니다.
F1-Score는 두 지표의 균형을 나타내므로, 어느 한 쪽만을 최적화하는 모델의 한계를 극복하기 위해 사용됩니다.
F1-Score의 값은 0과 1 사이에 있으며, 값이 높을수록 모델의 성능이 좋다고 판단합니다.
6. 마무리 : 변수도출과 직관성을 높인 기능 추가
최종적으로는 공장에 있는 기계가 도출해내는 로우데이터를 실시간으로 받아와서 이 모델을 통해서 예측을 하고, SHAP라이브러리를 통해서 불량이 나온것들에 대한 변수들을 도출해냈습니다.
그리고 또한 공장에서 작업하시는 일반인 분들을 위해서 Pyinstaller를 통해서 이러한 일련의 과정들에서 엑셀파일이 최종적으로 나와서 쉽게 볼 수 있게 하였고, exe파일을 생성하여 클릭 한번으로 해당 로우데이터에 대해서 변수들과 불량품인지 아닌지 판단할 수 있게 엑셀로 보이게 했습니다.
** SHAP란?
SHAP는 SHapley Additive exPlanations의 약자로, 머신러닝 모델의 각 피처가 예측에 얼마나 영향을 미쳤는지를 설명하는 데 사용되는 도구입니다. 이는 모델의 '투명성'을 높이고, 그로 인해 예측이 어떻게 이루어졌는지에 대한 신뢰도를 향상시킬 수 있습니다.
해시스크래퍼는 위와 같은 사례에서는 상기 방식의 AI모델을 토대로 프로젝트를 진행하고 있습니다.

.png?table=block&id=74533625-35d7-4939-96b3-60c4b3763ea6&cache=v2)