

0. Resumen
Hoy en día, gracias a ChatGPT, el mundo se ha vuelto mucho más fácil de desarrollar.
¿Realmente sería fácil crear un bot de web scraping con ChatGPT?
Vamos a intentar desarrollar un bot de web scraping de Coupang (con ChatGPT).
1. Escritura de la solicitud
1.1. Objetivo
Queremos obtener información básica de cada producto en la lista de productos que aparecen en los resultados de búsqueda.
Nombre del producto
Precio regular
Precio de venta
Calificación
Número de reseñas
Información de descuento con tarjeta
Información de acumulación
Información de envío
1.2. Encontrar el HTML de la lista de productos
Busquemos el elemento HTML que contiene la lista de productos
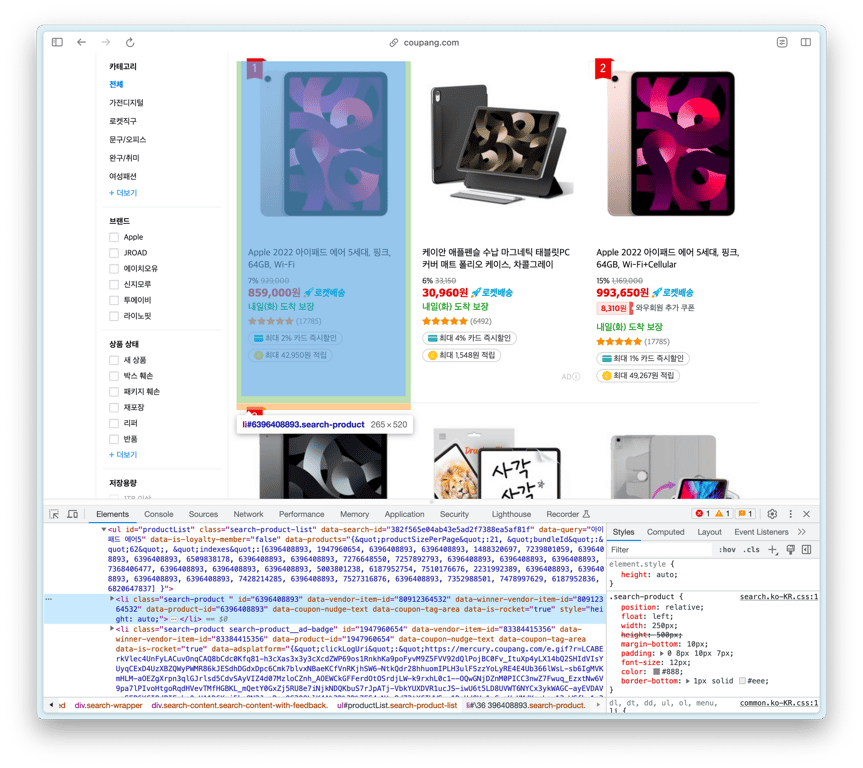
El ul con id productList es la lista de productos, y dentro de él, cada li es un elemento de producto.
Entonces, ¿por qué no copiamos este HTML ul y preguntamos a ChatGPT?
1.3. Reducción del tamaño del HTML

ChatGPT tiene un límite de tokens, por lo que no puede manejar HTML tan grande como el ul anterior.
Debemos reducir el tamaño del HTML, así que copiemos el primer li del ul y preguntemos de nuevo.
1.4. Consideraciones para la solicitud
Antes de escribir la solicitud, vamos a organizar qué debemos tener en cuenta.
1⃣ Repetir para todos los **li** en la lista de productos
Recopile todos los productos dentro de //ul[@id="productList"].
2⃣ Eliminar productos publicitarios
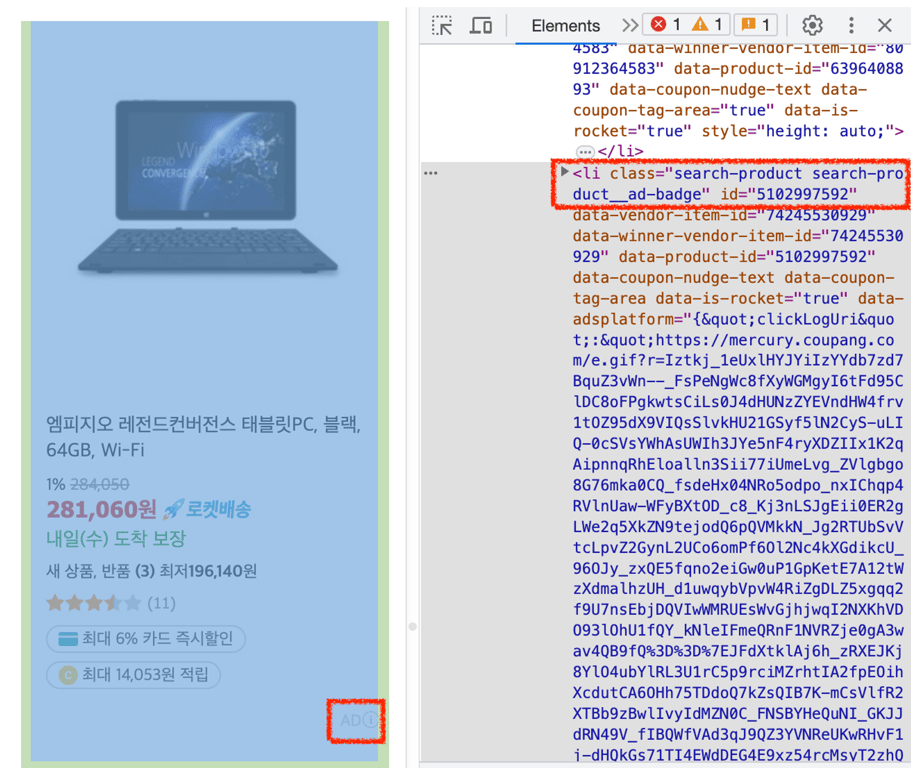
Si la clase contiene search-product__ad-badge, es un producto publicitario y no debe recopilarse.
1.5. Escribir la solicitud a ChatGPT
Se utilizó GPT-4 y se ingresó la solicitud de la siguiente manera.
<<li의 HTML>>
상품 정보를 담고 있는 위의 HTML에서 상품 이름, 가격, 정가, 별점, 리뷰 개수, 카드 할인, 적립 정보, 배송 정보를 가져오는 웹 크롤러를 셀레니움을 사용하여 만들어 줘.
이 li 요소는 "//ul[@id='productList']" 안에 있으므로, 상품 리스트를 가져와 그 안의 li 태그에 대해 수집 작업을 반복하도록 코드를 생성해 줘.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
수집 내용을 콘솔에 출력할 때 각 상품마다 서로 구별될 수 있도록 구분선을 추가해 줘.
1.6. Resultado del código de ChatGPT
## import 및 크롬 드라이버 설정 생략 ##
# 웹페이지 열기
driver.get('<https://www.coupang.com/np/search?component=&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&channel=auto>')
# 상품 리스트 가져오기
product_list = driver.find_element(By.XPATH, "//ul[@id='productList']")
# BeautifulSoup으로 파싱
soup = BeautifulSoup(product_list.get_attribute('outerHTML'), 'html.parser')
# 광고 상품 제외하고 각 상품 정보 가져오기
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
product_name = product.find("div", class_="name").text.strip()
original_price = product.find("del", class_="base-price").text.strip()
sale_price = product.find("strong", class_="price-value").text.strip()
rating = product.find("em", class_="rating").text.strip()
review_count = product.find("span", class_="rating-total-count").text.strip()
card_discount = product.find("span", class_="ccid-txt").text.strip() if product.find("span", class_="ccid-txt") else "N/A"
reward_info = product.find("span", class_="reward-cash-txt").text.strip() if product.find("span", class_="reward-cash-txt") else "N/A"
delivery_info = product.find("span", class_="arrival-info").text.strip()
# 콘솔에 출력
print('-'*40)
print("상품 이름:", product_name)
print("정가:", original_price)
print("판매 가격:", sale_price)
print("별점:", rating)
print("리뷰 개수:", review_count)
print("카드 할인 정보:", card_discount)
print("적립 정보:", reward_info)
print("배송 정보:", delivery_info)
driver.quit()
2. Depuración
Cuando ejecutamos el código generado por ChatGPT, es probable que no se ejecute correctamente.
En este caso, nos encontramos con el siguiente error de inmediato:
Traceback (most recent call last):
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 13, in <module>
AttributeError: 'NoneType' object has no attribute 'text'
Ahora vamos a mostrar el proceso de depuración.
2.1. AttributeError: 'NoneType' object has no attribute 'text'
Situación del problema
Verifiquemos el código que obtiene el nombre del producto.
product_name = product.find("div", class_="name").text.strip()
Este código obtiene el texto del elemento que contiene el nombre del producto.
Sin embargo, si no se encuentra un div con la clase "name", product.find("div", class_="name") se convierte en un objeto 'NoneType'.
Como no se puede obtener texto de None, se produce el error AttributeError.
Solución al error
Intentemos resolverlo dividiendo los casos.
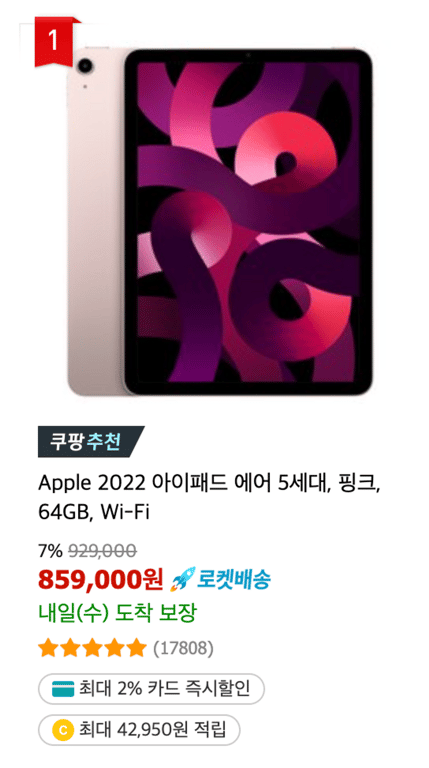
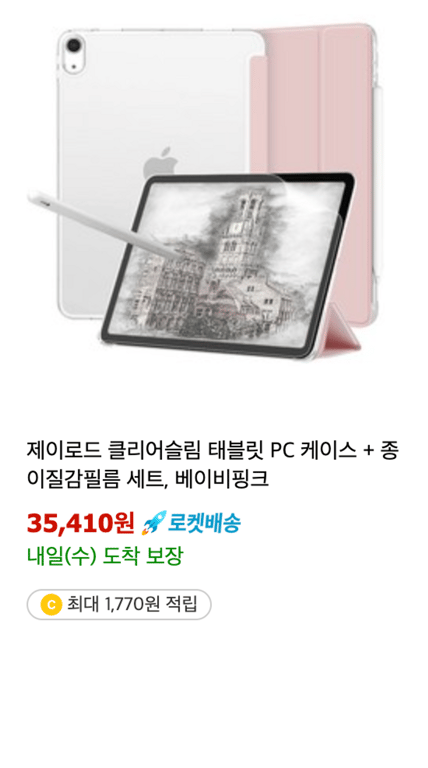
Como se puede ver en las imágenes, la cantidad de información varía para cada producto.
Por lo tanto, queremos dividir la información en dos tipos.
Información obligatoria
Cosas como el nombre del producto y el precio deben existir obligatoriamente y no pueden ser None.
Si alguno de estos es None, debe generar un error.
try:
# 요소를 찾음
product_name = product.find("div", class_="name").text.strip()
except AttributeError:
# 에러 발생 시 raise
raise AttributeError("상품 이름을 가져오는 중 에러가 발생했습니다.")
Información opcional
Para información que puede faltar, como el número de reseñas, se necesita un manejo diferente.
Si no se encuentra el elemento que contiene la información, asignaremos None a la variable.
# 요소를 찾음
review_count_span = product.find("span", class_="rating-total-count")
# 요소가 None이라면 변수에 None 할당
review_count = review_count_span.text.strip() if review_count_span else None
También se puede escribir en una sola línea:
review_count_span = product.find("span", class_="rating-total-count").text.strip() if product.find("span", class_="rating-total-count") else None
2.2. Saltar productos publicitarios
La solicitud incluía esta información.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
Basándose en esto, ChatGPT generó el siguiente código:
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
# ...후략
Situación del problema
En el código anterior, si encuentra un elemento con la clase 'search-product__ad-badge', lo salta.
El problema es que está buscando esta clase dentro de los elementos internos de product.
Probablemente esto se deba a un error en mi solicitud, pero intentemos solucionarlo.
Solución
if 'search-product__ad-badge' in product['class']:
continue
Cambiamos la condición de salto en el bucle para que verifique si la clase 'search-product__ad-badge' está presente en la clase de product.
2.3. Ajuste de URL incompleto
Al ejecutar el bot de web scraping, obtuvimos las URL de los productos de la siguiente manera.
상품 URL: /vp/products/6396408893?itemId=13659935611&vendorItemId=80912364532&pickType=COU_PICK&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=c12ac6801b8042dbbe20f91a2e875bc0&rank=1
Problema
Cuando analizamos HTML con BeautifulSoup para recopilar información, es posible que la propiedad href no muestre la URL completa.
Al comparar la URL anterior con la URL real, podemos ver que falta https://www.coupang.com/ al principio.
Solución
Agreguemos la parte inicial de la URL.
product_url = "https://www.coupang.com" + product.find('a', class_='search-product-link')['href']
3. Verificación de los resultados de recopilación
Echemos un vistazo a los datos recopilados con el bot de web scraping modificado.
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/6396408893?itemId=13659935634&vendorItemId=80912364549&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=e5fbb32250614118b4a65b814ec1b9ae&rank=10>
상품 이름: Apple 2022 아이패드 에어 5세대, 스타라이트, 256GB, Wi-Fi
정가: 1,169,000
판매 가격: 1,098,860
별점: 5.0
리뷰 개수: (17833)
카드 할인 정보: 최대 1% 카드 즉시할인
적립 정보: 최대 50,000원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/1947960654?itemId=5913484902&vendorItemId=83384415356&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 케이안 애플펜슬 수납 마그네틱 태블릿PC 커버 매트 폴리오 케이스, 차콜그레이
정가: 33,150
판매 가격: 30,960
별점: 5.0
리뷰 개수: (6498)
카드 할인 정보: 최대 4% 카드 즉시할인
적립 정보: 최대 1,548원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/5540742883?itemId=8726176862&vendorItemId=79466342181&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 신지모루 애플펜슬 수납 아이패드 클리어 케이스 + 강화유리 2P, 웜그레이
정가: 26,900
판매 가격: 25,900
별점: 5.0
리뷰 개수: (1313)
카드 할인 정보: 최대 2% 카드 즉시할인
적립 정보: 최대 1,295원 적립
배송 정보: 내일(목) 도착 보장
Aunque es una estructura simple de bot de web scraping que recopila solo los productos mostrados en los resultados de búsqueda, ¡podemos obtener bastante información!
4. Conclusión
Hasta ahora, hemos examinado el proceso de web scraping de los resultados de búsqueda de Coupang utilizando ChatGPT. ChatGPT es una herramienta muy útil, pero requirió un poco de depuración y ajustes. Aun así, pudimos obtener resultados bastante útiles.
Sin embargo, para recopilar los resultados de búsqueda de Coupang de manera efectiva, se deben considerar varias cosas. Coupang detecta y bloquea rápidamente la presencia de bots, por lo que se necesitan soluciones eficientes para evitar esto, y para recopilar información que varía según si se ha iniciado sesión, se requieren trabajos adicionales. Estas limitaciones complican el trabajo de web scraping y pueden dificultar la recopilación precisa y rápida de información.
Para resolver estos problemas de manera efectiva, se necesitan herramientas y servicios especializados. HashScraper proporciona un servicio profesional de web scraping que puede resolver estos problemas complejos. Puede recopilar fácilmente una amplia variedad de información de Coupang de manera fluida y rápida.
En este post, exploramos cómo desarrollar un web crawler a través de ChatGPT. Aunque hay varias herramientas y métodos disponibles, si desea una recopilación de información eficiente y precisa, se recomienda utilizar un servicio profesional.
Gracias.
También puedes leer este artículo:
Automatiza la recopilación de datos
Comienza en 5 minutos sin necesidad de programación · Experiencia en web scraping de más de 5,000 sitios web



