

0. 概述
如今,由于ChatGPT,开发变得非常容易。
如果与ChatGPT一起,爬虫机器人也能轻松创建吗?
让我们开始开发一个Coupang爬虫机器人(带ChatGPT)。
1. 编写提示
1.1. 目标
希望从搜索结果中提取每个产品的基本信息。
产品名称
原价
销售价
评分
评论数量
卡片折扣信息
积分信息
配送信息
1.2. 查找产品列表HTML
让我们找到包含产品列表的HTML元素
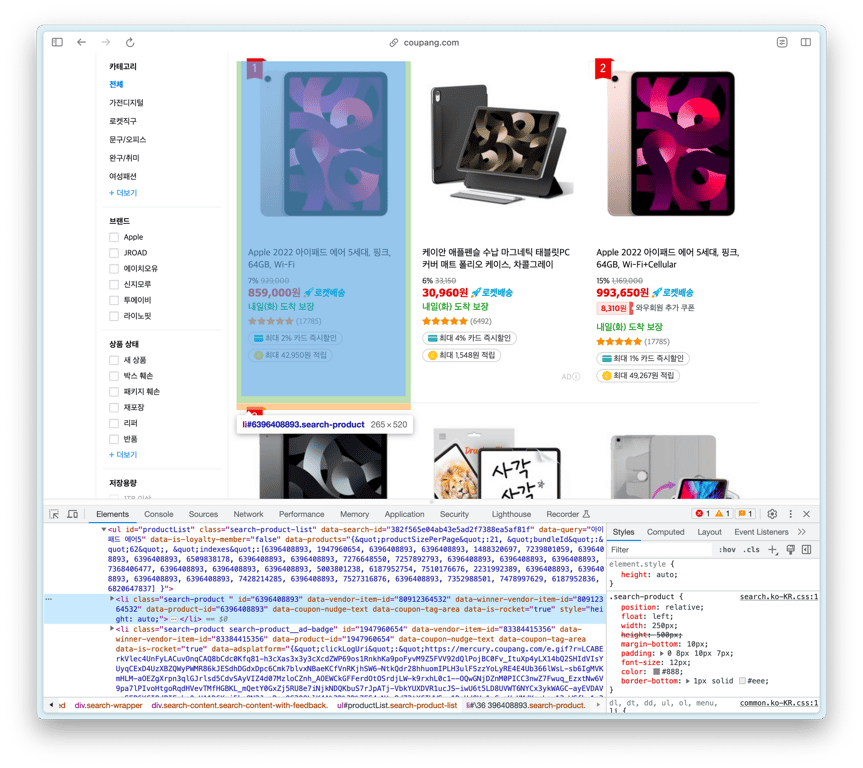
id为productList的ul是产品列表,其中的每个li是产品元素。
那么,我们复制上面的ul HTML并询问ChatGPT吧?
1.3. 缩小HTML大小

由于ChatGPT有令牌数限制,无法处理像上面的ul这么大的HTML。
我们需要缩小HTML的大小,因此复制ul的第一个li HTML并再次询问。
1.4. 考虑提示的要点
在编写提示之前,让我们总结一下需要考虑的事项。
1⃣ 对产品列表中的所有 **li**进行循环
收集//ul[@id="productList"]中的所有产品。
2⃣ 删除广告产品
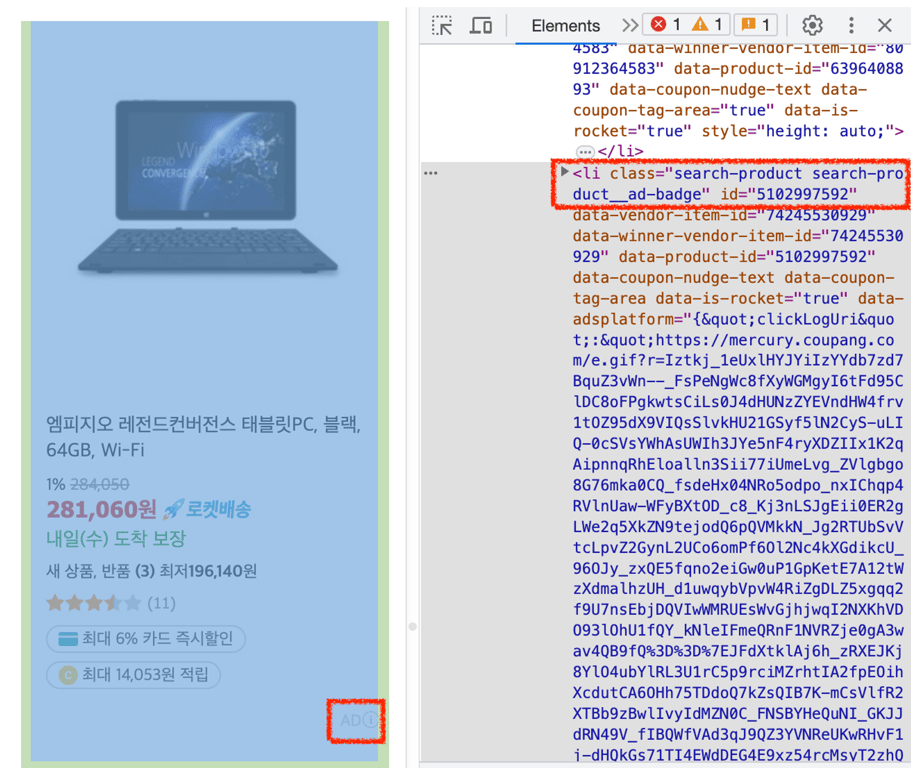
如果类中包含search-product__ad-badge,则表示是广告产品,不应收集该产品。
1.5. 编写ChatGPT提示
我们使用了GPT-4,并输入了以下提示。
<<li의 HTML>>
상품 정보를 담고 있는 위의 HTML에서 상품 이름, 가격, 정가, 별점, 리뷰 개수, 카드 할인, 적립 정보, 배송 정보를 가져오는 웹 크롤러를 셀레니움을 사용하여 만들어 줘.
이 li 요소는 "//ul[@id='productList']" 안에 있으므로, 상품 리스트를 가져와 그 안의 li 태그에 대해 수집 작업을 반복하도록 코드를 생성해 줘.
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
수집 내용을 콘솔에 출력할 때 각 상품마다 서로 구별될 수 있도록 구분선을 추가해 줘.
1.6. ChatGPT编码结果
## import 및 크롬 드라이버 설정 생략 ##
# 웹페이지 열기
driver.get('<https://www.coupang.com/np/search?component=&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&channel=auto>')
# 상품 리스트 가져오기
product_list = driver.find_element(By.XPATH, "//ul[@id='productList']")
# BeautifulSoup으로 파싱
soup = BeautifulSoup(product_list.get_attribute('outerHTML'), 'html.parser')
# 광고 상품 제외하고 각 상품 정보 가져오기
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
product_name = product.find("div", class_="name").text.strip()
original_price = product.find("del", class_="base-price").text.strip()
sale_price = product.find("strong", class_="price-value").text.strip()
rating = product.find("em", class_="rating").text.strip()
review_count = product.find("span", class_="rating-total-count").text.strip()
card_discount = product.find("span", class_="ccid-txt").text.strip() if product.find("span", class_="ccid-txt") else "N/A"
reward_info = product.find("span", class_="reward-cash-txt").text.strip() if product.find("span", class_="reward-cash-txt") else "N/A"
delivery_info = product.find("span", class_="arrival-info").text.strip()
# 콘솔에 출력
print('-'*40)
print("상품 이름:", product_name)
print("정가:", original_price)
print("판매 가격:", sale_price)
print("별점:", rating)
print("리뷰 개수:", review_count)
print("카드 할인 정보:", card_discount)
print("적립 정보:", reward_info)
print("배송 정보:", delivery_info)
driver.quit()
2. 调试
如果运行ChatGPT生成的代码,很可能无法正常运行。
就像这个例子一样,我们立即遇到了以下错误:
Traceback (most recent call last):
File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode
coro = func()
File "<input>", line 13, in <module>
AttributeError: 'NoneType' object has no attribute 'text'
现在让我们看一下调试过程。
2.1. AttributeError: 'NoneType' object has no attribute 'text'
问题
查看提取产品名称的代码。
product_name = product.find("div", class_="name").text.strip()
这是用于查找具有产品名称的元素并提取文本的代码。
但是,如果找不到类为"name"的div,product.find("div", class_="name")将变为'NoneType'对象。
由于无法从None中提取文本,因此会发生AttributeError。
解决
让我们分情况解决。
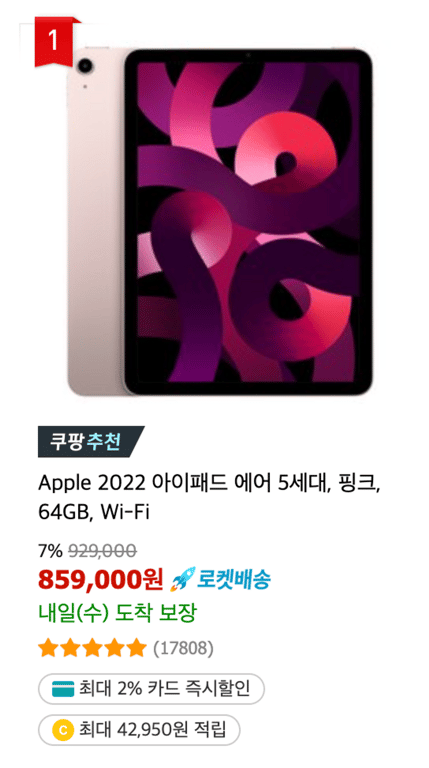
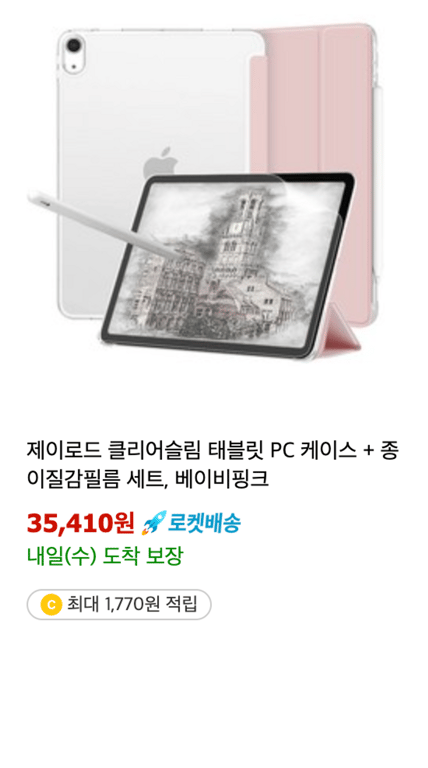
如上图所示,每个产品的信息量可能不同。
因此,我们打算将信息分为两类。
必需信息
产品名称、价格等必须存在的信息不能是None。
如果是这种情况,应该引发错误。
try:
# 요소를 찾음
product_name = product.find("div", class_="name").text.strip()
except AttributeError:
# 에러 발생 시 raise
raise AttributeError("상품 이름을 가져오는 중 에러가 발생했습니다.")
可选信息
对于像评论数量这样可选的信息,需要进行其他处理。
如果找不到包含信息的元素,则将变量分配为None。
# 요소를 찾음
review_count_span = product.find("span", class_="rating-total-count")
# 요소가 None이라면 변수에 None 할당
review_count = review_count_span.text.strip() if review_count_span else None
也可以这样写成一行:
review_count_span = product.find("span", class_="rating-total-count").text.strip() if product.find("span", class_="rating-total-count") else None
2.2. 跳过广告产品
提示中包含以下内容。
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
ChatGPT生成了以下代码:
for product in soup.find_all('li', class_='search-product'):
# 광고 상품인 경우 스킵
if product.find(class_='search-product__ad-badge'):
continue
# ...후략
问题
在上面的代码中,如果找到类为'search-product__ad-badge'的元素,将跳过。
问题在于这是在product的内部元素中查找该类。
这可能是因为我没有准确编写提示导致的问题,但让我们尝试解决一下。
解决
if 'search-product__ad-badge' in product['class']:
continue
我们已经修改了循环中跳过条件,使其在product的类中包含'search-product__ad-badge'。
2.3. 调整不完整的URL
运行爬虫机器人后,我们获得了以下产品URL。
상품 URL: /vp/products/6396408893?itemId=13659935611&vendorItemId=80912364532&pickType=COU_PICK&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=c12ac6801b8042dbbe20f91a2e875bc0&rank=1
问题
在使用BeautifulSoup解析HTML并收集数据时,href属性中可能不会完全显示URL。
通过比较上面的URL和实际URL,我们可以看到前面缺少了https://www.coupang.com/。
解决
让我们添加URL的前缀。
product_url = "https://www.coupang.com" + product.find('a', class_='search-product-link')['href']
3. 检查收集结果
让我们查看经过修改的爬虫机器人收集的数据。
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/6396408893?itemId=13659935634&vendorItemId=80912364549&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=e5fbb32250614118b4a65b814ec1b9ae&rank=10>
상품 이름: Apple 2022 아이패드 에어 5세대, 스타라이트, 256GB, Wi-Fi
정가: 1,169,000
판매 가격: 1,098,860
별점: 5.0
리뷰 개수: (17833)
카드 할인 정보: 최대 1% 카드 즉시할인
적립 정보: 최대 50,000원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/1947960654?itemId=5913484902&vendorItemId=83384415356&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 케이안 애플펜슬 수납 마그네틱 태블릿PC 커버 매트 폴리오 케이스, 차콜그레이
정가: 33,150
판매 가격: 30,960
별점: 5.0
리뷰 개수: (6498)
카드 할인 정보: 최대 4% 카드 즉시할인
적립 정보: 최대 1,548원 적립
배송 정보: 내일(목) 도착 보장
----------------------------------------
상품 URL: <https://www.coupang.com//vp/products/5540742883?itemId=8726176862&vendorItemId=79466342181&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5
상품 이름: 신지모루 애플펜슬 수납 아이패드 클리어 케이스 + 강화유리 2P, 웜그레이
정가: 26,900
판매 가격: 25,900
별점: 5.0
리뷰 개수: (1313)
카드 할인 정보: 최대 2% 카드 즉시할인
적립 정보: 최대 1,295원 적립
배송 정보: 내일(목) 도착 보장
尽管这是一个简单的收集仅显示在搜索结果中的产品的爬虫机器人,但我们可以获得相当多的信息!
4. 结论
到目前为止,我们通过ChatGPT查看了爬取Coupang搜索结果的过程。ChatGPT是一个非常有用的工具,但需要一些调试和修改。尽管如此,我们仍然可以获得相当有用的结果。
然而,要顺利地收集Coupang搜索结果,需要考虑许多因素。由于Coupang能够快速检测和阻止机器人,因此需要有效地规避这一点,并且如果要收集根据登录状态而变化的信息,则需要进行额外的工作。这些限制会使爬取工作变得复杂,从而给准确和快速的信息收集带来困难。
要有效解决这些问题,需要专业的工具和服务。Hashscraper提供专业的网络爬虫服务,可以解决这些复杂的问题。您可以轻松快速地收集Coupang的各种信息。
通过本文,我们了解了如何使用ChatGPT开发网络爬虫。虽然有许多工具和方法,但如果希望实现高效和准确的信息收集,建议使用专业服务。
谢谢。
也可以阅读这篇文章:
数据收集,现在自动化
开始无需编码,5分钟内开始·超过5,000个网站的爬取经验



