X(트위터) 광고 수익 조건 달성을 위한 트윗 자동화 - 1편
X(트위터)에서 광고 수익을 올리기 위한 전략과 자동화 프로세스를 소개합니다. 트래픽 증가, impressions 달성, 주제 선정 등의 개요를 다룹니다.

XPath는 웹 크롤링의 기초로서, XML 문서의 특정 요소 또는 속성에 접근하는 강력한 도구입니다. 이 포스팅에서는 XPath의 기본 문법과 활용 예제를 다룹니다.
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>hashscraper</title> </head> <body> <div id="container"> <div class="title"> <p class="content1">let's start crawling!</p> <p class="content2">crawling is fun!</p> </div> </div> </body> </html>
/html/head/title
/html/body/div/div/p[@class='content1']
html/body/div/div/p[@class='content1']
//p[@class='content1']
#'aa'를 포함하는 class명을 가진 div 요소를 선택 //div[contains(@class, "aa")]
//div[@class="aa")/span[last()]
#class명에 'aa'와 'bb'를 포함하는 img 요소를 선택 //img[contains(@class, "aa") and contains(@class, "bb")]
#class명에 'aa' 또는 'bb'를 포함하는 img 요소를 선택 //img[contains(@class, "aa") or contains(@class, "bb")]
#class명에 'aa'를 포함하고 'bb'를 포함하지 않는 img 요소를 선택 //img[contains(@class, "aa") and not(contains(@class, "bb")
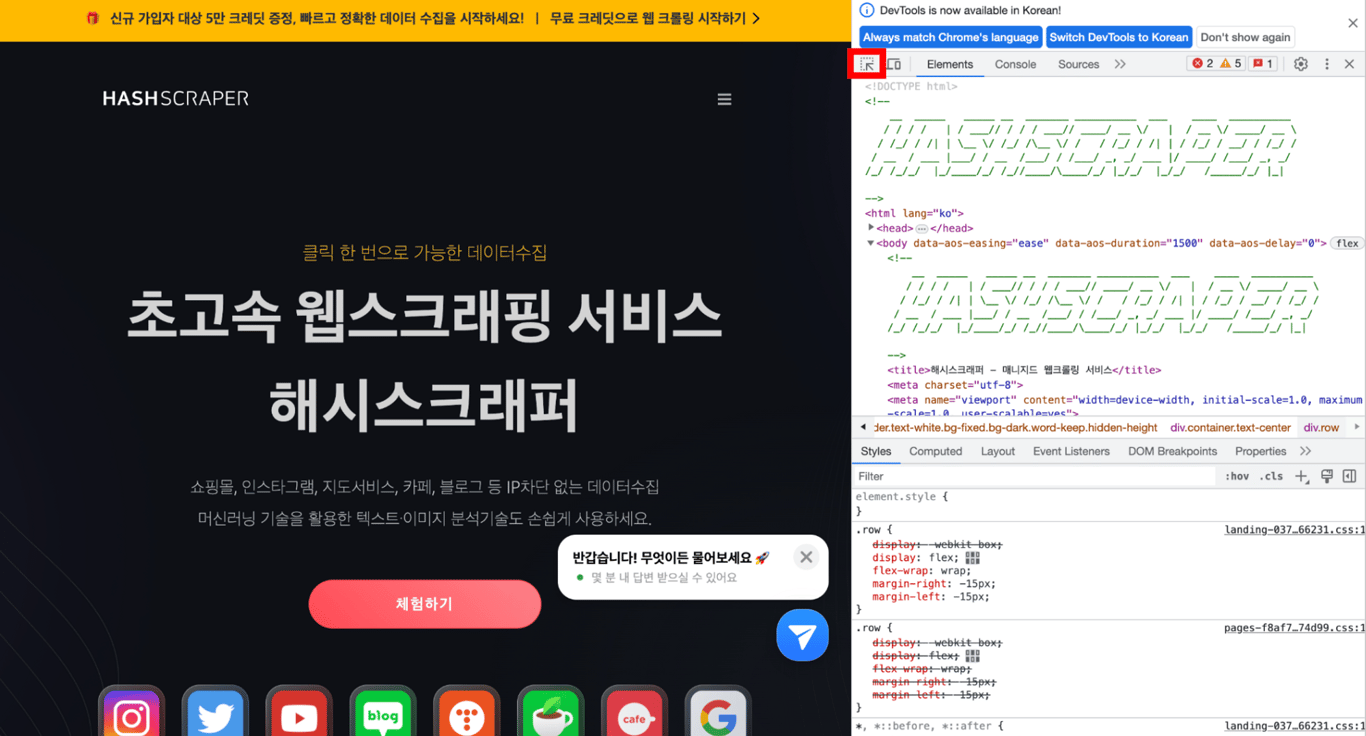
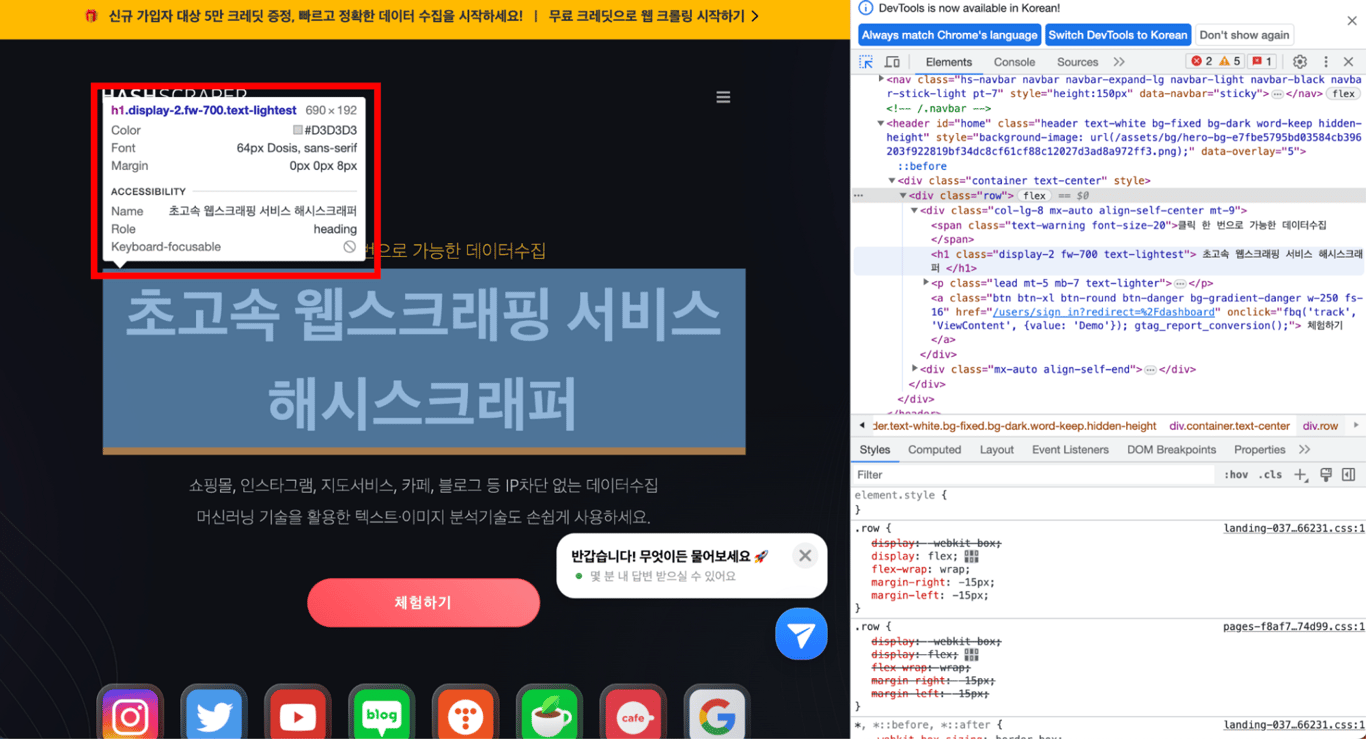
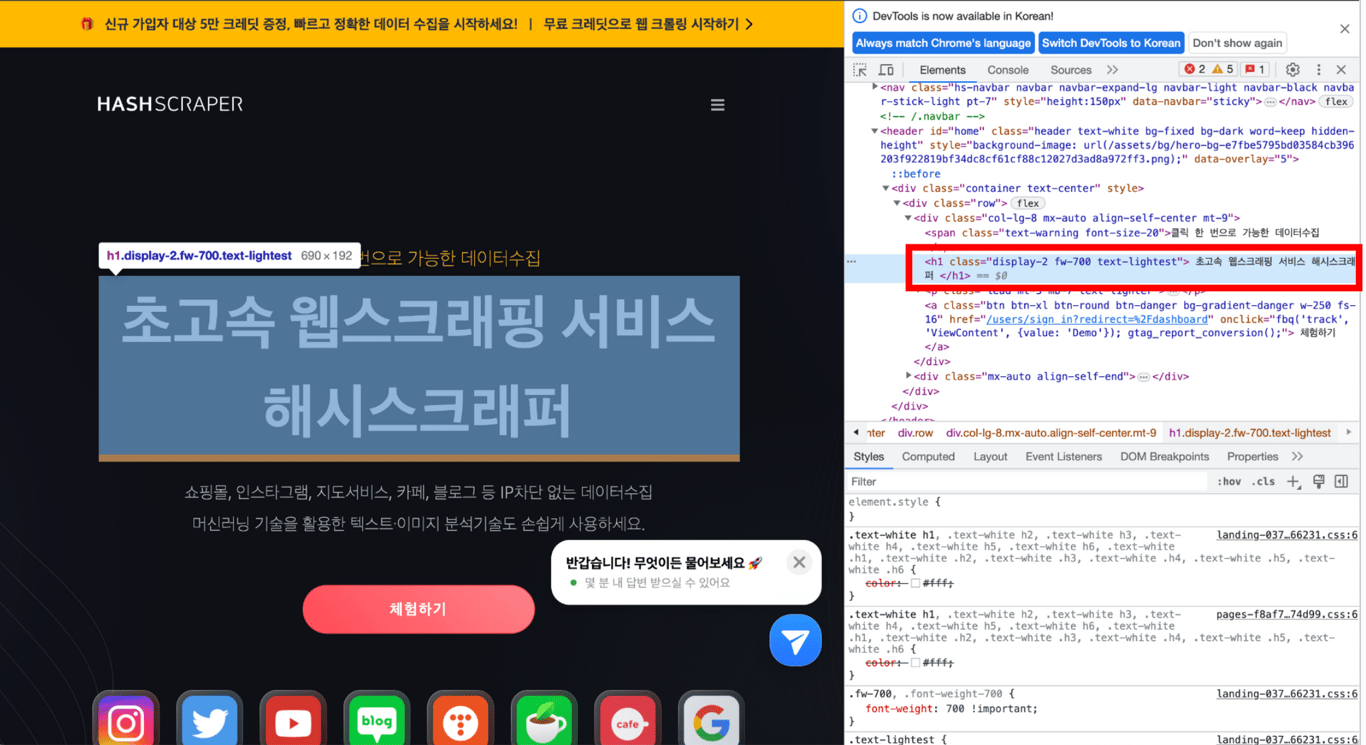
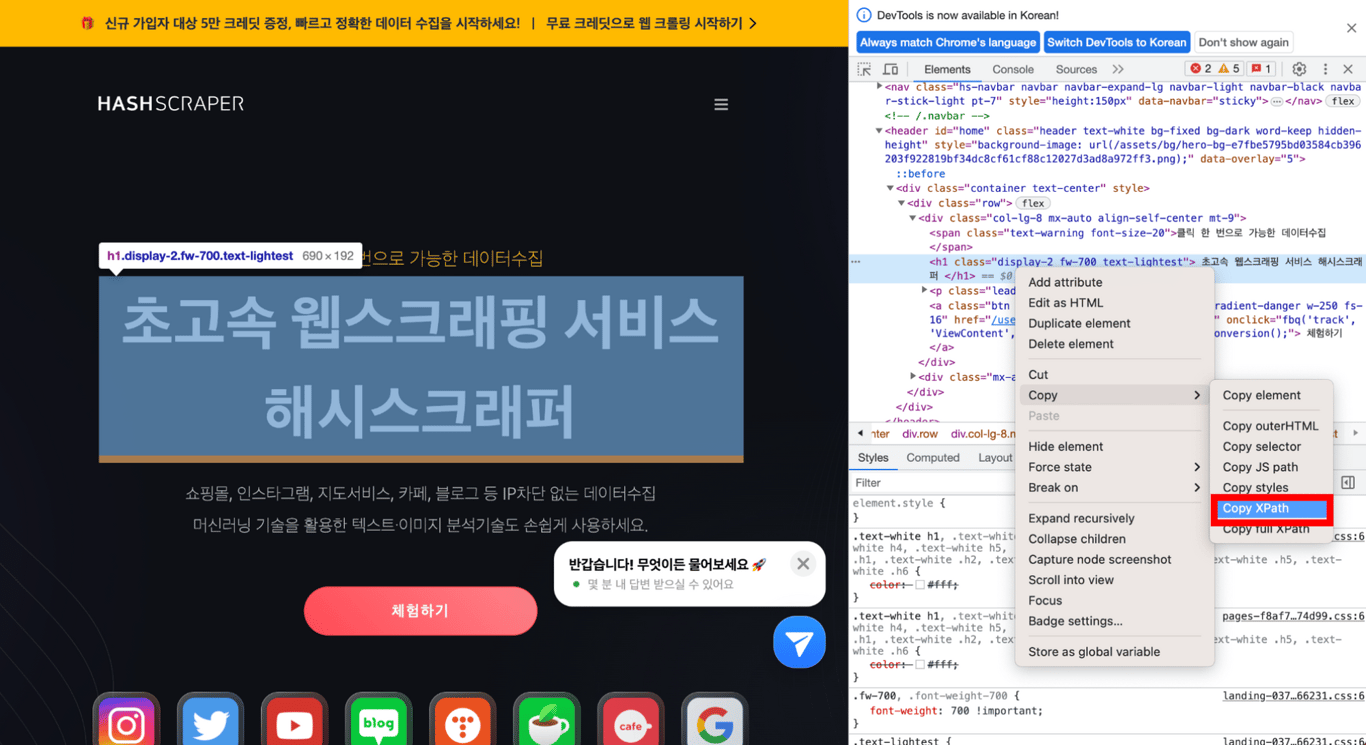
//*[@id="home"]/div/div/div[1]/h1
get_browser.goto "<https://www.hashscraper.com>" x = get_browser.element(xpath: "//*[@id='home']/div/div/div[1]/h1").text


X(트위터)에서 광고 수익을 올리기 위한 전략과 자동화 프로세스를 소개합니다. 트래픽 증가, impressions 달성, 주제 선정 등의 개요를 다룹니다.


Claude를 활용하여 ChatGPT에 크림(Kream)의 HTML을 입력하고, 이를 기반으로 실시간 차트를 크롤링하는 방법을 알아보세요.