X(트위터) 광고 수익 조건 달성을 위한 트윗 자동화 - 1편
X(트위터)에서 광고 수익을 올리기 위한 전략과 자동화 프로세스를 소개합니다. 트래픽 증가, impressions 달성, 주제 선정 등의 개요를 다룹니다.

ChatGPT와 함께 시작하는 쿠팡 크롤러 봇 개발! 검색 결과에 노출된 상품 정보를 가져오기 위한 프롬프트 작성과 디버깅 과정을 단계별로 설명합니다. 프롬프트 고려 사항부터 광고 상품 제외, URL 조작까지 자세한 코드 예시와 함께 알려드립니다.
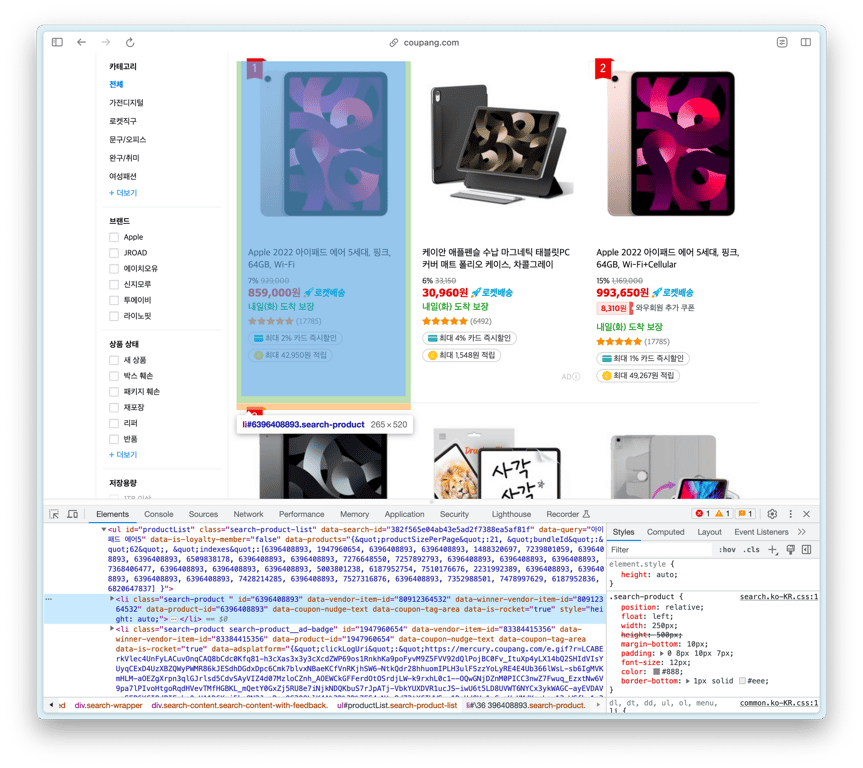
productList인 ul이 상품 리스트이며, 그 안에 있는 각각의 li가 상품 요소인 것을 볼 수 있습니다.ul HTML을 복사해서 ChatGPT에 물어볼까요?
ul과 같이 너무 큰 HTML은 처리할 수가 없습니다.
HTML의 크기를 줄여야 하므로 ul의 첫 번째 li HTML을 복사해 다시 물어보겠습니다.li에 대하여 반복//ul[@id="productList"] 안에 있는 모든 상품들을 수집하도록 합니다.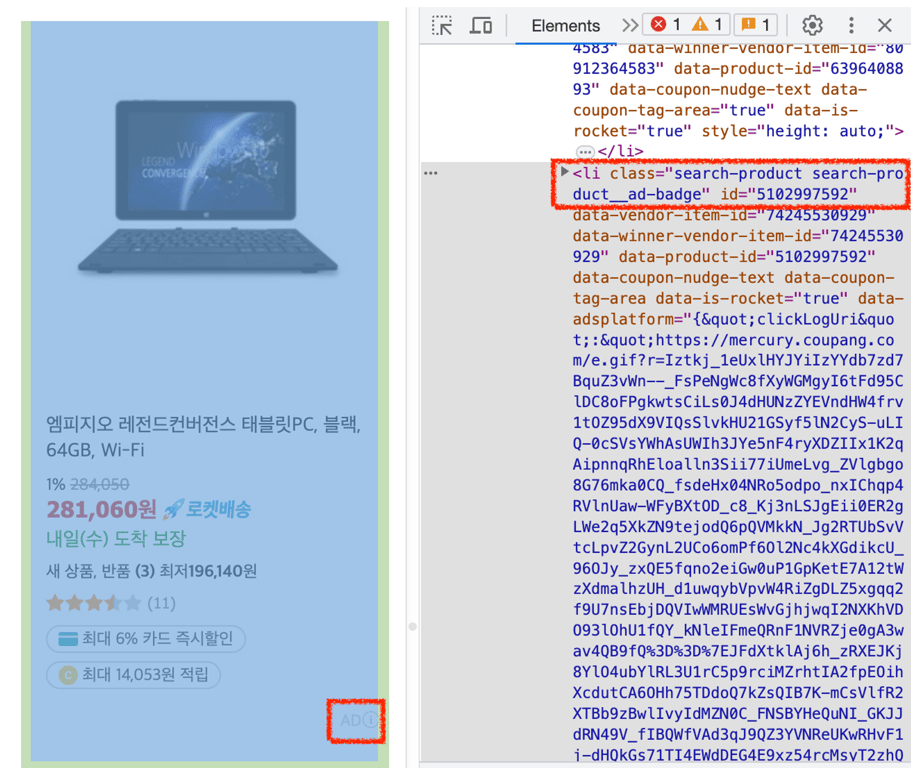
search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품까지 수집되지 않도록 합니다.<<li의 HTML>> 상품 정보를 담고 있는 위의 HTML에서 상품 이름, 가격, 정가, 별점, 리뷰 개수, 카드 할인, 적립 정보, 배송 정보를 가져오는 웹 크롤러를 셀레니움을 사용하여 만들어 줘. 이 li 요소는 "//ul[@id='productList']" 안에 있으므로, 상품 리스트를 가져와 그 안의 li 태그에 대해 수집 작업을 반복하도록 코드를 생성해 줘. class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해. 수집 내용을 콘솔에 출력할 때 각 상품마다 서로 구별될 수 있도록 구분선을 추가해 줘.
## import 및 크롬 드라이버 설정 생략 ## # 웹페이지 열기 driver.get('<https://www.coupang.com/np/search?component=&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&channel=auto>') # 상품 리스트 가져오기 product_list = driver.find_element(By.XPATH, "//ul[@id='productList']") # BeautifulSoup으로 파싱 soup = BeautifulSoup(product_list.get_attribute('outerHTML'), 'html.parser') # 광고 상품 제외하고 각 상품 정보 가져오기 for product in soup.find_all('li', class_='search-product'): # 광고 상품인 경우 스킵 if product.find(class_='search-product__ad-badge'): continue product_name = product.find("div", class_="name").text.strip() original_price = product.find("del", class_="base-price").text.strip() sale_price = product.find("strong", class_="price-value").text.strip() rating = product.find("em", class_="rating").text.strip() review_count = product.find("span", class_="rating-total-count").text.strip() card_discount = product.find("span", class_="ccid-txt").text.strip() if product.find("span", class_="ccid-txt") else "N/A" reward_info = product.find("span", class_="reward-cash-txt").text.strip() if product.find("span", class_="reward-cash-txt") else "N/A" delivery_info = product.find("span", class_="arrival-info").text.strip() # 콘솔에 출력 print('-'*40) print("상품 이름:", product_name) print("정가:", original_price) print("판매 가격:", sale_price) print("별점:", rating) print("리뷰 개수:", review_count) print("카드 할인 정보:", card_discount) print("적립 정보:", reward_info) print("배송 정보:", delivery_info) driver.quit()
Traceback (most recent call last): File "/Applications/PyCharm.app/Contents/plugins/python/helpers/pydev/pydevconsole.py", line 364, in runcode coro = func() File "<input>", line 13, in <module> AttributeError: 'NoneType' object has no attribute 'text'
product_name = product.find("div", class_="name").text.strip()
"name"인 div를 찾지 못한다면 product.find("div", class_="name")는 'NoneType' object가 됩니다.
None에서는 텍스트를 가져올 수 없기 때문에 AttributeError가 발생하게 되는 것입니다.
None이어서는 안되겠죠.
이러한 것이 None이라면 에러를 발생시켜야 합니다.try: # 요소를 찾음 product_name = product.find("div", class_="name").text.strip() except AttributeError: # 에러 발생 시 raise raise AttributeError("상품 이름을 가져오는 중 에러가 발생했습니다.")
None을 할당하도록 하겠습니다.# 요소를 찾음 review_count_span = product.find("span", class_="rating-total-count") # 요소가 None이라면 변수에 None 할당 review_count = review_count_span.text.strip() if review_count_span else None
review_count_span = product.find("span", class_="rating-total-count").text.strip() if product.find("span", class_="rating-total-count") else None
class에 search-product__ad-badge가 포함되어 있는 경우 광고 상품이므로 해당 상품은 스킵해.
for product in soup.find_all('li', class_='search-product'): # 광고 상품인 경우 스킵 if product.find(class_='search-product__ad-badge'): continue # ...후략
'search-product__ad-badge'인 요소를 찾게되면 스킵하도록 되어 있습니다.
해당 클래스를 product의 클래스에서 찾아야 하는데,
문제는 이것을 product 내부 요소에서 찾는다는 것입니다.
아마 이것은 제가 프롬프트를 정확하게 작성하지 않아 발생한 문제인 것 같지만, 해결해보도록 하겠습니다.if 'search-product__ad-badge' in product['class']: continue
product의 클래스에 'search-product__ad-badge'가 포함되어 있도록 수정했습니다.상품 URL: /vp/products/6396408893?itemId=13659935611&vendorItemId=80912364532&pickType=COU_PICK&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=c12ac6801b8042dbbe20f91a2e875bc0&rank=1
https://www.coupang.com/가 빠져 있음을 확인할 수 있습니다.product_url = "https://www.coupang.com" + product.find('a', class_='search-product-link')['href']
---------------------------------------- 상품 URL: <https://www.coupang.com//vp/products/6396408893?itemId=13659935634&vendorItemId=80912364549&q=%EC%95%84%EC%9D%B4%ED%8C%A8%EB%93%9C+%EC%97%90%EC%96%B4+5&itemsCount=36&searchId=e5fbb32250614118b4a65b814ec1b9ae&rank=10> 상품 이름: Apple 2022 아이패드 에어 5세대, 스타라이트, 256GB, Wi-Fi 정가: 1,169,000 판매 가격: 1,098,860 별점: 5.0 리뷰 개수: (17833) 카드 할인 정보: 최대 1% 카드 즉시할인 적립 정보: 최대 50,000원 적립 배송 정보: 내일(목) 도착 보장 ---------------------------------------- 상품 URL: <https://www.coupang.com//vp/products/1947960654?itemId=5913484902&vendorItemId=83384415356&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5 상품 이름: 케이안 애플펜슬 수납 마그네틱 태블릿PC 커버 매트 폴리오 케이스, 차콜그레이 정가: 33,150 판매 가격: 30,960 별점: 5.0 리뷰 개수: (6498) 카드 할인 정보: 최대 4% 카드 즉시할인 적립 정보: 최대 1,548원 적립 배송 정보: 내일(목) 도착 보장 ---------------------------------------- 상품 URL: <https://www.coupang.com//vp/products/5540742883?itemId=8726176862&vendorItemId=79466342181&sourceType=SDW_TOP_SELLING_WIDGET_V2&searchId=e5fbb32250614118b4a65b814ec1b9ae&q=아이패드> 에어 5 상품 이름: 신지모루 애플펜슬 수납 아이패드 클리어 케이스 + 강화유리 2P, 웜그레이 정가: 26,900 판매 가격: 25,900 별점: 5.0 리뷰 개수: (1313) 카드 할인 정보: 최대 2% 카드 즉시할인 적립 정보: 최대 1,295원 적립 배송 정보: 내일(목) 도착 보장


X(트위터)에서 광고 수익을 올리기 위한 전략과 자동화 프로세스를 소개합니다. 트래픽 증가, impressions 달성, 주제 선정 등의 개요를 다룹니다.


Claude를 활용하여 ChatGPT에 크림(Kream)의 HTML을 입력하고, 이를 기반으로 실시간 차트를 크롤링하는 방법을 알아보세요.